Optimized PyTorch 2.0 inference with AWS Graviton processors

New generations of CPUs supply a major efficiency enchancment in machine studying (ML) inference resulting from specialised built-in directions. Mixed with their flexibility, excessive velocity of growth, and low working value, these general-purpose processors supply an alternative choice to different present {hardware} options.
AWS, Arm, Meta and others helped optimize the efficiency of PyTorch 2.0 inference for Arm-based processors. In consequence, we’re delighted to announce that AWS Graviton-based occasion inference efficiency for PyTorch 2.0 is as much as 3.5 occasions the velocity for Resnet50 in comparison with the earlier PyTorch launch (see the next graph), and as much as 1.4 occasions the velocity for BERT, making Graviton-based situations the quickest compute optimized situations on AWS for these fashions.
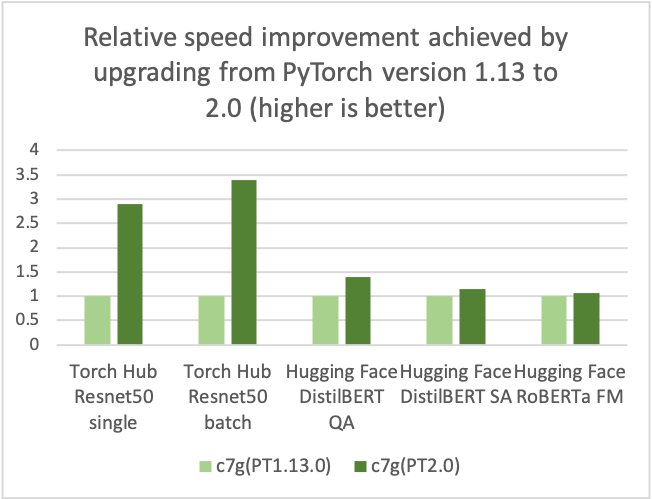
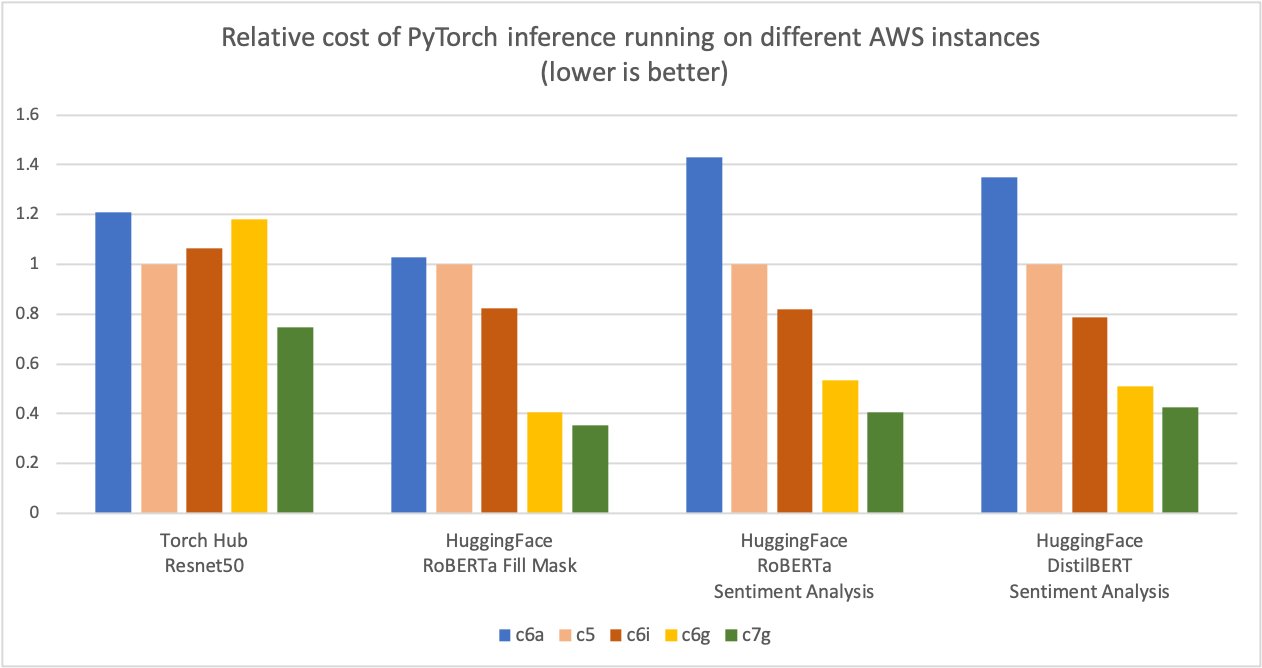
AWS measured as much as 50% value financial savings for PyTorch inference with AWS Graviton3-based Amazon Elastic Cloud Compute C7g situations throughout Torch Hub Resnet50, and a number of Hugging Face fashions relative to comparable EC2 situations, as proven within the following determine.
Moreover, the latency of inference can also be decreased, as proven within the following determine.

We now have seen an identical development within the price-performance benefit for different workloads on Graviton, for instance video encoding with FFmpeg.
Optimization particulars
The optimizations targeted on three key areas:
- GEMM kernels – PyTorch helps Arm Compute Library (ACL) GEMM kernels by way of the OneDNN backend (beforehand referred to as MKL-DNN) for Arm-based processors. The ACL library offers Neon and SVE optimized GEMM kernels for each fp32 and bfloat16 codecs. These kernels enhance the SIMD {hardware} utilization and scale back the end-to-end inference latencies.
- bfloat16 help – The bfloat16 help in Graviton3 permits for environment friendly deployment of fashions educated utilizing bfloat16, fp32, and AMP (Automated Blended Precision). The usual fp32 fashions use bfloat16 kernels by way of OneDNN quick math mode, with out mannequin quantization, offering as much as two occasions quicker efficiency in comparison with the prevailing fp32 mannequin inference with out bfloat16 quick math help.
- Primitive caching – We additionally applied primitive caching for conv, matmul, and interior product operators to keep away from redundant GEMM kernel initialization and tensor allocation overhead.
Tips on how to reap the benefits of the optimizations
The best approach to get began is through the use of the AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2) C7g instances or Amazon SageMaker. DLCs can be found on Amazon Elastic Container Registry (Amazon ECR) for AWS Graviton or x86. For extra particulars on SageMaker, seek advice from Run machine learning inference workloads on AWS Graviton-based instances with Amazon SageMaker and Amazon SageMaker adds eight new Graviton-based instances for model deployment.
Use AWS DLCs
To make use of AWS DLCs, use the next code:
When you choose to put in PyTorch by way of pip, set up the PyTorch 2.0 wheel from the official repo. On this case, you’ll have to set two setting variables as defined within the code under earlier than launching PyTorch to activate the Graviton optimization.
Use the Python wheel
To make use of the Python wheel, seek advice from the next code:
Run inference
You need to use PyTorch TorchBench to measure the CPU inference efficiency enhancements, or to check completely different occasion varieties:
Benchmarking
You need to use the Amazon SageMaker Inference Recommender utility to automate efficiency benchmarking throughout completely different situations. With Inference Recommender, you’ll find the real-time inference endpoint that delivers the very best efficiency on the lowest value for a given ML mannequin. We collected the previous information utilizing the Inference Recommender notebooks by deploying the fashions on manufacturing endpoints. For extra particulars on Inference Recommender, seek advice from the GitHub repo. We benchmarked the next fashions for this submit: ResNet50 image classification, DistilBERT sentiment analysis, RoBERTa fill mask, and RoBERTa sentiment analysis.
Conclusion
AWS measured as much as 50% value financial savings for PyTorch inference with AWS Graviton3-based Amazon Elastic Cloud Compute C7g situations throughout Torch Hub Resnet50, and a number of Hugging Face fashions relative to comparable EC2 situations. These situations can be found on SageMaker and Amazon EC2. The AWS Graviton Technical Guide offers the checklist of optimized libraries and greatest practices that can assist you to obtain value advantages with Graviton situations throughout completely different workloads.
When you discover use circumstances the place related efficiency beneficial properties aren’t noticed on AWS Graviton, please open a problem on the AWS Graviton Technical Guide to tell us about it. We’ll proceed so as to add extra efficiency enhancements to make Graviton essentially the most cost-effective and environment friendly general-purpose processor for inference utilizing PyTorch.
Concerning the writer
 Sunita Nadampalli is a Software program Growth Supervisor at AWS. She leads Graviton software program efficiency optimizations for machine leaning, HPC, and multimedia workloads. She is keen about open-source growth and delivering cost-effective software program options with Arm SoCs.
Sunita Nadampalli is a Software program Growth Supervisor at AWS. She leads Graviton software program efficiency optimizations for machine leaning, HPC, and multimedia workloads. She is keen about open-source growth and delivering cost-effective software program options with Arm SoCs.



