When Ought to You Positive-Tune LLMs?. There was a flurry of thrilling… | by Skanda Vivek | Might, 2023
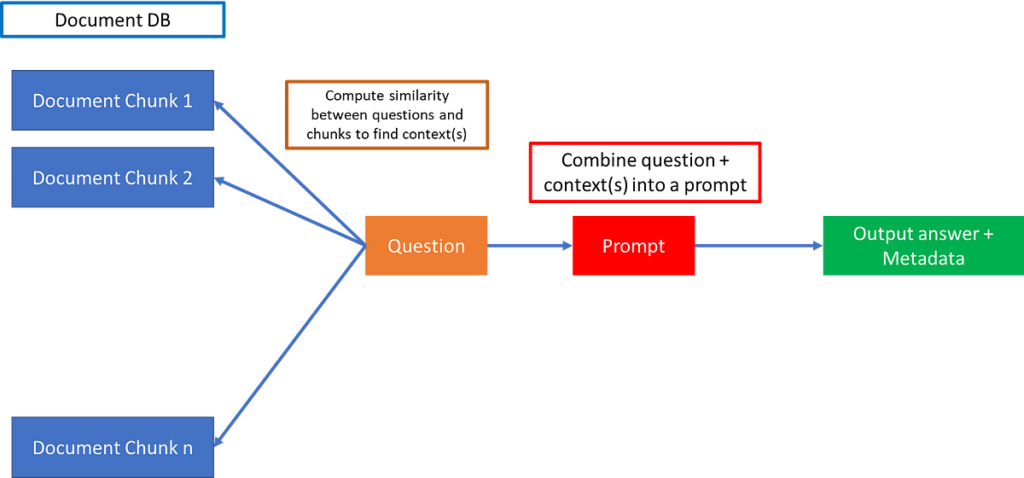
The issue of giving all the mandatory info to the mannequin to reply questions is now offloaded from the mannequin structure to a database, containing doc chunks.
The paperwork of relevance can then be discovered by computing similarities between the query and the doc chunks. That is performed usually by changing the chunks and query into phrase embedding vectors, and computing cosine similarities between chunks and query, and at last selecting solely these chunks above a sure cosine similarity as related context.
Lastly, the query and context may be mixed right into a immediate as under, and fed into an LLM API like ChatGPT:
immediate=f"Reply the query. Context: {context}n Query: {query}"
You may ask — why not feed your entire paperwork and query into the immediate as an alternative of separating out into chunks? The explanation we’re separating paperwork into chunks and never combining all paperwork right into a single immediate is as a result of LLMs have sure limits on most enter and output size. For ChatGPT, that is 4096 tokens, or roughly 6–7 pages of textual content.
Offloading paperwork to a database and querying utilizing closed LLM APIs may work properly in instances the place the reply is clearly current in these paperwork. However there are a variety of instances through which these might yield sub-optimal outcomes, resembling in order for you ChatGPT to provide an professional perspective on a distinct segment subject — for instance, speculating on the monetary outlook of the U.S. economic system.
Okay, so that you tried out ChatGPT or BARD — and also you didn’t prefer it. The solutions have been a bit off. For instance, you requested ChatGPT:
“How lengthy is the U.S. economic system more likely to have inflation?”
And it returned:
As an AI language mannequin, I can not predict the longer term with certainty, particularly with reference to advanced financial techniques. Nonetheless, I can offer you some info and views that will show you how to perceive the present state of affairs.
Inflation is a posh phenomenon that may be attributable to a wide range of elements resembling a rise in demand, provide constraints,….
Sadly that’s not adequate for you. In fact you possibly can feed ChatGPT some latest information about Fed Chairman Jerome Powell’s statements. However that doesn’t provide the similar wealthy area expertise that you’d get in case you spoke to — properly, Jerome Powell, who else! Or one other professional.
Take into consideration what it takes to be an professional in a sure area. Whereas some quantity of that is studying books on the subject, so much can be interacting with subject material consultants within the area, and studying from expertise. Whereas ChatGPT has been skilled on an unimaginable variety of finance books, it in all probability hasn’t been skilled by prime monetary consultants or consultants in different particular fields. So how would you make an LLM that’s an “professional” within the finance sector? That is the place fine-tuning is available in.
Earlier than I talk about fine-tuning LLMs, let’s speak about fine-tuning smaller language fashions like BERT, which was commonplace earlier than LLMs. For fashions like BERT and RoBERTa, fine-tuning quantities to spending some context, and labels. Duties are well-defined like extracting solutions from contexts, or classifying emails as spam vs not spam. I’ve written a few weblog posts on these that is likely to be helpful in case you are excited by fine-tuning language fashions:
Nonetheless, the rationale giant language fashions (LLMs) are all the craze is as a result of they will carry out a number of duties seamlessly by altering the best way you body prompts, and you’ve got the expertise much like speaking with an individual on the different finish. What we wish now’s to fine-tune that LLM to be an professional in a sure topic and have interaction in dialog like a “particular person.” That is fairly totally different from fine-tuning a mannequin like BERT on particular duties.
One of many earliest open-source breakthroughs was by a bunch of Stanford researchers that fine-tuned a 7B LLaMa mannequin (launched earlier within the yr by Meta) which they known as Alpaca for lower than 600$ on 52K directions. Quickly after, the Vicuna group launched a 13 Billion parameter mannequin which achieves 90% of ChatGPT quality.
Very lately, the MPT-7B transformer was launched that might ingest 65k tokens, 16X the enter measurement of ChatGPT! The coaching was performed from scratch over 9.5 days for 200k$. For example for a site particular LLM, Bloomberg launched a GPT-like mannequin BloombergGPT, constructed for finance and in addition skilled from scratch.
Current developments in coaching and fine-tuning open-source fashions are only the start for small and medium sized firms enriching their choices via personalized LLMs. So how do you resolve when it is sensible to fine-tune or prepare whole area particular LLMs?
First off, it is very important clearly set up the constraints of closed-source LLM APIs in your area and make the case for empowering prospects to talk with an professional in that area at a fraction of the fee. Positive-tuning a mannequin will not be very costly for 100 thousand directions or so — however getting the precise directions requires cautious thought. That is the place you additionally have to be a bit daring — I can’t but consider many areas the place a fine-tuned mannequin is proven to carry out considerably higher than ChatGPT on area particular duties, however I imagine that is proper across the nook, and any firm that does this properly will probably be rewarded.
Which brings me to the case for fully coaching an LLM from scratch. Sure this might simply price upwards of a whole lot of hundreds of {dollars}, however in case you make a strong case, traders could be glad to pitch in. In a latest interview with IBM, Hugging Face CEO Clem Delangue commented that quickly, personalized LLMs could possibly be as widespread place as proprietary codebases — and a significant factor of what it takes to be aggressive in an trade.
LLMs utilized to particular domains may be extraordinarily priceless within the trade. There are 3 ranges of accelerating price and customizability:
- Closed supply APIs + Doc Embedding Database: This primary resolution might be the best to get began off with, and contemplating the top quality of ChatGPT API — may even offer you a adequate (if not the perfect) efficiency. And it’s low cost!
- Positive-tune LLMs: Current progress from fine-tuning LLaMA-like fashions has proven this prices ~500$ to get a baseline efficiency much like ChatGPT in sure domains. May very well be worthwhile in case you had a database with ~50–100k directions or conversations to fine-tune a baseline mannequin.
- Prepare from scratch: As LLaMA and the more moderen MPT-7B fashions have proven, this prices ~100–200k and takes every week or two.
Now that you’ve the information — go forth and construct your customized area particular LLM purposes!



