Obtain excessive efficiency with lowest value for generative AI inference utilizing AWS Inferentia2 and AWS Trainium on Amazon SageMaker

The world of synthetic intelligence (AI) and machine studying (ML) has been witnessing a paradigm shift with the rise of generative AI fashions that may create human-like textual content, pictures, code, and audio. In comparison with classical ML fashions, generative AI fashions are considerably greater and extra advanced. Nevertheless, their rising complexity additionally comes with excessive prices for inference and a rising want for highly effective compute sources. The excessive value of inference for generative AI fashions generally is a barrier to entry for companies and researchers with restricted sources, necessitating the necessity for extra environment friendly and cost-effective options. Moreover, the vast majority of generative AI use circumstances contain human interplay or real-world situations, necessitating {hardware} that may ship low-latency efficiency. AWS has been innovating with purpose-built chips to deal with the rising want for highly effective, environment friendly, and cost-effective compute {hardware}.
Right this moment, we’re excited to announce that Amazon SageMaker helps AWS Inferentia2 (ml.inf2) and AWS Trainium (ml.trn1) primarily based SageMaker situations to host generative AI fashions for real-time and asynchronous inference. ml.inf2 situations can be found for mannequin deployment on SageMaker in US East (Ohio) and ml.trn1 situations in US East (N. Virginia).
You should use these situations on SageMaker to attain excessive efficiency at a low value for generative AI fashions, together with massive language fashions (LLMs), Secure Diffusion, and imaginative and prescient transformers. As well as, you need to use Amazon SageMaker Inference Recommender that will help you run load checks and consider the price-performance advantages of deploying your mannequin on these situations.
You should use ml.inf2 and ml.trn1 situations to run your ML purposes on SageMaker for textual content summarization, code era, video and picture era, speech recognition, personalization, fraud detection, and extra. You possibly can simply get began by specifying ml.trn1 or ml.inf2 situations when configuring your SageMaker endpoint. You should use ml.trn1 and ml.inf2 appropriate AWS Deep Studying Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and huge mannequin inference (LMI) to simply get began. For the total record with variations, see Available Deep Learning Containers Images.
On this publish, we present the method of deploying a big language mannequin on AWS Inferentia2 utilizing SageMaker, with out requiring any further coding, by benefiting from the LMI container. We use the GPT4ALL-J, a fine-tuned GPT-J 7B mannequin that gives a chatbot fashion interplay.
Overview of ml.trn1 and ml.inf2 situations
ml.trn1 situations are powered by the Trainium accelerator, which is goal constructed primarily for high-performance deep studying coaching of generative AI fashions, together with LLMs. Nevertheless, these situations additionally help inference workloads for fashions which might be even bigger than what matches into Inf2. The biggest occasion dimension, trn1.32xlarge situations, options 16 Trainium accelerators with 512 GB of accelerator reminiscence in a single occasion delivering as much as 3.4 petaflops of FP16/BF16 compute energy. 16 Trainium accelerators are linked with ultra-high-speed NeuronLinkv2 for streamlined collective communications.
ml.Inf2 situations are powered by the AWS Inferentia2 accelerator, a goal constructed accelerator for inference. It delivers 3 times larger compute efficiency, as much as 4 occasions larger throughput, and as much as 10 occasions decrease latency in comparison with first-generation AWS Inferentia. The biggest occasion dimension, Inf2.48xlarge, options 12 AWS Inferentia2 accelerators with 384 GB of accelerator reminiscence in a single occasion for a mixed compute energy of two.3 petaflops for BF16/FP16. It lets you deploy as much as a 175-billion-parameter mannequin in a single occasion. Inf2 is the one inference-optimized occasion to supply this interconnect, a function that’s solely out there in dearer coaching situations. For ultra-large fashions that don’t match right into a single accelerator, information flows instantly between accelerators with NeuronLink, bypassing the CPU utterly. With NeuronLink, Inf2 helps sooner distributed inference and improves throughput and latency.
Each AWS Inferentia2 and Trainium accelerators have two NeuronCores-v2, 32 GB HBM reminiscence stacks, and devoted collective-compute engines, which mechanically optimize runtime by overlapping computation and communication when doing multi-accelerator inference. For extra particulars on the structure, discuss with Trainium and Inferentia devices.
The next diagram reveals an instance structure utilizing AWS Inferentia2.

AWS Neuron SDK
AWS Neuron is the SDK used to run deep studying workloads on AWS Inferentia and Trainium primarily based situations. AWS Neuron features a deep studying compiler, runtime, and instruments which might be natively built-in into TensorFlow and PyTorch. With Neuron, you’ll be able to develop, profile, and deploy high-performance ML workloads on ml.trn1 and ml.inf2.
The Neuron Compiler accepts ML fashions in numerous codecs (TensorFlow, PyTorch, XLA HLO) and optimizes them to run on Neuron units. The Neuron compiler is invoked throughout the ML framework, the place ML fashions are despatched to the compiler by the Neuron framework plugin. The ensuing compiler artifact is named a NEFF file (Neuron Executable File Format) that in flip is loaded by the Neuron runtime to the Neuron system.
The Neuron runtime consists of kernel driver and C/C++ libraries, which give APIs to entry AWS Inferentia and Trainium Neuron units. The Neuron ML frameworks plugins for TensorFlow and PyTorch use the Neuron runtime to load and run fashions on the NeuronCores. The Neuron runtime hundreds compiled deep studying fashions (NEFF) to the Neuron units and is optimized for top throughput and low latency.
Host NLP fashions utilizing SageMaker ml.inf2 situations
Earlier than we dive deep into serving LLMs with transformers-neuronx, which is an open-source library to shard the mannequin’s massive weight matrices onto a number of NeuronCores, let’s briefly undergo the everyday deployment stream for a mannequin that may match onto the one NeuronCore.
Test the list of supported models to make sure the mannequin is supported on AWS Inferentia2. Subsequent, the mannequin must be pre-compiled by the Neuron Compiler. You should use a SageMaker pocket book or an Amazon Elastic Compute Cloud (Amazon EC2) occasion to compile the mannequin. You should use the SageMaker Python SDK to deploy fashions utilizing fashionable deep studying frameworks equivalent to PyTorch, as proven within the following code. You possibly can deploy your mannequin to SageMaker internet hosting providers and get an endpoint that can be utilized for inference. These endpoints are absolutely managed and help auto scaling.
Confer with Developer Flows for extra particulars on typical growth flows of Inf2 on SageMaker with pattern scripts.
Host LLMs utilizing SageMaker ml.inf2 situations
Giant language fashions with billions of parameters are sometimes too large to suit on a single accelerator. This necessitates the usage of mannequin parallel strategies for internet hosting LLMs throughout a number of accelerators. One other essential requirement for internet hosting LLMs is the implementation of a high-performance model-serving resolution. This resolution ought to effectively load the mannequin, handle partitioning, and seamlessly serve requests through HTTP endpoints.
SageMaker consists of specialised deep studying containers (DLCs), libraries, and tooling for mannequin parallelism and huge mannequin inference. For sources to get began with LMI on SageMaker, discuss with Model parallelism and large model inference. SageMaker maintains DLCs with fashionable open-source libraries for internet hosting massive fashions equivalent to GPT, T5, OPT, BLOOM, and Secure Diffusion on AWS infrastructure. These specialised DLCs are known as SageMaker LMI containers.
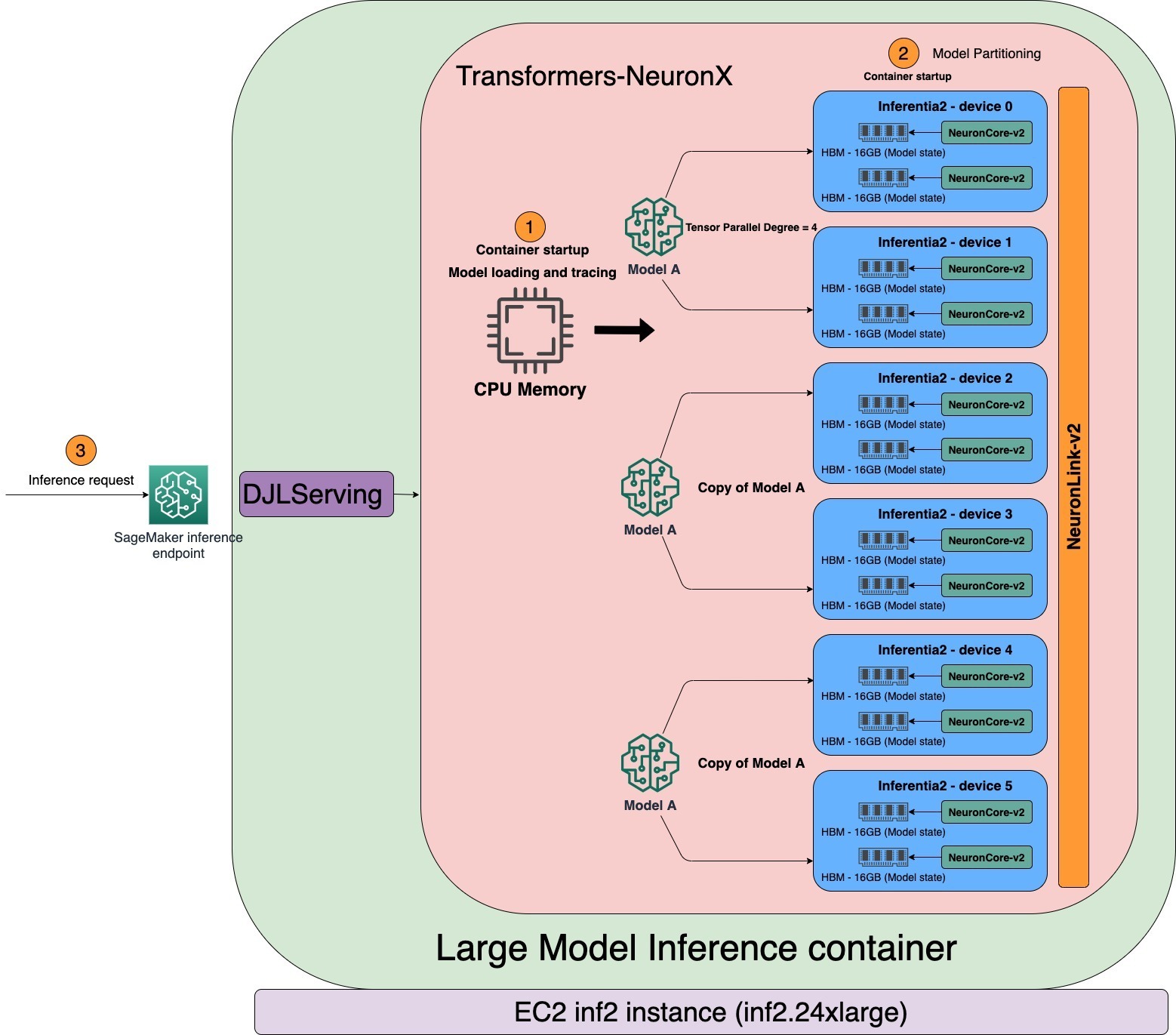
SageMaker LMI containers use DJLServing, a mannequin server that’s built-in with the transformers-neuronx library to help tensor parallelism throughout NeuronCores. To be taught extra about how DJLServing works, discuss with Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference. The DJL mannequin server and transformers-neuronx library function core elements of the container, which additionally consists of the Neuron SDK. This setup facilitates the loading of fashions onto AWS Inferentia2 accelerators, parallelizes the mannequin throughout a number of NeuronCores, and allows serving through HTTP endpoints.
The LMI container helps loading fashions from an Amazon Simple Storage Service (Amazon S3) bucket or Hugging Face Hub. The default handler script hundreds the mannequin, compiles and converts it right into a Neuron-optimized format, and hundreds it. To make use of the LMI container to host LLMs, we’ve got two choices:
- A no-code (most popular) – That is the best technique to deploy an LLM utilizing an LMI container. On this technique, you need to use the supplied default handler and simply move the mannequin title and the parameters required in
serving.propertiesfile to load and host the mannequin. To make use of the default handler, we offer theentryPointparameter asdjl_python.transformers-neuronx. - Deliver your individual script – On this strategy, you’ve the choice to create your individual mannequin.py file, which incorporates the code essential for loading and serving the mannequin. This file acts as an middleman between the
DJLServingAPIs and thetransformers-neuronxAPIs. To customise the mannequin loading course of, you’ll be able to presentserving.propertieswith configurable parameters. For a complete record of obtainable configurable parameters, discuss with All DJL configuration options. Right here is an instance of a model.py file.
Runtime structure
The tensor_parallel_degree property worth determines the distribution of tensor parallel modules throughout a number of NeuronCores. For example, inf2.24xlarge has six AWS Inferentia2 accelerators. Every AWS Inferentia2 accelerator has two NeuronCores. Every NeuronCore has a devoted excessive bandwidth reminiscence (HBM) of 16 GB storing tensor parallel modules. With a tensor parallel diploma of 4, the LMI will allocate three mannequin copies of the identical mannequin, every using 4 NeuronCores. As proven within the following diagram, when the LMI container begins, the mannequin can be loaded and traced first within the CPU addressable reminiscence. When the tracing is full, the mannequin is partitioned throughout the NeuronCores primarily based on the tensor parallel diploma.
LMI makes use of DJLServing as its mannequin serving stack. After the container’s well being verify passes in SageMaker, the container is able to serve the inference request. DJLServing launches a number of Python processes equal to the TOTAL NUMBER OF NEURON CORES/TENSOR_PARALLEL_DEGREE. Every Python course of incorporates threads in C++ equal to TENSOR_PARALLEL_DEGREE. Every C++ threads holds one shard of the mannequin on one NeuronCore.
Many practitioners (Python course of) are likely to run inference sequentially when the server is invoked with a number of impartial requests. Though it’s simpler to arrange, it’s normally not the most effective observe to make the most of the accelerator’s compute energy. To deal with this, DJLServing affords the built-in optimizations of dynamic batching to mix these impartial inference requests on the server aspect to type a bigger batch dynamically to extend throughput. All of the requests attain the dynamic batcher first earlier than getting into the precise job queues to attend for inference. You possibly can set your most popular batch sizes for dynamic batching utilizing the batch_size settings in serving.properties. You may also configure max_batch_delay to specify the utmost delay time within the batcher to attend for different requests to affix the batch primarily based in your latency necessities. The throughput additionally will depend on the variety of mannequin copies and the Python course of teams launched within the container. As proven within the following diagram, with the tensor parallel diploma set to 4, the LMI container launches three Python course of teams, every holding the total copy of the mannequin. This lets you improve the batch dimension and get larger throughput.
SageMaker pocket book for deploying LLMs
On this part, we offer a step-by-step walkthrough of deploying GPT4All-J, a 6-billion-parameter mannequin that’s 24 GB in FP32. GPT4All-J is a well-liked chatbot that has been skilled on an unlimited number of interplay content material like phrase issues, dialogs, code, poems, songs, and tales. GPT4all-J is a fine-tuned GPT-J mannequin that generates responses much like human interactions.
The whole pocket book for this instance is supplied on GitHub. We will use the SageMaker Python SDK to deploy the mannequin to an Inf2 occasion. We use the supplied default handler to load the mannequin. With this, we simply want to offer a servings.properties file. This file has the required configurations for the DJL mannequin server to obtain and host the mannequin. We will specify the title of the Hugging Face mannequin utilizing the model_id parameter to obtain the mannequin instantly from the Hugging Face repo. Alternatively, you’ll be able to obtain the mannequin from Amazon S3 by offering the s3url parameter. The entryPoint parameter is configured to level to the library to load the mannequin. For extra particulars on djl_python.fastertransformer, discuss with the GitHub code.
The tensor_parallel_degree property worth determines the distribution of tensor parallel modules throughout a number of units. For example, with 12 NeuronCores and a tensor parallel diploma of 4, LMI will allocate three mannequin copies, every using 4 NeuronCores. You may also outline the precision kind utilizing the property dtype. n_position parameter defines the sum of max enter and output sequence size for the mannequin. See the next code:
Assemble the tarball containing serving.properties and add it to an S3 bucket. Though the default handler is used on this instance, you’ll be able to develop a mannequin.py file for customizing the loading and serving course of. If there are any packages that want set up, embody them within the necessities.txt file. See the next code:
Retrieve the DJL container picture and create the SageMaker mannequin:
Subsequent, we create the SageMaker endpoint with the mannequin configuration outlined earlier. The container downloads the mannequin into the /tmp house as a result of SageMaker maps the /tmp to Amazon Elastic Block Store (Amazon EBS). We have to add a volume_size parameter to make sure the /tmp listing has sufficient house to obtain and compile the mannequin. We set container_startup_health_check_timeout to three,600 seconds to make sure the well being verify begins after the mannequin is prepared. We use the ml.inf2.8xlarge occasion. See the next code:
After the SageMaker endpoint has been created, we will make real-time predictions in opposition to SageMaker endpoints utilizing the Predictor object:
Clear up
Delete the endpoints to avoid wasting prices after you end your checks:
Conclusion
On this publish, we showcased the newly launched functionality of SageMaker, which now helps ml.inf2 and ml.trn1 situations for internet hosting generative AI fashions. We demonstrated learn how to deploy GPT4ALL-J, a generative AI mannequin, on AWS Inferentia2 utilizing SageMaker and the LMI container, with out writing any code. We additionally showcased how you need to use DJLServing and transformers-neuronx to load a mannequin, partition it, and serve.
Inf2 situations present essentially the most cost-effective technique to run generative AI fashions on AWS. For efficiency particulars, discuss with Inf2 Performance.
Take a look at the GitHub repo for an instance pocket book. Attempt it out and tell us when you have any questions!
Concerning the Authors
 Vivek Gangasani is a Senior Machine Studying Options Architect at Amazon Internet Providers. He works with Machine Studying Startups to construct and deploy AI/ML purposes on AWS. He’s at the moment centered on delivering options for MLOps, ML Inference and low-code ML. He has labored on tasks in numerous domains, together with Pure Language Processing and Laptop Imaginative and prescient.
Vivek Gangasani is a Senior Machine Studying Options Architect at Amazon Internet Providers. He works with Machine Studying Startups to construct and deploy AI/ML purposes on AWS. He’s at the moment centered on delivering options for MLOps, ML Inference and low-code ML. He has labored on tasks in numerous domains, together with Pure Language Processing and Laptop Imaginative and prescient.
 Hiroshi Tokoyo is a Options Architect at AWS Annapurna Labs. Primarily based in Japan, he joined Annapurna Labs even earlier than the acquisition by AWS and has persistently helped clients with Annapurna Labs know-how. His latest focus is on Machine Studying options primarily based on purpose-built silicon, AWS Inferentia and Trainium.
Hiroshi Tokoyo is a Options Architect at AWS Annapurna Labs. Primarily based in Japan, he joined Annapurna Labs even earlier than the acquisition by AWS and has persistently helped clients with Annapurna Labs know-how. His latest focus is on Machine Studying options primarily based on purpose-built silicon, AWS Inferentia and Trainium.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Laptop Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
 Qing Lan is a Software program Improvement Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s group efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth information on the infrastructure optimization and Deep Studying acceleration.
Qing Lan is a Software program Improvement Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s group efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth information on the infrastructure optimization and Deep Studying acceleration.
 Qingwei Li is a Machine Studying Specialist at Amazon Internet Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. At the moment he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.
Qingwei Li is a Machine Studying Specialist at Amazon Internet Providers. He acquired his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and did not ship the Nobel Prize he promised. At the moment he helps clients within the monetary service and insurance coverage business construct machine studying options on AWS. In his spare time, he likes studying and educating.
 Alan Tan is a Senior Product Supervisor with SageMaker main efforts on massive mannequin inference. He’s captivated with making use of Machine Studying to the realm of Analytics. Exterior of labor, he enjoys the outside.
Alan Tan is a Senior Product Supervisor with SageMaker main efforts on massive mannequin inference. He’s captivated with making use of Machine Studying to the realm of Analytics. Exterior of labor, he enjoys the outside.
 Varun Syal is a Software program Improvement Engineer with AWS Sagemaker engaged on essential buyer dealing with options for the ML Inference platform. He’s captivated with working within the Distributed Programs and AI house. In his spare time, he likes studying and gardening.
Varun Syal is a Software program Improvement Engineer with AWS Sagemaker engaged on essential buyer dealing with options for the ML Inference platform. He’s captivated with working within the Distributed Programs and AI house. In his spare time, he likes studying and gardening.






