Bigger language fashions do in-context studying otherwise – Google AI Weblog

There have not too long ago been great advances in language fashions, partly as a result of they’ll carry out duties with robust efficiency by way of in-context learning (ICL), a course of whereby fashions are prompted with a number of examples of input-label pairs earlier than performing the duty on an unseen analysis instance. Generally, fashions’ success at in-context studying is enabled by:
- Their use of semantic prior data from pre-training to foretell labels whereas following the format of in-context examples (e.g., seeing examples of film critiques with “constructive sentiment” and “detrimental sentiment” as labels and performing sentiment analysis utilizing prior data).
- Studying the input-label mappings in context from the offered examples (e.g., discovering a sample that constructive critiques ought to be mapped to at least one label, and detrimental critiques ought to be mapped to a unique label).
In “Larger language models do in-context learning differently”, we purpose to study how these two components (semantic priors and input-label mappings) work together with one another in ICL settings, particularly with respect to the dimensions of the language mannequin that’s used. We examine two settings to check these two components — ICL with flipped labels (flipped-label ICL) and ICL with semantically-unrelated labels (SUL-ICL). In flipped-label ICL, labels of in-context examples are flipped in order that semantic priors and input-label mappings disagree with one another. In SUL-ICL, labels of in-context examples are changed with phrases which might be semantically unrelated to the duty offered in-context. We discovered that overriding prior data is an emergent means of mannequin scale, as is the flexibility to study in-context with semantically-unrelated labels. We additionally discovered that instruction tuning strengthens using prior data greater than it will increase the capability to study input-label mappings.
 |
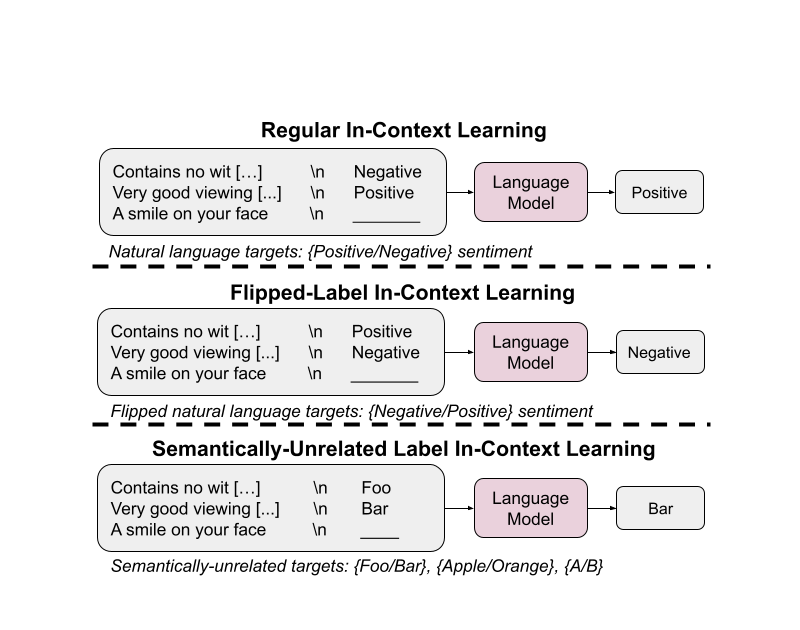
| An summary of flipped-label ICL and semantically-unrelated label ICL (SUL-ICL), in contrast with common ICL, for a sentiment evaluation activity. Flipped-label ICL makes use of flipped labels, forcing the mannequin to override semantic priors to be able to observe the in-context examples. SUL-ICL makes use of labels that aren’t semantically associated to the duty, which implies that fashions should study input-label mappings to be able to carry out the duty as a result of they’ll now not depend on the semantics of pure language labels. |
Experiment design
For a various dataset combination, we experiment on seven natural language processing (NLP) duties which were extensively used: sentiment analysis, subjective/objective classification, question classification, duplicated-question recognition, entailment recognition, financial sentiment analysis, and hate speech detection. We take a look at 5 language mannequin households, PaLM, Flan-PaLM, GPT-3, InstructGPT, and Codex.
Flipped labels
On this experiment, labels of in-context examples are flipped, which means that prior data and input-label mappings disagree (e.g., sentences containing constructive sentiment labeled as “detrimental sentiment”), thereby permitting us to check whether or not fashions can override their priors. On this setting, fashions which might be capable of override prior data and study input-label mappings in-context ought to expertise a lower in efficiency (since ground-truth analysis labels will not be flipped).
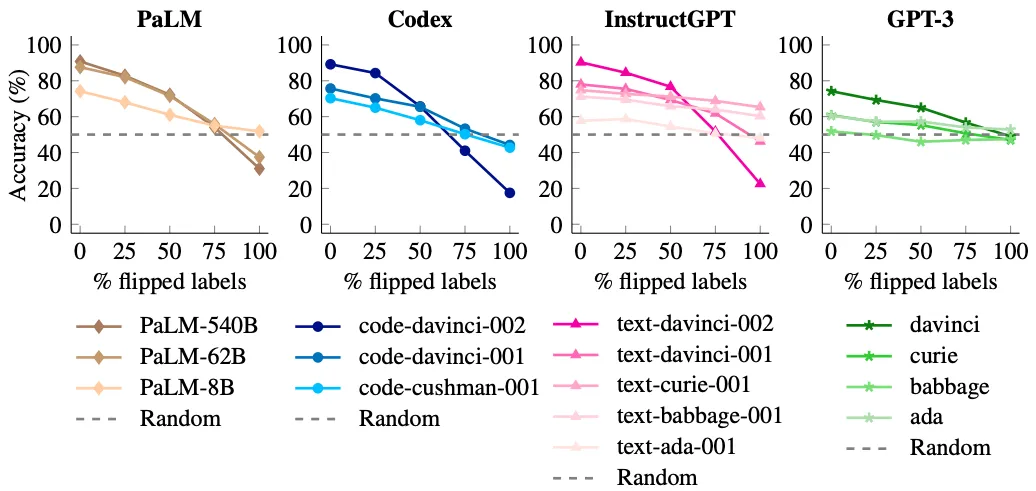 |
| The flexibility to override semantic priors when offered with flipped in-context instance labels emerges with mannequin scale. Smaller fashions can’t flip predictions to observe flipped labels (efficiency solely decreases barely), whereas bigger fashions can accomplish that (efficiency decreases to nicely under 50%). |
We discovered that when no labels are flipped, bigger fashions have higher efficiency than smaller fashions (as anticipated). However after we flip increasingly more labels, the efficiency of small fashions stays comparatively flat, however massive fashions expertise massive efficiency drops to well-below random guessing (e.g., 90% → 22.5% for code-davinci-002).
These outcomes point out that enormous fashions can override prior data from pre-training when contradicting input-label mappings are offered in-context. Small fashions can’t do that, making this means an emergent phenomena of mannequin scale.
Semantically-unrelated labels
On this experiment, we substitute labels with semantically-irrelevant ones (e.g., for sentiment evaluation, we use “foo/bar” as an alternative of “detrimental/constructive”), which implies that the mannequin can solely carry out ICL by studying from input-label mappings. If a mannequin principally depends on prior data for ICL, then its efficiency ought to lower after this alteration since it can now not have the ability to use semantic meanings of labels to make predictions. A mannequin that may study enter–label mappings in-context, alternatively, would have the ability to study these semantically-unrelated mappings and mustn’t expertise a significant drop in efficiency.
 |
| Small fashions rely extra on semantic priors than massive fashions do, as indicated by the larger lower in efficiency for small fashions than for giant fashions when utilizing semantically-unrelated labels (i.e., targets) as an alternative of pure language labels. For every plot, fashions are proven so as of accelerating mannequin measurement (e.g., for GPT-3 fashions, a is smaller than b, which is smaller than c). |
Certainly, we see that utilizing semantically-unrelated labels ends in a larger efficiency drop for small fashions. This implies that smaller fashions primarily depend on their semantic priors for ICL moderately than studying from the offered input-label mappings. Giant fashions, alternatively, have the flexibility to study input-label mappings in-context when the semantic nature of labels is eliminated.
We additionally discover that together with extra in-context examples (i.e., exemplars) ends in a larger efficiency enchancment for giant fashions than it does for small fashions, indicating that enormous fashions are higher at studying from in-context examples than small fashions are.
 |
| Within the SUL-ICL setup, bigger fashions profit extra from extra examples than smaller fashions do. |
Instruction tuning
Instruction tuning is a well-liked method for bettering mannequin efficiency, which entails tuning fashions on varied NLP duties which might be phrased as directions (e.g., “Query: What’s the sentiment of the next sentence, ‘This film is nice.’ Reply: Optimistic”). Because the course of makes use of pure language labels, nevertheless, an open query is whether or not it improves the flexibility to study input-label mappings or whether or not it strengthens the flexibility to acknowledge and apply semantic prior data. Each of those would result in an enchancment in efficiency on commonplace ICL duties, so it’s unclear which of those happen.
We examine this query by operating the identical two setups as earlier than, solely this time we deal with evaluating commonplace language fashions (particularly, PaLM) with their instruction-tuned variants (Flan-PaLM).
First, we discover that Flan-PaLM is healthier than PaLM after we use semantically-unrelated labels. This impact may be very outstanding in small fashions, as Flan-PaLM-8B outperforms PaLM-8B by 9.6% and virtually catches as much as PaLM-62B. This pattern means that instruction tuning strengthens the flexibility to study input-label mappings, which isn’t notably stunning.
 |
| Instruction-tuned language fashions are higher at studying enter–label mappings than pre-training–solely language fashions are. |
Extra apparently, we noticed that Flan-PaLM is definitely worse than PaLM at following flipped labels, which means that the instruction tuned fashions have been unable to override their prior data (Flan-PaLM fashions don’t attain under random guessing with 100% flipped labels, however PaLM fashions with out instruction tuning can attain 31% accuracy in the identical setting). These outcomes point out that instruction tuning should enhance the extent to which fashions depend on semantic priors once they’re accessible.
 |
| Instruction-tuned fashions are worse than pre-training–solely fashions at studying to override semantic priors when offered with flipped labels in-context. |
Mixed with the earlier outcome, we conclude that though instruction tuning improves the flexibility to study input-label mappings, it strengthens the utilization of semantic prior data extra.
Conclusion
We examined the extent to which language fashions study in-context by using prior data realized throughout pre-training versus input-label mappings offered in-context.
We first confirmed that enormous language fashions can study to override prior data when offered with sufficient flipped labels, and that this means emerges with mannequin scale. We then discovered that efficiently doing ICL utilizing semantically-unrelated labels is one other emergent means of mannequin scale. Lastly, we analyzed instruction-tuned language fashions and noticed that instruction tuning improves the capability to study input-label mappings but in addition strengthens using semantic prior data much more.
Future work
These outcomes underscore how the ICL conduct of language fashions can change relying on their scale, and that bigger language fashions have an emergent means to map inputs to many varieties of labels, a type of reasoning by which input-label mappings can probably be realized for arbitrary symbols. Future analysis may assist present insights on why these phenomena happen with respect to mannequin scale.
Acknowledgements
This work was carried out by Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. We wish to thank Sewon Min and our fellow collaborators at Google Analysis for his or her recommendation and useful discussions.





