Weighted Sampling, Tidyr Verbs, Sturdy Scaler, RAPIDS, and extra
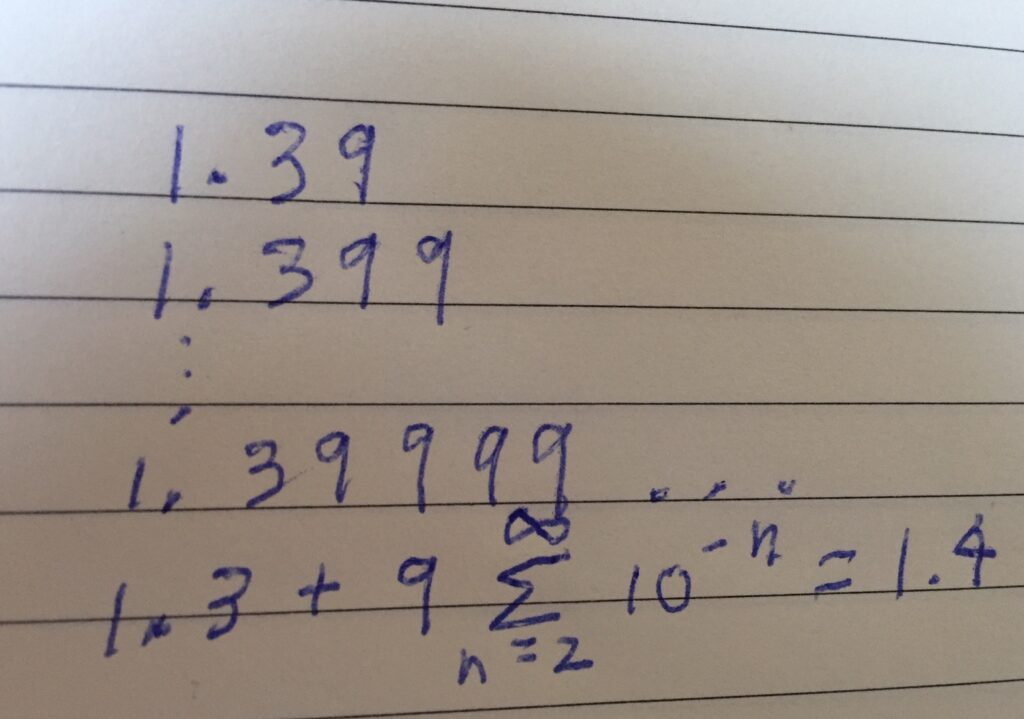
sparklyr 1.4 is now obtainable on CRAN! To put in sparklyr 1.4 from CRAN, run
On this weblog put up, we are going to showcase the next much-anticipated new functionalities from the sparklyr 1.4 launch:
Parallelized Weighted Sampling
Readers aware of dplyr::sample_n() and dplyr::sample_frac() features could have seen that each of them assist weighted-sampling use circumstances on R dataframes, e.g.,
dplyr::sample_n(mtcars, dimension = 3, weight = mpg, change = FALSE) mpg cyl disp hp drat wt qsec vs am gear carb
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4and
dplyr::sample_frac(mtcars, dimension = 0.1, weight = mpg, change = FALSE) mpg cyl disp hp drat wt qsec vs am gear carb
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1will choose some random subset of mtcars utilizing the mpg attribute because the sampling weight for every row. If change = FALSE is ready, then a row is faraway from the sampling inhabitants as soon as it will get chosen, whereas when setting change = TRUE, every row will all the time keep within the sampling inhabitants and will be chosen a number of occasions.
Now the very same use circumstances are supported for Spark dataframes in sparklyr 1.4! For instance:
will return a random subset of dimension 5 from the Spark dataframe mtcars_sdf.
Extra importantly, the sampling algorithm applied in sparklyr 1.4 is one thing that matches completely into the MapReduce paradigm: as we’ve cut up our mtcars knowledge into 4 partitions of mtcars_sdf by specifying repartition = 4L, the algorithm will first course of every partition independently and in parallel, deciding on a pattern set of dimension as much as 5 from every, after which scale back all 4 pattern units right into a last pattern set of dimension 5 by selecting information having the highest 5 highest sampling priorities amongst all.
How is such parallelization potential, particularly for the sampling with out alternative situation, the place the specified result’s outlined as the end result of a sequential course of? An in depth reply to this query is in this blog post, which features a definition of the issue (particularly, the precise that means of sampling weights in time period of possibilities), a high-level rationalization of the present answer and the motivation behind it, and in addition, some mathematical particulars all hidden in a single hyperlink to a PDF file, in order that non-math-oriented readers can get the gist of the whole lot else with out getting scared away, whereas math-oriented readers can get pleasure from understanding all of the integrals themselves earlier than peeking on the reply.
Tidyr Verbs
The specialised implementations of the next tidyr verbs that work effectively with Spark dataframes have been included as a part of sparklyr 1.4:
We are able to exhibit how these verbs are helpful for tidying knowledge via some examples.
Let’s say we’re given mtcars_sdf, a Spark dataframe containing all rows from mtcars plus the identify of every row:
# Supply: spark<?> [?? x 12]
mannequin mpg cyl disp hp drat wt qsec vs am gear carb
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Mazda RX4 21 6 160 110 3.9 2.62 16.5 0 1 4 4
2 Mazda RX4 W… 21 6 160 110 3.9 2.88 17.0 0 1 4 4
3 Datsun 710 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
4 Hornet 4 Dr… 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
5 Hornet Spor… 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
# … with extra rowsand we want to flip all numeric attributes in mtcar_sdf (in different phrases, all columns aside from the mannequin column) into key-value pairs saved in 2 columns, with the key column storing the identify of every attribute, and the worth column storing every attribute’s numeric worth. One technique to accomplish that with tidyr is by using the tidyr::pivot_longer performance:
mtcars_kv_sdf <- mtcars_sdf %>%
tidyr::pivot_longer(cols = -mannequin, names_to = "key", values_to = "worth")
print(mtcars_kv_sdf, n = 5)# Supply: spark<?> [?? x 3]
mannequin key worth
<chr> <chr> <dbl>
1 Mazda RX4 am 1
2 Mazda RX4 carb 4
3 Mazda RX4 cyl 6
4 Mazda RX4 disp 160
5 Mazda RX4 drat 3.9
# … with extra rowsTo undo the impact of tidyr::pivot_longer, we will apply tidyr::pivot_wider to our mtcars_kv_sdf Spark dataframe, and get again the unique knowledge that was current in mtcars_sdf:
tbl <- mtcars_kv_sdf %>%
tidyr::pivot_wider(names_from = key, values_from = worth)
print(tbl, n = 5)# Supply: spark<?> [?? x 12]
mannequin carb cyl drat hp mpg vs wt am disp gear qsec
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Mazda RX4 4 6 3.9 110 21 0 2.62 1 160 4 16.5
2 Hornet 4 Dr… 1 6 3.08 110 21.4 1 3.22 0 258 3 19.4
3 Hornet Spor… 2 8 3.15 175 18.7 0 3.44 0 360 3 17.0
4 Merc 280C 4 6 3.92 123 17.8 1 3.44 0 168. 4 18.9
5 Merc 450SLC 3 8 3.07 180 15.2 0 3.78 0 276. 3 18
# … with extra rowsOne other technique to scale back many columns into fewer ones is through the use of tidyr::nest to maneuver some columns into nested tables. As an example, we will create a nested desk perf encapsulating all performance-related attributes from mtcars (specifically, hp, mpg, disp, and qsec). Nonetheless, in contrast to R dataframes, Spark Dataframes shouldn’t have the idea of nested tables, and the closest to nested tables we will get is a perf column containing named structs with hp, mpg, disp, and qsec attributes:
mtcars_nested_sdf <- mtcars_sdf %>%
tidyr::nest(perf = c(hp, mpg, disp, qsec))We are able to then examine the kind of perf column in mtcars_nested_sdf:
sdf_schema(mtcars_nested_sdf)$perf$sort[1] "ArrayType(StructType(StructField(hp,DoubleType,true), StructField(mpg,DoubleType,true), StructField(disp,DoubleType,true), StructField(qsec,DoubleType,true)),true)"and examine particular person struct parts inside perf:
hp mpg disp qsec
110.00 21.00 160.00 16.46Lastly, we will additionally use tidyr::unnest to undo the consequences of tidyr::nest:
mtcars_unnested_sdf <- mtcars_nested_sdf %>%
tidyr::unnest(col = perf)
print(mtcars_unnested_sdf, n = 5)# Supply: spark<?> [?? x 12]
mannequin cyl drat wt vs am gear carb hp mpg disp qsec
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Mazda RX4 6 3.9 2.62 0 1 4 4 110 21 160 16.5
2 Hornet 4 Dr… 6 3.08 3.22 1 0 3 1 110 21.4 258 19.4
3 Duster 360 8 3.21 3.57 0 0 3 4 245 14.3 360 15.8
4 Merc 280 6 3.92 3.44 1 0 4 4 123 19.2 168. 18.3
5 Lincoln Con… 8 3 5.42 0 0 3 4 215 10.4 460 17.8
# … with extra rowsSturdy Scaler
RobustScaler is a brand new performance launched in Spark 3.0 (SPARK-28399). Due to a pull request by @zero323, an R interface for RobustScaler, specifically, the ft_robust_scaler() operate, is now a part of sparklyr.
It’s usually noticed that many machine studying algorithms carry out higher on numeric inputs which might be standardized. Many people have realized in stats 101 that given a random variable (X), we will compute its imply (mu = E[X]), customary deviation (sigma = sqrt{E[X^2] – (E[X])^2}), after which acquire a normal rating (z = frac{X – mu}{sigma}) which has imply of 0 and customary deviation of 1.
Nonetheless, discover each (E[X]) and (E[X^2]) from above are portions that may be simply skewed by excessive outliers in (X), inflicting distortions in (z). A selected dangerous case of it will be if all non-outliers amongst (X) are very near (0), therefore making (E[X]) near (0), whereas excessive outliers are all far within the damaging course, therefore dragging down (E[X]) whereas skewing (E[X^2]) upwards.
An alternate method of standardizing (X) primarily based on its median, 1st quartile, and third quartile values, all of that are strong in opposition to outliers, could be the next:
(displaystyle z = frac{X – textual content{Median}(X)}{textual content{P75}(X) – textual content{P25}(X)})
and that is exactly what RobustScaler provides.
To see ft_robust_scaler() in motion and exhibit its usefulness, we will undergo a contrived instance consisting of the next steps:
- Draw 500 random samples from the usual regular distribution
[1] -0.626453811 0.183643324 -0.835628612 1.595280802 0.329507772
[6] -0.820468384 0.487429052 0.738324705 0.575781352 -0.305388387
...- Examine the minimal and maximal values among the many (500) random samples:
[1] -3.008049 [1] 3.810277- Now create (10) different values which might be excessive outliers in comparison with the (500) random samples above. Provided that we all know all (500) samples are throughout the vary of ((-4, 4)), we will select (-501, -502, ldots, -509, -510) as our (10) outliers:
outliers <- -500L - seq(10)- Copy all (510) values right into a Spark dataframe named
sdf
library(sparklyr)
sc <- spark_connect(grasp = "native", model = "3.0.0")
sdf <- copy_to(sc, data.frame(worth = c(sample_values, outliers)))- We are able to then apply
ft_robust_scaler()to acquire the standardized worth for every enter:
- Plotting the consequence exhibits the non-outlier knowledge factors being scaled to values that also kind of kind a bell-shaped distribution centered round (0), as anticipated, so the scaling is powerful in opposition to affect of the outliers:

- Lastly, we will evaluate the distribution of the scaled values above with the distribution of z-scores of all enter values, and see how scaling the enter with solely imply and customary deviation would have brought on noticeable skewness – which the strong scaler has efficiently averted:
all_values <- c(sample_values, outliers)
z_scores <- (all_values - mean(all_values)) / sd(all_values)
ggplot(data.frame(scaled = z_scores), aes(x = scaled)) +
xlim(-0.05, 0.2) +
geom_histogram(binwidth = 0.005)
- From the two plots above, one can observe whereas each standardization processes produced some distributions that have been nonetheless bell-shaped, the one produced by
ft_robust_scaler()is centered round (0), accurately indicating the typical amongst all non-outlier values, whereas the z-score distribution is clearly not centered round (0) as its middle has been noticeably shifted by the (10) outlier values.
RAPIDS
Readers following Apache Spark releases intently in all probability have seen the latest addition of RAPIDS GPU acceleration assist in Spark 3.0. Catching up with this latest improvement, an choice to allow RAPIDS in Spark connections was additionally created in sparklyr and shipped in sparklyr 1.4. On a number with RAPIDS-capable {hardware} (e.g., an Amazon EC2 occasion of sort ‘p3.2xlarge’), one can set up sparklyr 1.4 and observe RAPIDS {hardware} acceleration being mirrored in Spark SQL bodily question plans:
library(sparklyr)
sc <- spark_connect(grasp = "native", model = "3.0.0", packages = "rapids")
dplyr::db_explain(sc, "SELECT 4")== Bodily Plan ==
*(2) GpuColumnarToRow false
+- GpuProject [4 AS 4#45]
+- GpuRowToColumnar TargetSize(2147483647)
+- *(1) Scan OneRowRelation[]All newly launched higher-order features from Spark 3.0, corresponding to array_sort() with customized comparator, transform_keys(), transform_values(), and map_zip_with(), are supported by sparklyr 1.4.
As well as, all higher-order features can now be accessed immediately via dplyr somewhat than their hof_* counterparts in sparklyr. This implies, for instance, that we will run the next dplyr queries to calculate the sq. of all array parts in column x of sdf, after which type them in descending order:
library(sparklyr)
sc <- spark_connect(grasp = "native", model = "3.0.0")
sdf <- copy_to(sc, tibble::tibble(x = list(c(-3, -2, 1, 5), c(6, -7, 5, 8))))
sq_desc <- sdf %>%
dplyr::mutate(x = transform(x, ~ .x * .x)) %>%
dplyr::mutate(x = array_sort(x, ~ as.integer(sign(.y - .x)))) %>%
dplyr::pull(x)
print(sq_desc)[[1]]
[1] 25 9 4 1
[[2]]
[1] 64 49 36 25Acknowledgement
In chronological order, we want to thank the next people for his or her contributions to sparklyr 1.4:
We additionally admire bug experiences, function requests, and precious different suggestions about sparklyr from our superior open-source group (e.g., the weighted sampling function in sparklyr 1.4 was largely motivated by this Github issue filed by @ajing, and a few dplyr-related bug fixes on this launch have been initiated in #2648 and accomplished with this pull request by @wkdavis).
Final however not least, the writer of this weblog put up is extraordinarily grateful for improbable editorial ideas from @javierluraschi, @batpigandme, and @skeydan.
In the event you want to be taught extra about sparklyr, we advocate testing sparklyr.ai, spark.rstudio.com, and in addition a number of the earlier launch posts corresponding to sparklyr 1.3 and sparklyr 1.2.
Thanks for studying!





