Demystifying Bayesian Fashions: Unveiling Explanability by way of SHAP Values | by Shuyang Xiang | Could, 2023
Exploring PyMC’s Insights with SHAP Framework through an Participating Toy Instance
SHAP values (SHapley Additive exPlanations) are a game-theory-based technique used to extend the transparency and interpretability of machine studying fashions. Nonetheless, this technique, together with different machine studying explainability frameworks, has not often been utilized to Bayesian fashions, which give a posterior distribution capturing uncertainty in parameter estimates as an alternative of level estimates utilized by classical machine studying fashions.
Whereas Bayesian fashions supply a versatile framework for incorporating prior data, adjusting for information limitations, and making predictions, they’re sadly tough to interpret utilizing SHAP. SHAP regards the mannequin as a sport and every function as a participant in that sport, however the Bayesian mannequin just isn’t a sport. It’s somewhat an ensemble of video games whose parameters come from the posterior distributions. How can we interpret a mannequin when it’s greater than a sport?
This text makes an attempt to elucidate a Bayesian mannequin utilizing the SHAP framework by way of a toy instance. The mannequin is constructed on PyMC, a probabilistic programming library for Python that permits customers to assemble Bayesian fashions with a easy Python API and match them utilizing Markov chain Monte Carlo.
The principle concept is to use SHAP to an ensemble of deterministic fashions generated from a Bayesian community. For every function, we might acquire one pattern of the SHAP worth from a generated deterministic mannequin. The explainability could be given by the samples of all obtained SHAP values. We are going to illustrate this method with a easy instance.
All of the implementations will be discovered on this notebook .
Dataset
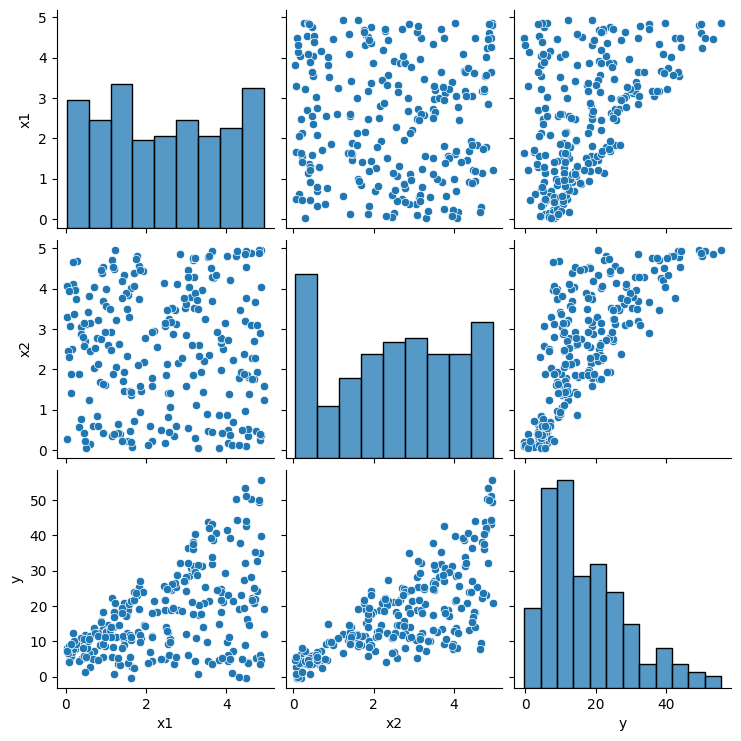
Think about the next dataset created by the writer, which comprises 250 factors: the variable y is dependent upon x1 and x2, each of which differ between 0 and 5. The picture under illustrates the dataset:

Let’s rapidly discover the information utilizing a pair plot. From this, we will observe the next:
- The variables x1 and x2 are usually not correlated.
- Each variables contribute to the output y to some extent. That’s, a single variable just isn’t sufficient to acquire y.

Modelization with PyMC
Let’s construct a Bayesian mannequin with PyMC. With out going into the main points that you will discover in any statistical e book, we’ll merely recall that the coaching technique of Bayesian machine studying fashions includes updating the mannequin’s parameters based mostly on noticed information and prior data utilizing Bayesian rules.
We outline the mannequin’s construction as follows:

Picture by writer: mannequin construction
Defining the priors and probability above, we’ll use the PyMC commonplace sampling algorithm NUTS designed to routinely tune its parameters, such because the step dimension and the variety of leapfrog steps, to attain environment friendly exploration of the goal distribution. It repeats a tree exploration to simulate the trajectory of the purpose within the parameter area and decide whether or not to simply accept or reject a pattern. Such iteration stops both when the utmost variety of iterations is reached or the extent of convergence is achieved.
You’ll be able to see within the code under that we arrange the priors, outline the probability, after which run the sampling algorithm utilizing PyMC.
Let’s construct a Bayesian mannequin utilizing PyMC. Bayesian machine studying mannequin coaching includes updating the mannequin’s parameters based mostly on noticed information and prior data utilizing Bayesian rules. We received’t go into element right here, as you will discover it in any statistical e book.
We are able to outline the mannequin’s construction as proven under:
For the priors and probability outlined above, we’ll use the PyMC commonplace sampling algorithm NUTS. This algorithm is designed to routinely tune its parameters, such because the step dimension and the variety of leapfrog steps, to attain environment friendly exploration of the goal distribution. It repeats a tree exploration to simulate the trajectory of the purpose within the parameter area and decide whether or not to simply accept or reject a pattern. The iteration stops both when the utmost variety of iterations is reached or the extent of convergence is achieved.
Within the code under, we arrange the priors, outline the probability, after which run the sampling algorithm utilizing PyMC.
with pm.Mannequin() as mannequin:# Set priors.
intercept=pm.Uniform(identify="intercept",decrease=-10, higher=10)
x1_slope=pm.Uniform(identify="x1_slope",decrease=-5, higher=5)
x2_slope=pm.Uniform(identify="x2_slope",decrease=-5, higher=5)
interaction_slope=pm.Uniform(identify="interaction_slope",decrease=-5, higher=5)
sigma=pm.Uniform(identify="sigma", decrease=1, higher=5)
# Set likelhood.
probability = pm.Regular(identify="y", mu=intercept + x1_slope*x1+x2_slope*x2+interaction_slope*x1*x2,
sigma=sigma, noticed=y)
# Configure sampler.
hint = pm.pattern(5000, chains=5, tune=1000, target_accept=0.87, random_seed=SEED)
The hint plot under shows the posteriors of the parameters within the mannequin.

We now wish to implement SHAP on the mannequin described above. Be aware that for a given enter (x1, x2), the mannequin’s output y is a chance conditional on the parameters. Thus, we will acquire a deterministic mannequin and corresponding SHAP values for all options by drawing one pattern from the obtained posteriors. Alternatively, if we draw an ensemble of parameter samples, we are going to get an ensemble of deterministic fashions and, subsequently, samples of SHAP values for all options.
The posteriors will be obtained utilizing the next code, the place we draw 200 samples per chain:
with mannequin:
idata = pm.sample_prior_predictive(samples=200, random_seed=SEED)
idata.prolong(pm.pattern(200, tune=2000, random_seed=SEED)right here
Right here is the desk of the information variables from the posteriors:

Subsequent, we compute one pair of SHAP values for every drawn pattern of mannequin parameters. The code under loops over the parameters, defines one mannequin for every parameter pattern, and computes the SHAP values of x_test=(2,3) of curiosity.
background=np.hstack((x1.reshape((250,1)),x2.reshape((250,1))))
shap_values_list=[]
x_test=np.array([2,3]).reshape((-1,2))
for i in vary(len(pos_intercept)):
mannequin=SimpleModel(intercept=pos_intercept[i],
x1_slope=pos_x1_slope[i],
x2_slope=pos_x2_slope[i],
interaction_slope=pos_interaction_slope[i],
sigma=pos_sigma[i])
explainer = shap.Explainer(mannequin.predict, background)
shap_values = explainer(x_test)
shap_values_list.append(shap_values.values)
The ensuing ensemble of the two-dimensional SHAP values of the enter is proven under:

From the plot above, we will infer the next:
- The SHAP values of each dimensions type kind of a standard distribution.
- The primary dimension has a constructive contribution (-1.75 as median) to the mannequin, whereas the second has a detrimental contribution (3.45 as median). Nonetheless, the second dimension’s contribution has an even bigger absolute worth.
This text explores the usage of SHAP values, a game-theory-based technique for growing transparency and interpretability of machine studying fashions, in Bayesian fashions. A toy instance is used to show how SHAP will be utilized to a Bayesian community.
Please notice that SHAP is model-agnostic. Due to this fact, with adjustments to its implementation, it could be doable to use SHAP on to the Bayesian mannequin itself sooner or later.



