Ten Years of AI in Overview
Picture by the Creator.
The final decade has been an exciting and eventful experience for the sphere of synthetic intelligence (AI). Modest explorations of the potential of deep studying changed into an explosive proliferation of a subject that now consists of all the pieces from recommender methods in e-commerce to object detection for autonomous automobiles and generative fashions that may create all the pieces from sensible pictures to coherent textual content.
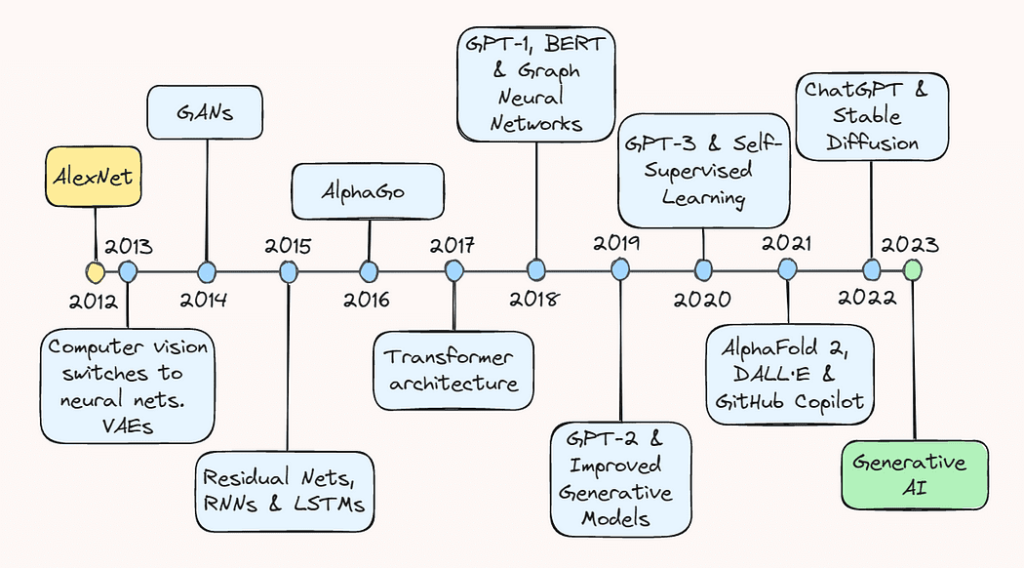
On this article, we’ll take a stroll down reminiscence lane and revisit a number of the key breakthroughs that obtained us to the place we’re in the present day. Whether or not you’re a seasoned AI practitioner or just within the newest developments within the subject, this text will offer you a complete overview of the exceptional progress that led AI to develop into a family identify.
2013: AlexNet and Variational Autoencoders
The 12 months 2013 is broadly thought to be the “coming-of-age” of deep studying, initiated by main advances in laptop imaginative and prescient. Based on a latest interview of Geoffrey Hinton, by 2013 “just about all the pc imaginative and prescient analysis had switched to neural nets”. This increase was primarily fueled by a somewhat stunning breakthrough in picture recognition one 12 months earlier.
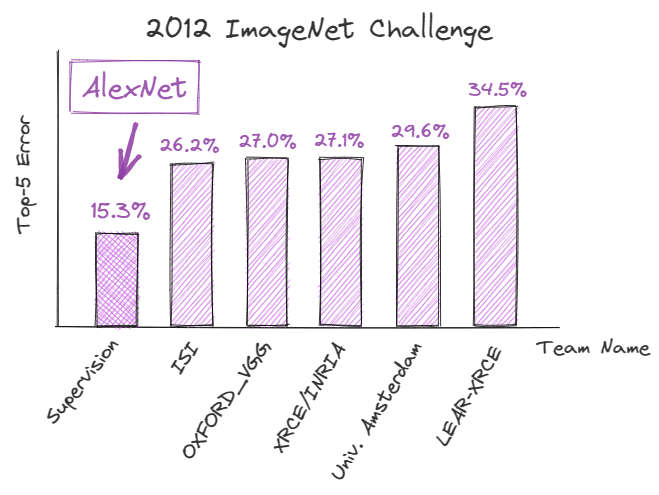
In September 2012, AlexNet, a deep convolutional neural community (CNN), pulled off a record-breaking efficiency within the ImageNet Massive Scale Visible Recognition Problem (ILSVRC), demonstrating the potential of deep studying for picture recognition duties. It achieved a top-5 error of 15.3%, which was 10.9% decrease than that of its nearest competitor.
Picture by the Creator.
The technical enhancements behind this success had been instrumental for the longer term trajectory of AI and dramatically modified the way in which deep studying was perceived.
First, the authors utilized a deep CNN consisting of 5 convolutional layers and three fully-connected linear layers — an architectural design dismissed by many as impractical on the time. Furthermore, as a result of giant variety of parameters produced by the community’s depth, coaching was completed in parallel on two graphics processing items (GPUs), demonstrating the flexibility to considerably speed up coaching on giant datasets. Coaching time was additional lowered by swapping conventional activation capabilities, corresponding to sigmoid and tanh, for the extra environment friendly rectified linear unit (ReLU).
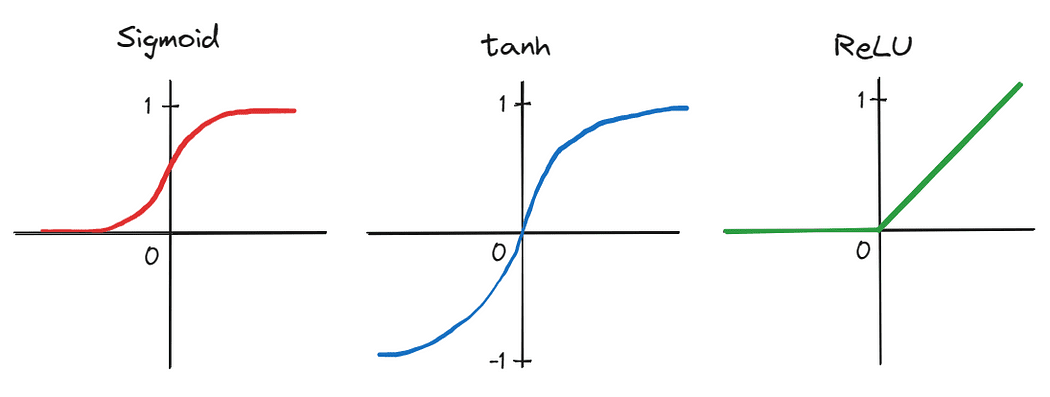
Picture by the Creator.
These advances that collectively led to the success of AlexNet marked a turning level within the historical past of AI and sparked a surge of curiosity in deep studying amongst each teachers and the tech group. Consequently, 2013 is taken into account by many because the inflection level after which deep studying really started to take off.
Additionally occurring in 2013, albeit slightly drowned out by the noise of AlexNet, was the event of variational autoencoders, or VAEs — generative fashions that may study to characterize and generate knowledge corresponding to pictures and sounds. They work by studying a compressed illustration of the enter knowledge in a lower-dimensional area, generally known as latent area. This permits them to generate new knowledge by sampling from this realized latent area. VAEs, afterward, turned out to open up new avenues for generative modeling and knowledge technology, with purposes in fields like artwork, design, and gaming.
2014: Generative Adversarial Networks
The next 12 months, in June 2014, the sphere of deep studying witnessed one other severe advance with the introduction of generative adversarial networks, or GANs, by Ian Goodfellow and colleagues.
GANs are a sort of neural community able to producing new knowledge samples which might be much like a coaching set. Primarily, two networks are skilled concurrently: (1) a generator community generates faux, or artificial, samples, and (2) a discriminator community evaluates their authenticity. This coaching is carried out in a game-like setup, with the generator attempting to create samples that idiot the discriminator, and the discriminator attempting to accurately name out the faux samples.
At the moment, GANs represented a robust and novel instrument for knowledge technology, getting used not just for producing pictures and movies, but additionally music and artwork. Additionally they contributed to the advance of unsupervised studying, a website largely thought to be underdeveloped and difficult, by demonstrating the likelihood to generate high-quality knowledge samples with out counting on specific labels.
2015: ResNets and NLP Breakthroughs
In 2015, the sphere of AI made appreciable advances in each laptop imaginative and prescient and pure language processing, or NLP.
Kaiming He and colleagues revealed a paper titled “Deep Residual Studying for Picture Recognition”, through which they launched the idea of residual neural networks, or ResNets — architectures that permit data to move extra simply by the community by including shortcuts. In contrast to in a daily neural community, the place every layer takes the output of the earlier layer as enter, in a ResNet, further residual connections are added that skip a number of layers and straight connect with deeper layers within the community.
Consequently, ResNets had been capable of clear up the issue of vanishing gradients, which enabled the coaching of a lot deeper neural networks past what was regarded as doable on the time. This, in flip, led to vital enhancements in picture classification and object recognition duties.
At across the identical time, researchers made appreciable progress with the event of recurrent neural networks (RNNs) and lengthy short-term reminiscence (LSTM) fashions. Regardless of having been round because the Nineteen Nineties, these fashions solely began to generate some buzz round 2015, primarily on account of components corresponding to (1) the provision of bigger and extra various datasets for coaching, (2) enhancements in computational energy and {hardware}, which enabled the coaching of deeper and extra advanced fashions, and (3) modifications made alongside the way in which, corresponding to extra subtle gating mechanisms.
Consequently, these architectures made it doable for language fashions to higher perceive the context and which means of textual content, resulting in huge enhancements in duties corresponding to language translation, textual content technology, and sentiment evaluation. The success of RNNs and LSTMs round that point paved the way in which for the event of enormous language fashions (LLMs) we see in the present day.
2016: AlphaGo
After Garry Kasparov’s defeat by IBM’s Deep Blue in 1997, one other human vs. machine battle despatched shockwaves by the gaming world in 2016: Google’s AlphaGo defeated the world champion of Go, Lee Sedol.

Picture by Elena Popova on Unsplash.
Sedol’s defeat marked one other main milestone within the trajectory of AI development: it demonstrated that machines might outsmart even essentially the most expert human gamers in a recreation that was as soon as thought of too advanced for computer systems to deal with. Utilizing a mixture of deep reinforcement learning and Monte Carlo tree search, AlphaGo analyzes tens of millions of positions from earlier video games and evaluates the absolute best strikes — a method that far surpasses human resolution making on this context.
2017: Transformer Structure and Language Fashions
Arguably, 2017 was essentially the most pivotal 12 months that laid the muse for the breakthroughs in generative AI that we’re witnessing in the present day.
In December 2017, Vaswani and colleagues launched the foundational paper “Consideration is all you want”, which launched the transformer structure that leverages the idea of self-attention to course of sequential enter knowledge. This allowed for extra environment friendly processing of long-range dependencies, which had beforehand been a problem for conventional RNN architectures.

Picture by Jeffery Ho on Unsplash.
Transformers are comprised of two important elements: encoders and decoders. The encoder is chargeable for encoding the enter knowledge, which, for instance, could be a sequence of phrases. It then takes the enter sequence and applies a number of layers of self-attention and feed-forward neural nets to seize the relationships and options throughout the sentence and study significant representations.
Primarily, self-attention permits the mannequin to grasp relationships between totally different phrases in a sentence. In contrast to conventional fashions, which might course of phrases in a set order, transformers really study all of the phrases without delay. They assign one thing known as consideration scores to every phrase primarily based on its relevance to different phrases within the sentence.
The decoder, alternatively, takes the encoded illustration from the encoder and produces an output sequence. In duties corresponding to machine translation or textual content technology, the decoder generates the translated sequence primarily based on the enter acquired from the encoder. Much like the encoder, the decoder additionally consists of a number of layers of self-attention and feed-forward neural nets. Nevertheless, it consists of a further consideration mechanism that allows it to give attention to the encoder’s output. This then permits the decoder to bear in mind related data from the enter sequence whereas producing the output.
The transformer structure has since develop into a key part within the growth of LLMs and has led to vital enhancements throughout the area of NLP, corresponding to machine translation, language modeling, and query answering.
2018: GPT-1, BERT and Graph Neural Networks
Just a few months after Vaswani et al. revealed their foundational paper, the Generative Pretrained Transformer, or GPT-1, was launched by OpenAI in June 2018, which utilized the transformer structure to successfully seize long-range dependencies in textual content. GPT-1 was one of many first fashions to display the effectiveness of unsupervised pre-training adopted by fine-tuning on particular NLP duties.
Additionally making the most of the nonetheless fairly novel transformer structure was Google, who, in late 2018, launched and open-sourced their very own pre-training methodology known as Bidirectional Encoder Representations from Transformers, or BERT. In contrast to earlier fashions that course of textual content in a unidirectional method (together with GPT-1), BERT considers the context of every phrase in each instructions concurrently. As an example this, the authors present a really intuitive instance:
… within the sentence “I accessed the checking account”, a unidirectional contextual mannequin would characterize “financial institution” primarily based on “I accessed the” however not “account”. Nevertheless, BERT represents “financial institution” utilizing each its earlier and subsequent context — “I accessed the … account” — ranging from the very backside of a deep neural community, making it deeply bidirectional.
The idea of bidirectionality was so highly effective that it led BERT to outperform state-of-the-art NLP methods on a wide range of benchmark duties.
Other than GPT-1 and BERT, graph neural networks, or GNNs, additionally made some noise that 12 months. They belong to a class of neural networks which might be particularly designed to work with graph knowledge. GNNs make the most of a message passing algorithm to propagate data throughout the nodes and edges of a graph. This permits the community to study the construction and relationships of the information in a way more intuitive approach.
This work allowed for the extraction of a lot deeper insights from knowledge and, consequently, broadened the vary of issues that deep studying could possibly be utilized to. With GNNs, main advances had been made doable in areas like social community evaluation, suggestion methods, and drug discovery.
2019: GPT-2 and Improved Generative Fashions
The 12 months 2019 marked a number of notable developments in generative fashions, significantly the introduction of GPT-2. This mannequin actually left its friends within the mud by attaining state-of-the-art efficiency in lots of NLP duties and, as well as, was succesful to generate extremely sensible textual content, which, in hindsight, gave us a teaser of what was about to come back on this area.
Different enhancements on this area included DeepMind’s BigGAN, which generated high-quality pictures that had been nearly indistinguishable from actual pictures, and NVIDIA’s StyleGAN, which allowed for higher management over the looks of these generated pictures.
Collectively, these developments in what’s now generally known as generative AI pushed the boundaries of this area even additional, and…
2020: GPT-3 and Self-Supervised Studying
… not quickly thereafter, one other mannequin was born, which has develop into a family identify even outdoors of the tech group: GPT-3. This mannequin represented a significant leap ahead within the scale and capabilities of LLMs. To place issues into context, GPT-1 sported a measly 117 million parameters. That quantity went as much as 1.5 billion for GPT-2, and 175 billion for GPT-3.
This huge quantity of parameter area permits GPT-3 to generate remarkably coherent textual content throughout a variety of prompts and duties. It additionally demonstrated spectacular efficiency in a wide range of NLP duties, corresponding to textual content completion, query answering, and even artistic writing.
Furthermore, GPT-3 highlighted once more the potential of utilizing self-supervised studying, which permits fashions to be skilled on giant quantities of unlabeled knowledge. This has the benefit that these fashions can purchase a broad understanding of language with out the necessity for in depth task-specific coaching, which makes it much more economical.
Yann LeCun tweets about an NYT article on self-supervised studying.
2021: AlphaFold 2, DALL·E and GitHub Copilot
From protein folding to picture technology and automatic coding help, the 12 months of 2021 was an eventful one due to the releases of AlphaFold 2, DALL·E, and GitHub Copilot.
AlphaFold 2 was hailed as a long-awaited resolution to the decades-old protein folding downside. DeepMind’s researchers prolonged the transformer structure to create evoformer blocks — architectures that leverage evolutionary methods for mannequin optimization — to construct a mannequin able to predicting a protein’s 3D construction primarily based on its 1D amino acid sequence. This breakthrough has monumental potential to revolutionize areas like drug discovery, bioengineering, in addition to our understanding of organic methods.
OpenAI additionally made it within the information once more this 12 months with their launch of DALL·E. Primarily, this mannequin combines the ideas of GPT-style language fashions and picture technology to allow the creation of high-quality pictures from textual descriptions.
As an example how highly effective this mannequin is, think about the picture under, which was generated with the immediate “Oil portray of a futuristic world with flying vehicles”.

Picture produced by DALL·E.
Lastly, GitHub launched what would later develop into each builders greatest buddy: Copilot. This was achieved in collaboration with OpenAI, which offered the underlying language mannequin, Codex, that was skilled on a big corpus of publicly accessible code and, in flip, realized to grasp and generate code in varied programming languages. Builders can use Copilot by merely offering a code remark stating the issue they’re attempting to resolve, and the mannequin would then recommend code to implement the answer. Different options embrace the flexibility to explain enter code in pure language and translate code between programming languages.
2022: ChatGPT and Secure Diffusion
The speedy growth of AI over the previous decade has culminated in a groundbreaking development: OpenAI’s ChatGPT, a chatbot that was launched into the wild in November 2022. The instrument represents a cutting-edge achievement in NLP, able to producing coherent and contextually related responses to a variety of queries and prompts. Moreover, it may well interact in conversations, present explanations, supply artistic strategies, help with problem-solving, write and clarify code, and even simulate totally different personalities or writing kinds.

Picture by the Creator.
The straightforward and intuitive interface by which one can work together with the bot additionally stimulated a pointy rise in usability. Beforehand, it was largely the tech group that may mess around with the most recent AI-based innovations. Nevertheless, lately, AI instruments have penetrated nearly each skilled area, from software program engineers to writers, musicians, and advertisers. Many corporations are additionally utilizing the mannequin to automate companies corresponding to buyer assist, language translation, or answering FAQs. In reality, the wave of automation we’re seeing has rekindled some worries and stimulated discussions on which jobs is likely to be liable to being automated.
Though ChatGPT was taking over a lot of the limelight in 2022, there was additionally a major development made in picture technology. Stable diffusion, a latent text-to-image diffusion mannequin able to producing photo-realistic pictures from textual content descriptions, was launched by Stability AI.
Secure diffusion is an extension of the standard diffusion fashions, which work by iteratively including noise to pictures after which reversing the method to get well the information. It was designed to hurry up this course of by working in a roundabout way on the enter pictures, however as an alternative on a lower-dimensional illustration, or latent area, of them. As well as, the diffusion course of is modified by including the transformer-embedded textual content immediate from the person to the community, permitting it to information the picture technology course of all through every iteration.
Total, the discharge of each ChatGPT and Secure Diffusion in 2022 highlighted the potential of multimodal, generative AI and sparked an enormous enhance of additional growth and funding on this space.
2023: LLMs and Bots
The present 12 months has undoubtedly emerged because the 12 months of LLMs and chatbots. Increasingly more fashions are being developed and launched at a quickly growing tempo.
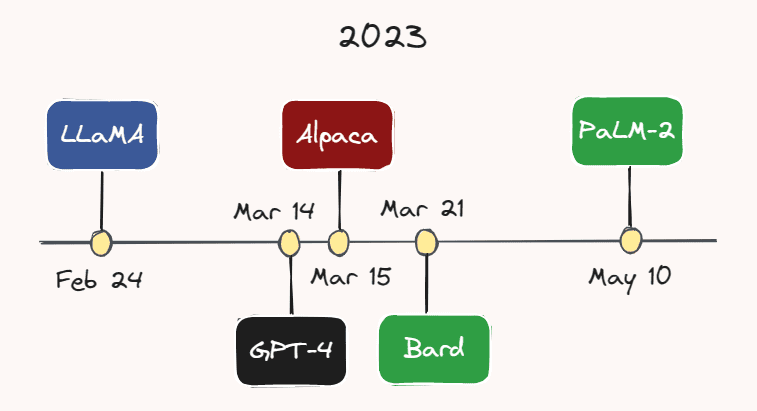
Picture by the Creator.
As an illustration, on February twenty fourth, Meta AI launched LLaMA — an LLM that outperforms GPT-3 on most benchmarks, regardless of having a significantly smaller variety of parameters. Lower than a month later, on March 14th, OpenAI launched GPT-4 — an even bigger, extra succesful, and multimodal model of GPT-3. Whereas the precise variety of parameters of GPT-4 is unknown, it’s alleged to be within the trillions.
On March 15, researchers at Stanford College launched Alpaca, a lightweight language mannequin that was fine-tuned from LLaMA on instruction-following demonstrations. A pair days later, on March twenty first, Google launched its ChatGPT rival: Bard. Google additionally simply launched its newest LLM, PaLM-2, earlier this month on Could tenth. With the relentless tempo of growth on this space, it’s extremely possible that one more mannequin could have emerged by the point you’re studying this.
We’re additionally seeing increasingly corporations incorporating these fashions into their merchandise. For instance, Duolingo introduced its GPT-4-powered Duolingo Max, a brand new subscription tier with the goal of offering tailor-made language classes to every particular person. Slack has additionally rolled out an AI-powered assistant known as Slack GPT, which may do issues like draft replies or summarize threads. Moreover, Shopify launched a ChatGPT-powered assistant to the corporate’s Store app, which will help prospects determine desired merchandise utilizing a wide range of prompts.
Shopify asserting its ChatGPT-powered assistant on Twitter.
Curiously, AI chatbots are these days even thought of as an alternative choice to human therapists. For instance, Replika, a US chatbot app, is providing customers an “AI companion who cares, at all times right here to pay attention and discuss, at all times in your facet”. Its founder, Eugenia Kuyda, says that the app has all kinds of consumers, starting from autistic kids, who flip to it as a option to “heat up earlier than human interactions”, to lonely adults who merely are within the want of a buddy.
Earlier than we conclude, I’d like to spotlight what could be the climax of the final decade of AI growth: persons are really utilizing Bing! Earlier this 12 months, Microsoft introduced its GPT-4-powered “copilot for the online” that has been custom-made for search and, for the primary time in… without end (?), has emerged as a severe contender to Google’s long-standing dominance within the search enterprise.
Wanting again and looking out ahead
As we mirror on the final ten years of AI growth, it turns into evident that we’ve got been witnessing a metamorphosis that has had profound influence on how we work, do enterprise, and work together with each other. A lot of the appreciable progress that has these days been achieved with generative fashions, significantly LLMs, appears to be adhering to the frequent perception that “greater is healthier”, referring to the parameter area of the fashions. This has been particularly noticeable with the GPT collection, which began out with 117 million parameters (GPT-1) and, after every successive mannequin growing by roughly an order of magnitude, culminated in GPT-4 with probably trillions of parameters.
Nevertheless, primarily based on a latest interview, OpenAI CEO Sam Altman believes that we’ve got reached the top of the “greater is healthier” period. Going ahead, he nonetheless thinks that the parameter rely will pattern up, however the principle focus of future mannequin enhancements might be on growing the mannequin’s functionality, utility, and security.
The latter is of explicit significance. Contemplating that these highly effective AI instruments at the moment are within the palms of most of the people and now not confined to the managed surroundings of analysis labs, it’s now extra important than ever that we tread with warning and be certain that these instruments are secure and align with humanity’s greatest pursuits. Hopefully we’ll see as a lot growth and funding in AI security as we’ve seen in different areas.
PS: In case I’ve missed a core AI idea or breakthrough that you just assume ought to have been included on this article, please let me know within the feedback under!
Thomas A Dorfer is a Information & Utilized Scientist at Microsoft. Previous to his present function, he labored as an information scientist within the biotech business and as a researcher within the area of neurofeedback. He holds a Grasp’s diploma in Integrative Neuroscience and, in his spare time, additionally writes technical weblog posts on Medium on the topics of information science, machine studying, and AI.
Original. Reposted with permission.