Google AI Introduces MaMMUT: A Easy Structure for Joint Studying for MultiModal Duties
The thought on which vision-language elementary fashions are constructed is {that a} single pre-training can be utilized to adapt to all kinds of downstream actions. There are two broadly used however distinct coaching eventualities:
- Contrastive studying within the fashion of CLIP. It trains the mannequin to foretell if image-text pairs accurately match, successfully constructing visible and textual content representations for the corresponding picture and textual content inputs. It allows image-text and text-image retrieval duties like deciding on the picture that greatest matches a particular description.
- Subsequent-token prediction: It learns to generate textual content by predicting essentially the most possible subsequent token in a sequence. It helps text-generative duties like Picture Captioning and Visible Query Answering (VQA) whereas contrastive studying.
Whereas each strategies have proven promising outcomes, pre-trained fashions not transferable to different duties are inclined to carry out poorly on text-generation duties and vice versa. It’s additionally widespread for advanced or inefficient approaches for use whereas adapting to new duties.
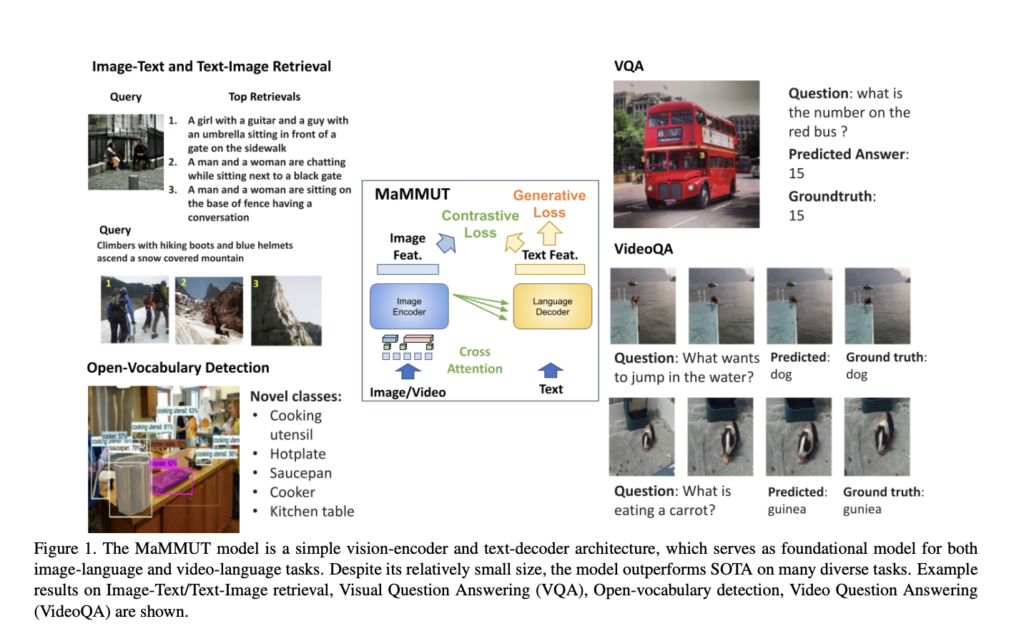
To coach collectively for these competing goals and to supply the groundwork for quite a few vision-language duties both immediately or by straightforward adaptation, a current Google research presents MaMMUT, a easy structure for joint studying for multimodal duties. MaMMUT is a condensed multimodal mannequin with solely 2B parameters, and it might be skilled to attain contrastive, text-generating, and localization-aware targets. Its easy design—only one picture encoder and one textual content decoder—makes it straightforward to recycle the 2 independently.
The proposed mannequin contains a single visible encoder and a single text-decoder linked through cross-attention and trains concurrently on contrastive and text-generative forms of losses. Earlier work both doesn’t tackle image-text retrieval duties or simply applies some losses to pick out points of the mannequin. Collectively coaching contrastive losses and text-generative captioning-like losses is critical to allow multimodal duties and absolutely use the decoder-only mannequin.
There’s a appreciable efficiency acquire with a smaller mannequin dimension (almost half the parameters) for decoder-only fashions in language studying. One of many greatest obstacles to utilizing them in multimodal conditions is reconciling contrastive studying (which depends on unconditional sequence-level illustration) and captioning (which optimizes the probability of a token primarily based on the tokens that got here earlier than it). The researchers provide a two-pass approach to study these incompatible textual content representations throughout the decoder collectively.
Their preliminary run at studying the caption era problem makes use of cross-attention and causal masking in order that the textual content options can take note of the picture options and make sequential token predictions. They flip off cross-attention and causal masking to study the contrastive job on the second go. Whereas the image options will stay hidden from the textual content options, the textual content options will have the ability to attend in each instructions on all textual content tokens concurrently. Each duties, which had been beforehand troublesome to reconcile, could now be dealt with by the identical decoder due to the two-pass approach. Though this mannequin structure is sort of easy, it may possibly function a foundation for numerous multimodal duties.
Because the structure is skilled for a number of separate duties, it might be simply built-in into many purposes, together with image-text and text-image retrieval, visible high quality evaluation, and captioning. The researchers use sparse video tubes to immediately entry spatiotemporal info from video for light-weight adaptation. Coaching to detect bounding containers through an object-detection head can be required to switch the mannequin to Open-Vocabulary Detection.
Regardless of its compact design, MaMMUT gives superior or aggressive leads to numerous areas, together with image-text and text-image retrieval, video query answering (VideoQA), video captioning, open-vocabulary identification, and VQA. The workforce highlights that their mannequin achieves higher outcomes than a lot bigger fashions like Flamingo, which is tailor-made to picture+video pre-training and already pre-trained on image-text and video-text information.
Try the Paper and Google blog. Don’t overlook to affix our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. When you’ve got any questions relating to the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in numerous fields. She is captivated with exploring the brand new developments in applied sciences and their real-life utility.



