Resolving code evaluation feedback with ML – Google AI Weblog
Code-change critiques are a important a part of the software program improvement course of at scale, taking a big quantity of the code authors’ and the code reviewers’ time. As a part of this course of, the reviewer inspects the proposed code and asks the writer for code adjustments by means of feedback written in pure language. At Google, we see millions of reviewer comments per 12 months, and authors require a median of ~60 minutes active shepherding time between sending adjustments for evaluation and at last submitting the change. In our measurements, the required energetic work time that the code writer should do to deal with reviewer feedback grows virtually linearly with the variety of feedback. Nevertheless, with machine studying (ML), we’ve got a chance to automate and streamline the code evaluation course of, e.g., by proposing code adjustments based mostly on a remark’s textual content.
Right this moment, we describe making use of current advances of huge sequence fashions in a real-world setting to routinely resolve code evaluation feedback within the day-to-day improvement workflow at Google (publication forthcoming). As of at the moment, code-change authors at Google tackle a considerable quantity of reviewer feedback by making use of an ML-suggested edit. We anticipate that to cut back time spent on code critiques by a whole bunch of hundreds of hours yearly at Google scale. Unsolicited, very constructive suggestions highlights that the impression of ML-suggested code edits will increase Googlers’ productiveness and permits them to deal with extra inventive and complicated duties.
Predicting the code edit
We began by coaching a mannequin that predicts code edits wanted to deal with reviewer feedback. The mannequin is pre-trained on varied coding duties and associated developer actions (e.g., renaming a variable, repairing a damaged construct, modifying a file). It’s then fine-tuned for this particular job with reviewed code adjustments, the reviewer feedback, and the edits the writer carried out to deal with these feedback.
 |
| An instance of an ML-suggested edit of refactorings which might be unfold throughout the code. |
Google makes use of a monorepo, a single repository for all of its software program artifacts, which permits our coaching dataset to incorporate all unrestricted code used to construct Google’s most up-to-date software program, in addition to earlier variations.
To enhance the mannequin high quality, we iterated on the coaching dataset. For instance, we in contrast the mannequin efficiency for datasets with a single reviewer remark per file to datasets with a number of feedback per file, and experimented with classifiers to wash up the coaching information based mostly on a small, curated dataset to decide on the mannequin with one of the best offline precision and recall metrics.
Serving infrastructure and person expertise
We designed and applied the characteristic on high of the educated mannequin, specializing in the general person expertise and developer effectivity. As a part of this, we explored totally different person expertise (UX) options by means of a sequence of person research. We then refined the characteristic based mostly on insights from an inside beta (i.e., a check of the characteristic in improvement) together with person suggestions (e.g., a “Was this beneficial?” button subsequent to the recommended edit).
The ultimate mannequin was calibrated for a goal precision of fifty%. That’s, we tuned the mannequin and the ideas filtering, so that fifty% of recommended edits on our analysis dataset are right. Typically, rising the goal precision reduces the variety of proven recommended edits, and reducing the goal precision results in extra incorrect recommended edits. Incorrect recommended edits take the builders time and cut back the builders’ belief within the characteristic. We discovered {that a} goal precision of fifty% gives a superb steadiness.
At a excessive degree, for each new reviewer remark, we generate the mannequin enter in the identical format that’s used for coaching, question the mannequin, and generate the recommended code edit. If the mannequin is assured within the prediction and some extra heuristics are happy, we ship the recommended edit to downstream methods. The downstream methods, i.e., the code evaluation frontend and the built-in improvement atmosphere (IDE), expose the recommended edits to the person and log person interactions, reminiscent of preview and apply occasions. A devoted pipeline collects these logs and generates mixture insights, e.g., the general acceptance charges as reported on this weblog publish.
 |
| Structure of the ML-suggested edits infrastructure. We course of code and infrastructure from a number of companies, get the mannequin predictions and floor the predictions within the code evaluation instrument and IDE. |
The developer interacts with the ML-suggested edits within the code evaluation instrument and the IDE. Based mostly on insights from the person research, the combination into the code evaluation instrument is most fitted for a streamlined evaluation expertise. The IDE integration gives extra performance and helps 3-way merging of the ML-suggested edits (left within the determine beneath) in case of conflicting native adjustments on high of the reviewed code state (proper) into the merge consequence (middle).
.gif) |
| 3-way-merge UX in IDE. |
Outcomes
Offline evaluations point out that the mannequin addresses 52% of feedback with a goal precision of fifty%. The net metrics of the beta and the complete inside launch verify these offline metrics, i.e., we see mannequin ideas above our goal mannequin confidence for round 50% of all related reviewer feedback. 40% to 50% of all previewed recommended edits are utilized by code authors.
We used the “not useful” suggestions in the course of the beta to establish recurring failure patterns of the mannequin. We applied serving-time heuristics to filter these and, thus, cut back the variety of proven incorrect predictions. With these adjustments, we traded amount for high quality and noticed an elevated real-world acceptance price.
.gif) |
| Code evaluation instrument UX. The suggestion is proven as a part of the remark and could be previewed, utilized and rated as useful or not useful. |
Our beta launch confirmed a discoverability problem: code authors solely previewed ~20% of all generated recommended edits. We modified the UX and launched a distinguished “Present ML-edit” button (see the determine above) subsequent to the reviewer remark, resulting in an general preview price of ~40% at launch. We moreover discovered that recommended edits within the code evaluation instrument are sometimes not relevant as a consequence of conflicting adjustments that the writer did in the course of the evaluation course of. We addressed this with a button within the code evaluation instrument that opens the IDE in a merge view for the recommended edit. We now observe that greater than 70% of those are utilized within the code evaluation instrument and fewer than 30% are utilized within the IDE. All these adjustments allowed us to extend the general fraction of reviewer feedback which might be addressed with an ML-suggested edit by an element of two from beta to the complete inside launch. At Google scale, these outcomes assist automate the decision of a whole bunch of hundreds of feedback annually.
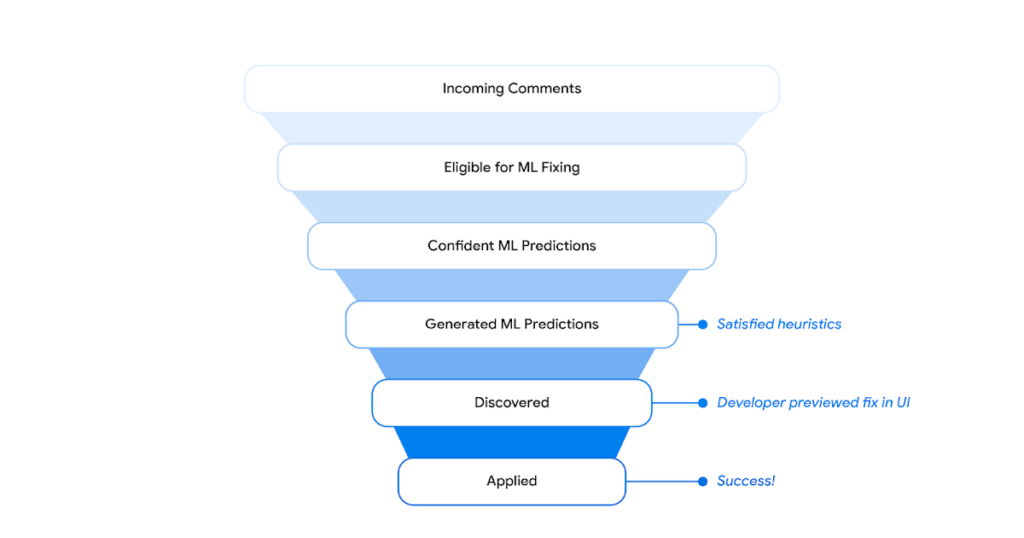
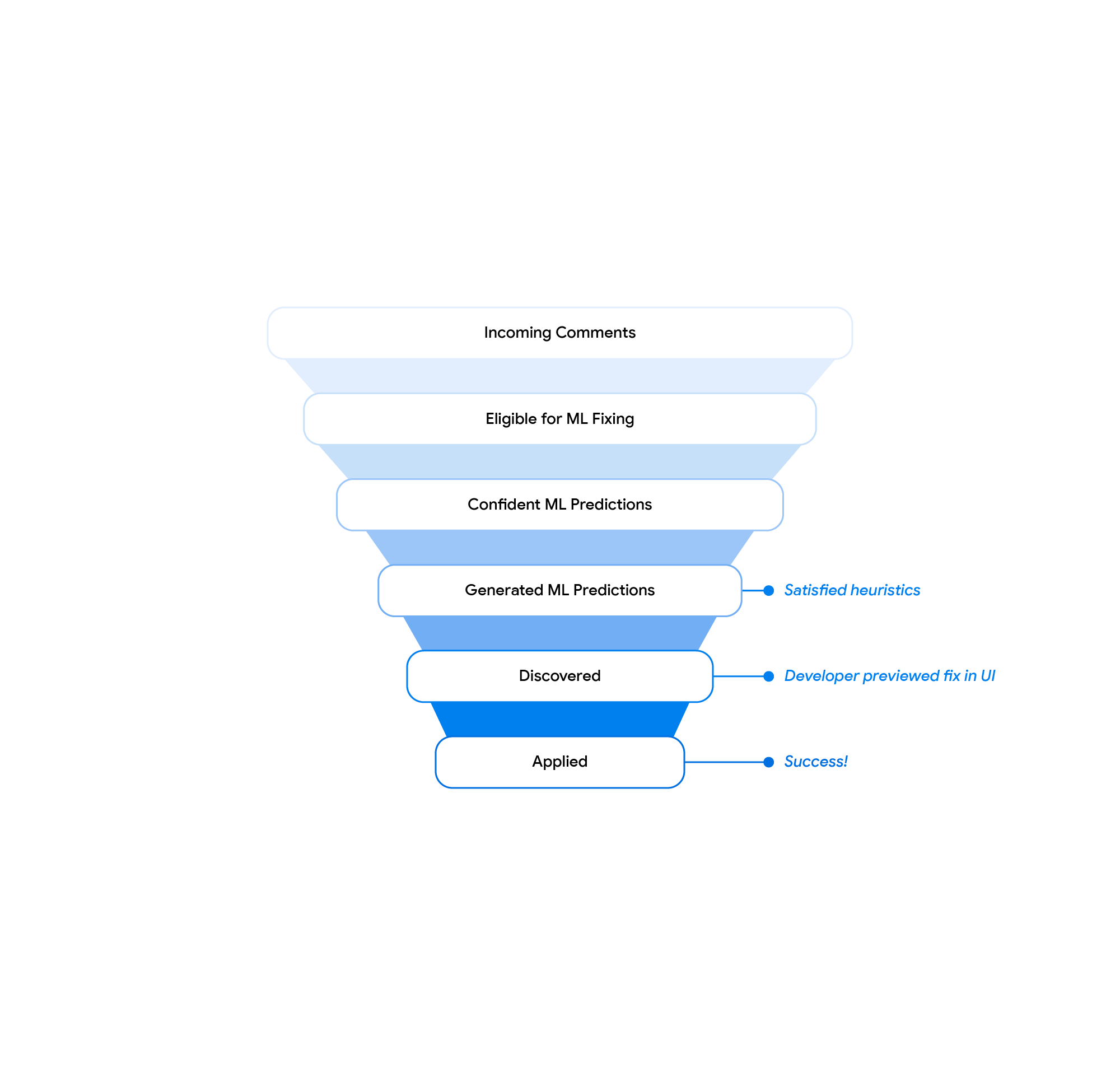
 |
| Solutions filtering funnel. |
We see ML-suggested edits addressing a variety of reviewer feedback in manufacturing. This consists of easy localized refactorings and refactorings which might be unfold throughout the code, as proven within the examples all through the weblog publish above. The characteristic addresses longer and fewer formally-worded feedback that require code technology, refactorings and imports.
 |
| Instance of a suggestion for an extended and fewer formally worded remark that requires code technology, refactorings and imports. |
The mannequin also can reply to complicated feedback and produce in depth code edits (proven beneath). The generated check case follows the prevailing unit check sample, whereas altering the main points as described within the remark. Moreover, the edit suggests a complete identify for the check reflecting the check semantics.
 |
| Instance of the mannequin’s means to reply to complicated feedback and produce in depth code edits. |
Conclusion and future work
On this publish, we launched an ML-assistance characteristic to cut back the time spent on code evaluation associated adjustments. In the intervening time, a considerable quantity of all actionable code evaluation feedback on supported languages are addressed with utilized ML-suggested edits at Google. A 12-week A/B experiment throughout all Google builders will additional measure the impression of the characteristic on the general developer productiveness.
We’re engaged on enhancements all through the entire stack. This consists of rising the standard and recall of the mannequin and constructing a extra streamlined expertise for the developer with improved discoverability all through the evaluation course of. As a part of this, we’re investigating the choice of exhibiting recommended edits to the reviewer whereas they draft feedback and increasing the characteristic into the IDE to allow code-change authors to get recommended code edits for natural-language instructions.
Acknowledgements
That is the work of many individuals in Google Core Methods & Experiences staff, Google Analysis, and DeepMind. We would wish to particularly thank Peter Choy for bringing the collaboration collectively, and all of our staff members for his or her key contributions and helpful recommendation, together with Marcus Revaj, Gabriela Surita, Maxim Tabachnyk, Jacob Austin, Nimesh Ghelani, Dan Zheng, Peter Josling, Mariana Stariolo, Chris Gorgolewski, Sascha Varkevisser, Katja Grünwedel, Alberto Elizondo, Tobias Welp, Paige Bailey, Pierre-Antoine Manzagol, Pascal Lamblin, Chenjie Gu, Petros Maniatis, Henryk Michalewski, Sara Wiltberger, Ambar Murillo, Satish Chandra, Madhura Dudhgaonkar, Niranjan Tulpule, Zoubin Ghahramani, Juanjo Carin, Danny Tarlow, Kevin Villela, Stoyan Nikolov, David Tattersall, Boris Bokowski, Kathy Nix, Mehdi Ghissassi, Luis C. Cobo, Yujia Li, David Choi, Kristóf Molnár, Vahid Meimand, Amit Patel, Brett Wiltshire, Laurent Le Brun, Mingpan Guo, Hermann Free, Jonas Mattes, Savinee Dancs.





