Analyze Amazon SageMaker spend and decide value optimization alternatives based mostly on utilization, Half 4: Coaching jobs

In 2021, we launched AWS Support Proactive Services as a part of the AWS Enterprise Support plan. Since its introduction, we’ve helped tons of of consumers optimize their workloads, set guardrails, and enhance the visibility of their machine studying (ML) workloads’ value and utilization.
On this collection of posts, we share classes realized about optimizing prices in Amazon SageMaker. On this publish, we deal with SageMaker coaching jobs.
SageMaker coaching jobs
SageMaker coaching jobs are asynchronous batch processes with built-in options for ML mannequin coaching and optimization.
With SageMaker coaching jobs, you possibly can carry your personal algorithm or select from greater than 25 built-in algorithms. SageMaker helps varied information sources and entry patterns, distributed coaching together with heterogenous clusters, in addition to experiment administration options and automated mannequin tuning.
The price of a coaching job relies on the sources you utilize (cases and storage) for the length (in seconds) that these cases are operating. This contains the time coaching takes place and, in case you’re utilizing the warm pool feature, the maintain alive interval you configure. In Part 1, we confirmed find out how to get began utilizing AWS Cost Explorer to establish value optimization alternatives in SageMaker. You possibly can filter coaching prices by making use of a filter on the utilization sort. The names of those utilization varieties are as follows:
REGION-Practice:instanceType(for instance,USE1-Practice:ml.m5.giant)REGION-Practice:VolumeUsage.gp2(for instance,USE1-Practice:VolumeUsage.gp2)
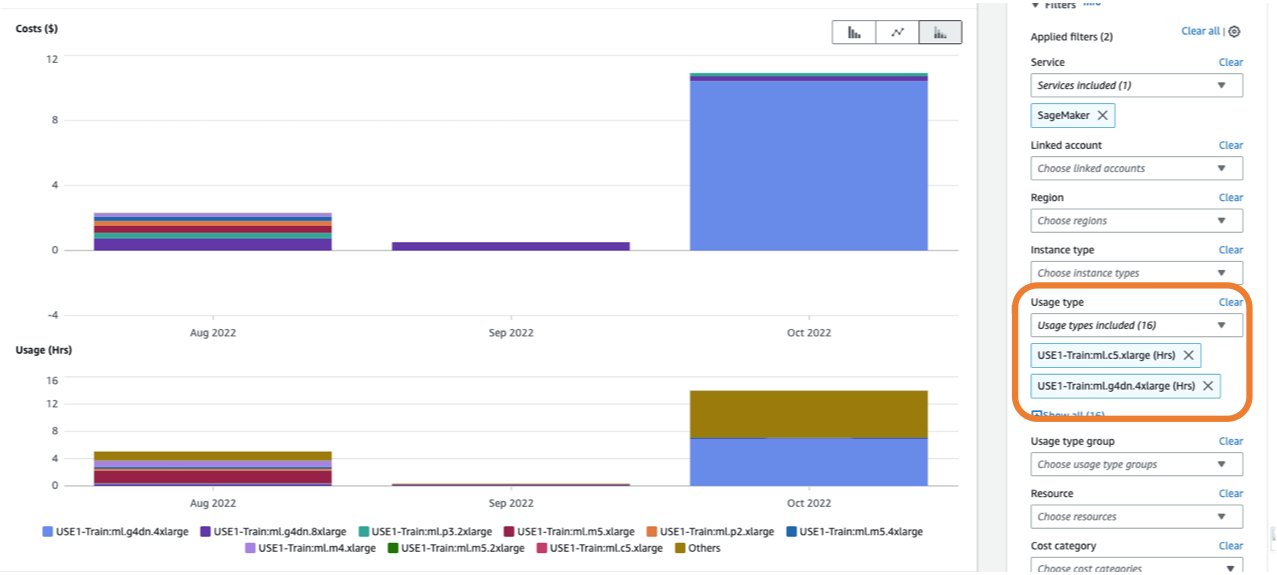
To view a breakdown of your coaching prices in Price Explorer, you possibly can enter prepare: as a prefix for Utilization sort. In case you filter just for hours used (see the next screenshot), Price Explorer will generate two graphs: Price and Utilization. This view will aid you prioritize your optimization alternatives and establish which cases are long-running and dear.
Earlier than optimizing an current coaching job, we suggest following the perfect practices lined in Optimizing costs for machine learning with Amazon SageMaker: take a look at your code domestically and use local mode for testing, use pre-trained fashions the place doable, and think about managed spot training (which might optimize value as much as 90% over On-Demand cases).
When an On-Demand job is launched, it goes via 5 phases: Beginning, Downloading, Coaching, Importing, and Accomplished. You possibly can see these phases and descriptions on the coaching job’s web page on the SageMaker console.
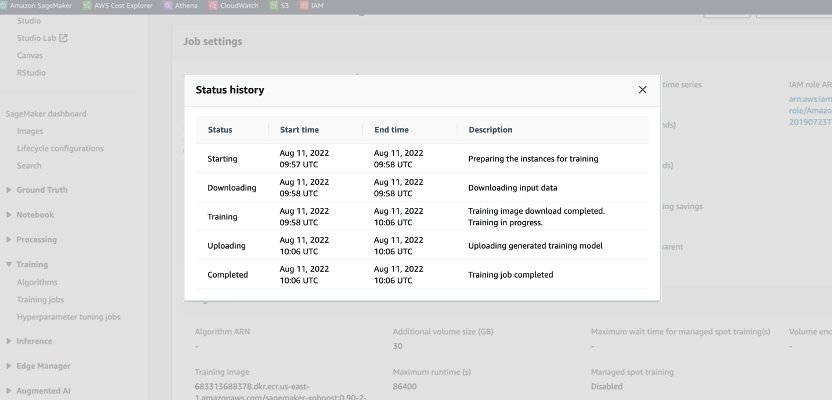
From a pricing perspective, you might be charged for Downloading, Coaching, and Importing phases.
Reviewing these phases is a primary step in diagnosing the place to optimize your coaching prices. On this publish, we talk about the Downloading and Coaching phases.
Downloading part
Within the previous instance, the Downloading part took lower than a minute. Nonetheless, if information downloading is an enormous issue of your coaching value, it’s best to think about the information supply you might be utilizing and entry strategies. SageMaker coaching jobs assist three information sources natively: Amazon Elastic File System (Amazon EFS), Amazon Simple Storage Service (Amazon S3), and Amazon FSx for Lustre. For Amazon S3, SageMaker presents three managed ways in which your algorithm can entry the coaching: File mode (the place information is downloaded to the occasion block storage), Pipe mode (information is streamed to the occasion, thereby eliminating the length of the Downloading part) and Quick File mode (combines the benefit of use of the prevailing File mode with the efficiency of Pipe mode). For detailed steering on choosing the proper information supply and entry strategies, check with Choose the best data source for your Amazon SageMaker training job.
When utilizing managed spot coaching, any repeated Downloading phases that occurred because of interruption aren’t charged (so that you’re solely charged in the course of the information obtain one time).
It’s necessary to notice that though SageMaker coaching jobs assist the information sources we talked about, they don’t seem to be obligatory. In your coaching code, you possibly can implement any technique for downloading the coaching information from any supply (offered that the coaching occasion can entry it). There are further methods to hurry up obtain time, corresponding to utilizing the Boto3 API with multiprocessing to obtain information concurrently, or utilizing third-party libraries corresponding to WebDataset or s5cmd for sooner obtain from Amazon S3. For extra data, check with Parallelizing S3 Workloads with s5cmd.
Coaching part
Optimizing the Coaching part value consists of optimizing two vectors: choosing the proper infrastructure (occasion household and dimension), and optimizing the coaching itself. We are able to roughly divide coaching cases into two classes: accelerated GPU-based, largely for deep-learning fashions, and CPU-based for frequent ML frameworks. For steering on deciding on the suitable occasion household for coaching, check with Ensure efficient compute resources on Amazon SageMaker. In case your coaching requires GPUs cases, we suggest referring to the video How to select Amazon EC2 GPU instances for deep learning.
As a normal steering, in case your workload does require an NVIDIA GPU, we discovered clients acquire vital value financial savings with two Amazon Elastic Compute Cloud (Amazon EC2) occasion varieties: ml.g4dn and ml.g5. The ml.g4dn is provided with NVIDIA T4 and presents a very low value per reminiscence. The ml.g5 occasion is provided with NVIDIA A10g Tensor Core and has the bottom cost-per-CUDA flop (fp32).
AWS presents particular value saving options for deep studying coaching:
As a way to right-size and optimize your occasion, it’s best to first take a look at the Amazon CloudWatch metrics the coaching jobs are producing. For extra data, check with SageMaker Jobs and Endpoint Metrics. You possibly can additional use CloudWatch custom algorithm metrics to monitor the training performance.
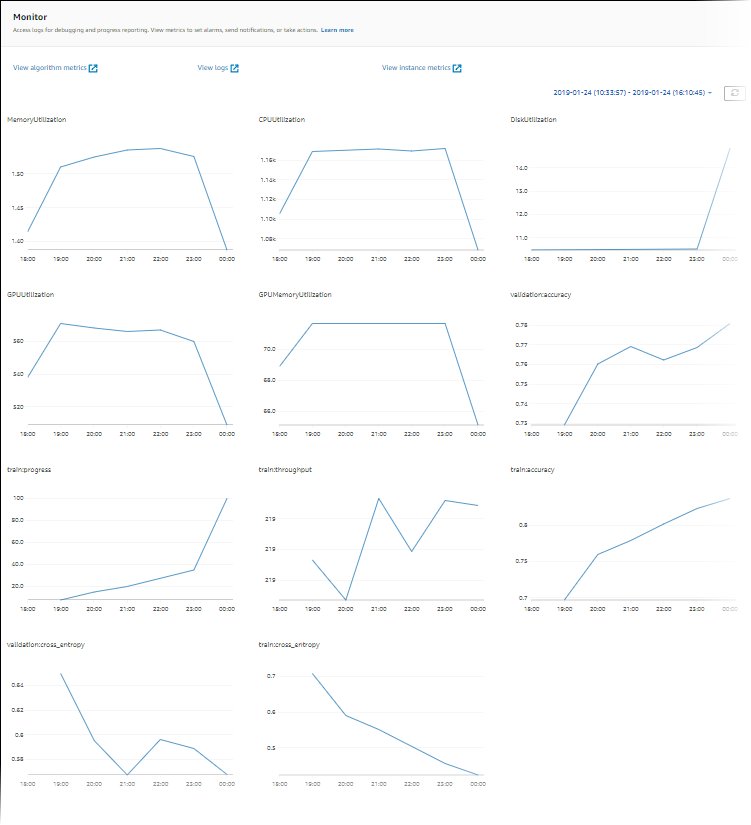
These metrics can point out bottlenecks or over-provisioning of sources. For instance, in case you’re observing excessive CPU with low GPU utilizations, you possibly can handle the difficulty through the use of heterogeneous clusters. One other instance may be seeing constant low CPU utilization all through the job length—this will result in decreasing the scale of the occasion.
In case you’re utilizing distributed training, it’s best to take a look at totally different distribution strategies (tower, Ring-AllReduce, mirrored, and so forth) to validate most utilization and fine-tune your framework parameters accordingly (for an instance, see Best practices for TensorFlow 1.x acceleration training on Amazon SageMaker). It’s necessary to focus on that you need to use the SageMaker distribution API and libraries like SageMaker Distributed Data Parallel, SageMaker Model Parallel, and SageMaker Sharded Data Parallel, that are optimized for AWS infrastructure and assist cut back coaching prices.
Observe that distributed coaching doesn’t essentially scale linearly and would possibly introduce some overhead, which can have an effect on the general runtime.
For deep studying fashions, one other optimization approach is utilizing blended precision. Blended precision can pace up coaching, thereby decreasing each coaching time and reminiscence utilization with minimal to no affect on mannequin accuracy. For extra data, see the Practice with Information Parallel and Mannequin Parallel part in Distributed Training in Amazon SageMaker.
Lastly, optimizing framework-specific parameters can have a major affect in optimizing the coaching course of. SageMaker automatic model tuning finds hyperparameters that carry out the perfect, as measured by an goal metric that you just select. Setting the coaching time as an goal metric and framework configuration as hyperparameters may also help take away bottlenecks and cut back total coaching time. For an instance of optimizing the default TensorFlow settings and eradicating a CPU bottleneck, check with Aerobotics improves training speed by 24 times per sample with Amazon SageMaker and TensorFlow.
One other alternative for optimizing each obtain and processing time is to think about coaching on a subset of your information. In case your information consists of a number of duplicate entries or options with low data acquire, you would possibly be capable to prepare on a subset of knowledge and cut back downloading and coaching time in addition to use a smaller occasion and Amazon Elastic Block Store (Amazon EBS) quantity. For an instance, check with Use a data-centric approach to minimize the amount of data required to train Amazon SageMaker models. Additionally, Amazon SageMaker Data Wrangler can simplify the evaluation and creation of coaching samples. For extra data, check with Create random and stratified samples of data with Amazon SageMaker Data Wrangler.
SageMaker Debugger
To make sure environment friendly coaching and useful resource utilization, SageMaker can profile your coaching job utilizing Amazon SageMaker Debugger. Debugger presents built-in rules to alert on frequent points which are affecting your coaching like CPU bottleneck, GPU reminiscence enhance, or I/O bottleneck, or you possibly can create your personal guidelines. You possibly can entry and analyze the generated report in Amazon SageMaker Studio. For extra data, check with Amazon SageMaker Debugger UI in Amazon SageMaker Studio Experiments. The next screenshot exhibits the Debugger view in Studio.
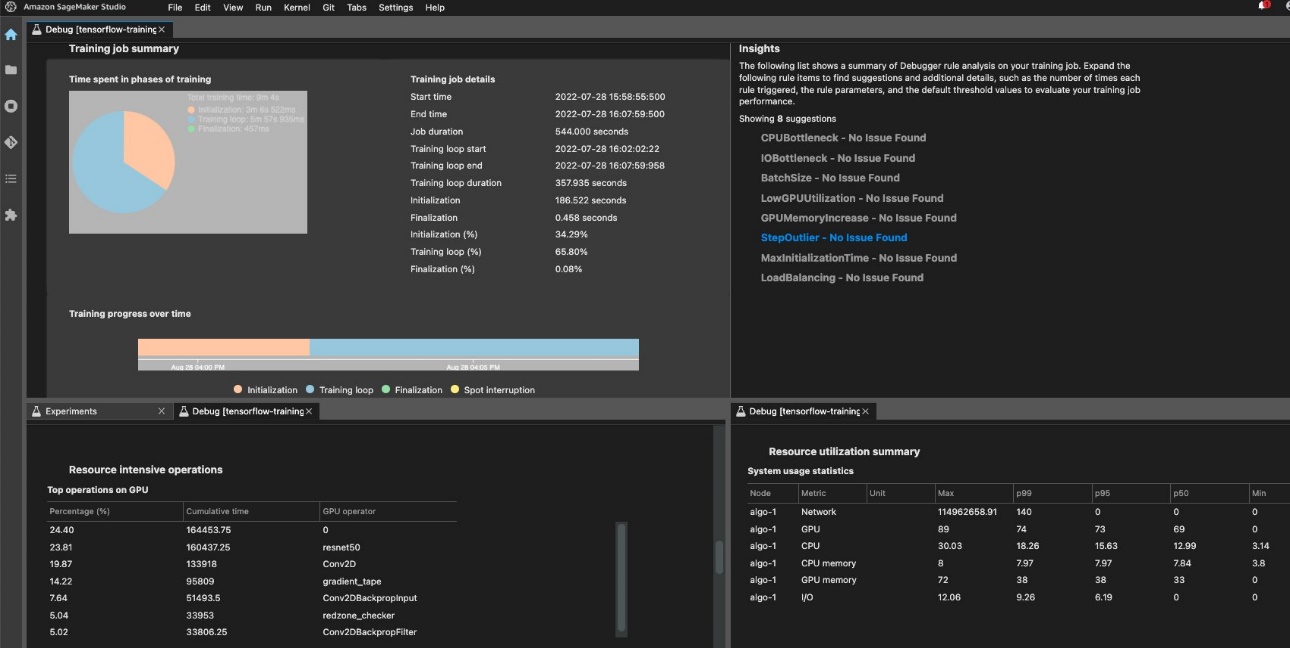
You possibly can drill down into the Python operators and features (the High operations on GPU part) which are run to carry out the coaching job. The Debugger built-in guidelines for profiling watch framework operation-related points, together with extreme coaching initialization time because of information downloading earlier than coaching begins and step length outliers in coaching loops. It is best to notice that though utilizing the built-in guidelines are free, prices for customized guidelines apply based mostly on the occasion that you just configure in the course of the coaching job and storage that’s connected to it.
Conclusion
On this publish, we offered steering on value evaluation and greatest practices when coaching ML fashions utilizing SageMaker coaching jobs. As machine studying establishes itself as a strong device throughout industries, coaching and operating ML fashions wants to stay cost-effective. SageMaker presents a large and deep characteristic set for facilitating every step within the ML pipeline and offers value optimization alternatives with out impacting efficiency or agility.
Concerning the Authors
 Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise clients offering technical steering with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and laptop imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys films, music, and literature.
Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise clients offering technical steering with greatest practices for deploying and sustaining AI/ML options within the AWS ecosystem. She has labored with a variety of organizations on varied deep studying use instances involving NLP and laptop imaginative and prescient. She is captivated with empowering organizations to leverage generative AI to boost their use expertise. In her spare time, she enjoys films, music, and literature.
 Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Primarily based out of Israel, Uri works to empower enterprise clients on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountain climbing, and growing entropy.
Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Primarily based out of Israel, Uri works to empower enterprise clients on all issues ML to design, construct, and function at scale. In his spare time, he enjoys biking, mountain climbing, and growing entropy.