Construct a picture search engine with Amazon Kendra and Amazon Rekognition

On this publish, we focus on a machine studying (ML) resolution for complicated picture searches utilizing Amazon Kendra and Amazon Rekognition. Particularly, we use the instance of structure diagrams for complicated pictures on account of their incorporation of quite a few totally different visible icons and textual content.
With the web, looking and acquiring a picture has by no means been simpler. More often than not, you may precisely find your required pictures, equivalent to trying to find your subsequent vacation getaway vacation spot. Easy searches are sometimes profitable, as a result of they’re not related to many traits. Past the specified picture traits, the search standards sometimes doesn’t require vital particulars to find the required end result. For instance, if a consumer tried to seek for a particular kind of blue bottle, outcomes of many various kinds of blue bottles might be displayed. Nevertheless, the specified blue bottle will not be simply discovered on account of generic search phrases.
Deciphering search context additionally contributes to simplification of outcomes. When customers have a desired picture in thoughts, they attempt to body this right into a text-based search question. Understanding the nuances between search queries for comparable matters is necessary to offer related outcomes and reduce the hassle required from the consumer to manually kind via outcomes. For instance, the search question “Canine proprietor performs fetch” seeks to return picture outcomes exhibiting a canine proprietor taking part in a sport of fetch with a canine. Nevertheless, the precise outcomes generated might as an alternative give attention to a canine fetching an object with out displaying an proprietor’s involvement. Customers might need to manually filter out unsuitable picture outcomes when coping with complicated searches.
To handle the issues related to complicated searches, this publish describes intimately how one can obtain a search engine that’s able to trying to find complicated pictures by integrating Amazon Kendra and Amazon Rekognition. Amazon Kendra is an clever search service powered by ML, and Amazon Rekognition is an ML service that may establish objects, individuals, textual content, scenes, and actions from pictures or movies.
What pictures might be too complicated to be searchable? One instance is structure diagrams, which might be related to many search standards relying on the use case complexity and variety of technical companies required, which leads to vital handbook search effort for the consumer. For instance, if customers wish to discover an structure resolution for the use case of buyer verification, they may sometimes use a search question just like “Structure diagrams for buyer verification.” Nevertheless, generic search queries would span a variety of companies and throughout totally different content material creation dates. Customers would wish to manually choose appropriate architectural candidates primarily based on particular companies and take into account the relevance of the structure design decisions in line with the content material creation date and question date.
The next determine reveals an instance diagram that illustrates an orchestrated extract, remodel, and cargo (ETL) structure resolution.

For customers who will not be aware of the service choices which are supplied on the cloud platform, they might present totally different generic methods and descriptions when trying to find such a diagram. The next are some examples of the way it could possibly be searched:
- “Orchestrate ETL workflow”
- “Find out how to automate bulk knowledge processing”
- “Strategies to create a pipeline for remodeling knowledge”
Resolution overview
We stroll you thru the next steps to implement the answer:
- Prepare an Amazon Rekognition Custom Labels mannequin to acknowledge symbols in structure diagrams.
- Incorporate Amazon Rekognition textual content detection to validate structure diagram symbols.
- Use Amazon Rekognition inside an online crawler to construct a repository for looking
- Use Amazon Kendra to look the repository.
To simply present customers with a big repository of related outcomes, the answer ought to present an automatic manner of looking via trusted sources. Utilizing structure diagrams for example, the answer wants to look via reference hyperlinks and technical paperwork for structure diagrams and establish the companies current. Figuring out key phrases equivalent to use instances and trade verticals in these sources additionally permits the data to be captured and for extra related search outcomes to be exhibited to the consumer.
Contemplating the target of how related diagrams ought to be searched, the picture search resolution must fulfil three standards:
- Allow easy key phrase search
- Interpret search queries primarily based on use instances that customers present
- Type and order search outcomes
Key phrase search is just trying to find “Amazon Rekognition” and being proven structure diagrams on how the service is utilized in totally different use instances. Alternatively, the search phrases might be linked not directly to the diagram via use instances and trade verticals which may be related to the structure. For instance, trying to find the phrases “Find out how to orchestrate ETL pipeline” returns outcomes of structure diagrams constructed with AWS Glue and AWS Step Functions. Sorting and ordering of search outcomes primarily based on attributes equivalent to creation date would make sure the structure diagrams are nonetheless related despite service updates and releases. The next determine reveals the structure diagram to the picture search resolution.
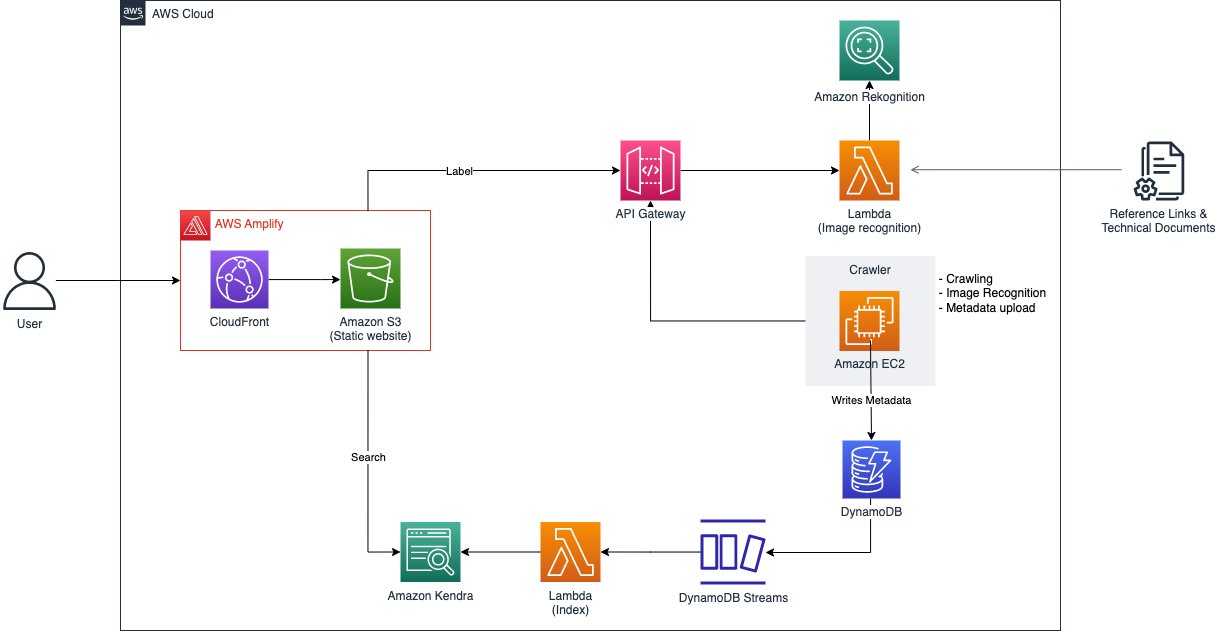
As illustrated within the previous diagram and within the resolution overview, there are two major points of the answer. The primary facet is carried out by Amazon Rekognition, which may establish objects, individuals, textual content, scenes, and actions from pictures or movies. It consists of pre-trained fashions that may be utilized to research pictures and movies at scale. With its customized labels function, Amazon Rekognition means that you can tailor the ML service to your particular enterprise wants by labeling pictures collated from sourcing via structure diagrams in trusted reference hyperlinks and technical paperwork. By importing a small set of coaching pictures, Amazon Rekognition routinely masses and inspects the coaching knowledge, selects the correct ML algorithms, trains a mannequin, and offers mannequin efficiency metrics. Due to this fact, customers with out ML experience can take pleasure in the advantages of a customized labels mannequin via an API name, as a result of a big quantity of overhead is lowered. The answer applies Amazon Rekognition Customized Labels to detect AWS service logos on structure diagrams to permit the structure diagrams to be searchable with service names. After modeling, detected companies of every structure diagram picture and its metadata, like URL origin and picture title, are listed for future search functions and saved in Amazon DynamoDB, a completely managed, serverless, key-value NoSQL database designed to run high-performance purposes.
The second facet is supported by Amazon Kendra, an clever enterprise search service powered by ML that means that you can search throughout totally different content material repositories. With Amazon Kendra, you may seek for outcomes, equivalent to pictures or paperwork, which have been listed. These outcomes will also be saved throughout totally different repositories as a result of the search service employs built-in connectors. Key phrases, phrases, and descriptions could possibly be used for looking, which lets you precisely seek for diagrams which are associated to a selected use case. Due to this fact, you may simply construct an clever search service with minimal improvement prices.
With an understanding of the issue and resolution, the next sections dive into how one can automate knowledge sourcing via the crawling of structure diagrams from credible sources. Following this, we stroll via the method of producing a customized label ML mannequin with a completely managed service. Lastly, we cowl the info ingestion by an clever search service, powered by ML.
Create an Amazon Rekognition mannequin with customized labels
Earlier than acquiring any structure diagrams, we’d like a instrument to judge if a picture might be recognized as an structure diagram. Amazon Rekognition Customized Labels offers a streamlined course of to create a picture recognition mannequin that identifies objects and scenes in pictures which are particular to a enterprise want. On this case, we use Amazon Rekognition Customized Labels to establish AWS service icons, then the photographs are listed with the companies for a extra related search utilizing Amazon Kendra. This mannequin doesn’t differentiate whether or not an image is an structure diagram or not; it merely identifies service icons, if any. As such, there could also be cases the place pictures that aren’t structure diagrams find yourself within the search outcomes. Nevertheless, such outcomes are minimal.
The next determine reveals the steps that this resolution takes to create an Amazon Rekognition Customized Labels mannequin.

This course of includes importing the datasets, producing a manifest file that references the uploaded datasets, adopted by importing this manifest file into Amazon Rekognition. A Python script is used to help within the strategy of importing the datasets and producing the manifest file. Upon efficiently producing the manifest file, it’s then uploaded into Amazon Rekognition to start the mannequin coaching course of. For particulars on the Python script and how one can run it, confer with the GitHub repo.
To coach the mannequin, within the Amazon Rekognition challenge, select Prepare mannequin, choose the challenge you wish to prepare, then add any related tags and select Prepare mannequin. For directions on beginning an Amazon Rekognition Customized Labels challenge, confer with the out there video tutorials. The mannequin might take as much as 8 hours to coach with this dataset.
When the coaching is full, you might select the skilled mannequin to view the analysis outcomes. For extra particulars on the totally different metrics equivalent to precision, recall, and F1, confer with Metrics for evaluation your model. To make use of the mannequin, navigate to the Use Mannequin tab, depart the variety of inference items at 1, and begin the mannequin. Then we will use an AWS Lambda perform to ship pictures to the mannequin in base64, and the mannequin returns an inventory of labels and confidence scores.
Upon efficiently coaching an Amazon Rekognition mannequin with Amazon Rekognition Customized Labels, we will use it to establish service icons within the structure diagrams which have been crawled. To extend the accuracy of figuring out companies within the structure diagram, we use one other Amazon Rekognition function referred to as text detection. To make use of this function, we go in the identical image in base64, and Amazon Rekognition returns the record of textual content recognized within the image. Within the following figures, we evaluate the unique picture and what it appears to be like like after the companies within the picture are recognized. The primary determine reveals the unique picture.

The next determine reveals the unique picture with detected companies.

To make sure scalability, we use a Lambda perform, which might be uncovered via an API endpoint created utilizing Amazon API Gateway. Lambda is a serverless, event-driven compute service that permits you to run code for just about any kind of utility or backend service with out provisioning or managing servers. Utilizing a Lambda perform eliminates a typical concern about scaling up when massive volumes of requests are made to the API endpoint. Lambda routinely runs the perform for the precise API name, which stops when the invocation is full, thereby lowering price incurred to the consumer. As a result of the request could be directed to the Amazon Rekognition endpoint, having solely the Lambda perform being scalable shouldn’t be adequate. To ensure that the Amazon Rekognition endpoint to be scalable, you may enhance the inference unit of the endpoint. For extra particulars on configuring the inference unit, confer with Inference units.
The next is a code snippet of the Lambda perform for the picture recognition course of:
After creating the Lambda perform, we will proceed to show it as an API utilizing API Gateway. For directions on creating an API with Lambda proxy integration, confer with Tutorial: Build a Hello World REST API with Lambda proxy integration.
Crawl the structure diagrams
To ensure that the search function to work feasibly, we’d like a repository of structure diagrams. Nevertheless, these diagrams should originate from credible sources equivalent to AWS Blog and AWS Prescriptive Guidance. Establishing credibility of information sources ensures the underlying implementation and goal of the use instances are correct and properly vetted. The subsequent step is to arrange a crawler that may assist collect many structure diagrams to feed into our repository. We created an online crawler to extract structure diagrams and knowledge equivalent to an outline of the implementation from the related sources. There are a number of ways in which you might obtain constructing such a mechanism; for this instance, we use a program that runs on Amazon Elastic Compute Cloud (Amazon EC2). This system first obtains hyperlinks to weblog posts from an AWS Weblog API. The response returned from the API comprises data of the publish equivalent to title, URL, date, and the hyperlinks to photographs discovered within the publish.
The next is a code snippet of the JavaScript perform for the online crawling course of:
With this mechanism, we will simply crawl tons of and hundreds of pictures from totally different blogs. Nevertheless, we’d like a filter that solely accepts pictures that include content material of an structure diagram, which in our case are icons of AWS companies, to filter out pictures that aren’t structure diagrams.
That is the aim of our Amazon Rekognition mannequin. The diagrams undergo the picture recognition course of, which identifies service icons and determines if it could possibly be thought of as a sound structure diagram.
The next is a code snippet of the perform that sends pictures to the Amazon Rekognition mannequin:
After passing the picture recognition test, the outcomes returned from the Amazon Rekognition mannequin and the data related to it are bundled into their very own metadata. The metadata is then saved in a DynamoDB desk the place the file could be used to ingest into Amazon Kendra.
The next is a code snippet of the perform that shops the metadata of the diagram in DynamoDB:
Ingest metadata into Amazon Kendra
After the structure diagrams undergo the picture recognition course of and the metadata is saved in DynamoDB, we’d like a manner for the diagrams to be searchable whereas referencing the content material within the metadata. The method to that is to have a search engine that may be built-in with the appliance and may deal with a considerable amount of search queries. Due to this fact, we use Amazon Kendra, an clever enterprise search service.
We use Amazon Kendra because the interactive element of the answer is due to its highly effective search capabilities, notably with the usage of pure language. This provides an extra layer of simplicity when customers are trying to find diagrams which are closest to what they’re in search of. Amazon Kendra affords a variety of knowledge sources connectors for ingesting and connecting contents. This resolution makes use of a customized connector to ingest structure diagrams’ data from DynamoDB. To configure a knowledge supply to an Amazon Kendra index, you need to use an current index or create a new index.
The diagrams crawled then need to be ingested into the Amazon Kendra index that has been created. The next determine reveals the move of how the diagrams are listed.

First, the diagrams inserted into DynamoDB create a Put occasion through Amazon DynamoDB Streams. The occasion triggers the Lambda perform that acts as a customized knowledge supply for Amazon Kendra and masses the diagrams into the index. For directions on making a DynamoDB Streams set off for a Lambda perform, confer with Tutorial: Using AWS Lambda with Amazon DynamoDB Streams
After we combine the Lambda perform with DynamoDB, we have to ingest the data of the diagrams despatched to the perform into the Amazon Kendra index. The index accepts knowledge from varied forms of sources, and ingesting objects into the index from the Lambda perform implies that it has to make use of the customized knowledge supply configuration. For directions on making a customized knowledge supply in your index, confer with Custom data source connector.
The next is a code snippet of the Lambda perform for the way a diagram could possibly be listed in a customized method:
The necessary issue that allows diagrams to be searchable is the Blob key in a doc. That is what Amazon Kendra appears to be like into when customers present their search enter. On this instance code, the Blob key comprises a summarized model of the use case of the diagram concatenated with the data detected from the picture recognition course of. This permits customers to seek for structure diagrams primarily based on use instances equivalent to “Fraud Detection” or by service names like “Amazon Kendra.”
As an instance an instance of what the Blob key appears to be like like, the next snippet references the preliminary ETL diagram that we launched earlier on this publish. It comprises an outline of the diagram that was obtained when it was crawled, in addition to the companies that have been recognized by the Amazon Rekognition mannequin.
Search with Amazon Kendra
After we put all of the elements collectively, the outcomes of an instance search of “actual time analytics” appear like the next screenshot.

By trying to find this use case, it produces totally different structure diagrams. Customers are supplied with these totally different strategies of the precise workload that they’re attempting to implement.
Clear up
Full the steps on this part to wash up the sources you created as a part of this publish:
- Delete the API:
- On the API Gateway console, choose the API to be deleted.
- On the Actions menu, select Delete.
- Select Delete to substantiate.
- Delete the DynamoDB desk:
- On the DynamoDB console, select Tables within the navigation pane.
- Choose the desk you created and select Delete.
- Enter delete when prompted for affirmation.
- Select Delete desk to substantiate.
- Delete the Amazon Kendra index:
- On the Amazon Kendra console, select Indexes within the navigation pane.
- Choose the index you created and select Delete
- Enter a purpose when prompted for affirmation.
- Select Delete to substantiate.
- Delete the Amazon Rekognition challenge:
- On the Amazon Rekognition console, select Use Customized Labels within the navigation pane, then select Initiatives.
- Choose the challenge you created and select Delete.
- Enter Delete when prompted for affirmation.
- Select Delete related datasets and fashions to substantiate.
- Delete the Lambda perform:
- On the Lambda console, choose the perform to be deleted.
- On the Actions menu, select Delete.
- Enter Delete when prompted for affirmation.
- Select Delete to substantiate.
Abstract
On this publish, we confirmed an instance of how one can intelligently search data from pictures. This consists of the method of coaching an Amazon Rekognition ML mannequin that acts as a filter for pictures, the automation of picture crawling, which ensures credibility and effectivity, and querying for diagrams by attaching a customized knowledge supply that allows a extra versatile method to index objects. To dive deeper into the implementation of the codes, confer with the GitHub repo.
Now that you just perceive how one can ship the spine of a centralized search repository for complicated searches, strive creating your personal picture search engine. For extra data on the core options, confer with Getting started with Amazon Rekognition Custom Labels, Moderating content, and the Amazon Kendra Developer Guide. In the event you’re new to Amazon Rekognition Customized Labels, strive it out utilizing our Free Tier, which lasts 3 months and consists of 10 free coaching hours per 30 days and 4 free inference hours per 30 days.
In regards to the Authors
 Ryan See is a Options Architect at AWS. Based mostly in Singapore, he works with prospects to construct options to resolve their enterprise issues in addition to tailor a technical imaginative and prescient to assist run extra scalable and environment friendly workloads within the cloud.
Ryan See is a Options Architect at AWS. Based mostly in Singapore, he works with prospects to construct options to resolve their enterprise issues in addition to tailor a technical imaginative and prescient to assist run extra scalable and environment friendly workloads within the cloud.
 James Ong Jia Xiang is a Buyer Options Supervisor at AWS. He specializes within the Migration Acceleration Program (MAP) the place he helps prospects and companions efficiently implement large-scale migration packages to AWS. Based mostly in Singapore, he additionally focuses on driving modernization and enterprise transformation initiatives throughout APJ via scalable mechanisms. For leisure, he enjoys nature actions like trekking and browsing.
James Ong Jia Xiang is a Buyer Options Supervisor at AWS. He specializes within the Migration Acceleration Program (MAP) the place he helps prospects and companions efficiently implement large-scale migration packages to AWS. Based mostly in Singapore, he additionally focuses on driving modernization and enterprise transformation initiatives throughout APJ via scalable mechanisms. For leisure, he enjoys nature actions like trekking and browsing.
 Dangle Duong is a Options Architect at AWS. Based mostly in Hanoi, Vietnam, she focuses on driving cloud adoption throughout her nation by offering extremely out there, safe, and scalable cloud options for her prospects. Moreover, she enjoys constructing and is concerned in varied prototyping tasks. She can be passionate concerning the subject of machine studying.
Dangle Duong is a Options Architect at AWS. Based mostly in Hanoi, Vietnam, she focuses on driving cloud adoption throughout her nation by offering extremely out there, safe, and scalable cloud options for her prospects. Moreover, she enjoys constructing and is concerned in varied prototyping tasks. She can be passionate concerning the subject of machine studying.
 Trinh Vo is a Options Architect at AWS, primarily based in Ho Chi Minh Metropolis, Vietnam. She focuses on working with prospects throughout totally different industries and companions in Vietnam to craft architectures and demonstrations of the AWS platform that work backward from the shopper’s enterprise wants and speed up the adoption of acceptable AWS know-how. She enjoys caving and trekking for leisure.
Trinh Vo is a Options Architect at AWS, primarily based in Ho Chi Minh Metropolis, Vietnam. She focuses on working with prospects throughout totally different industries and companions in Vietnam to craft architectures and demonstrations of the AWS platform that work backward from the shopper’s enterprise wants and speed up the adoption of acceptable AWS know-how. She enjoys caving and trekking for leisure.
 Wai Kin Tham is a Cloud Architect at AWS. Based mostly in Singapore, his day job includes serving to prospects migrate to the cloud and modernize their know-how stack within the cloud. In his free time, he attends Muay Thai and Brazilian Jiu Jitsu lessons.
Wai Kin Tham is a Cloud Architect at AWS. Based mostly in Singapore, his day job includes serving to prospects migrate to the cloud and modernize their know-how stack within the cloud. In his free time, he attends Muay Thai and Brazilian Jiu Jitsu lessons.





