Stability AI Launches DeepFloyd IF: A Excessive-Efficiency Textual content-to-Picture Mannequin with Superior Integration Capabilities
Stability AI has partnered with its AI analysis lab DeepFloyd to introduce the analysis model of its newest know-how, known as DeepFloyd IF. This text-to-image cascaded pixel diffusion mannequin is designed to generate high-quality pictures from textual content inputs. The mannequin is offered on a non-commercial, research-permissible license, enabling analysis labs to discover and experiment with superior text-to-image technology strategies. This mannequin’s launch aligns with Stability AI’s dedication to sharing progressive applied sciences with the broader analysis neighborhood. The corporate plans to launch the DeepFloyd IF mannequin totally open supply finally.
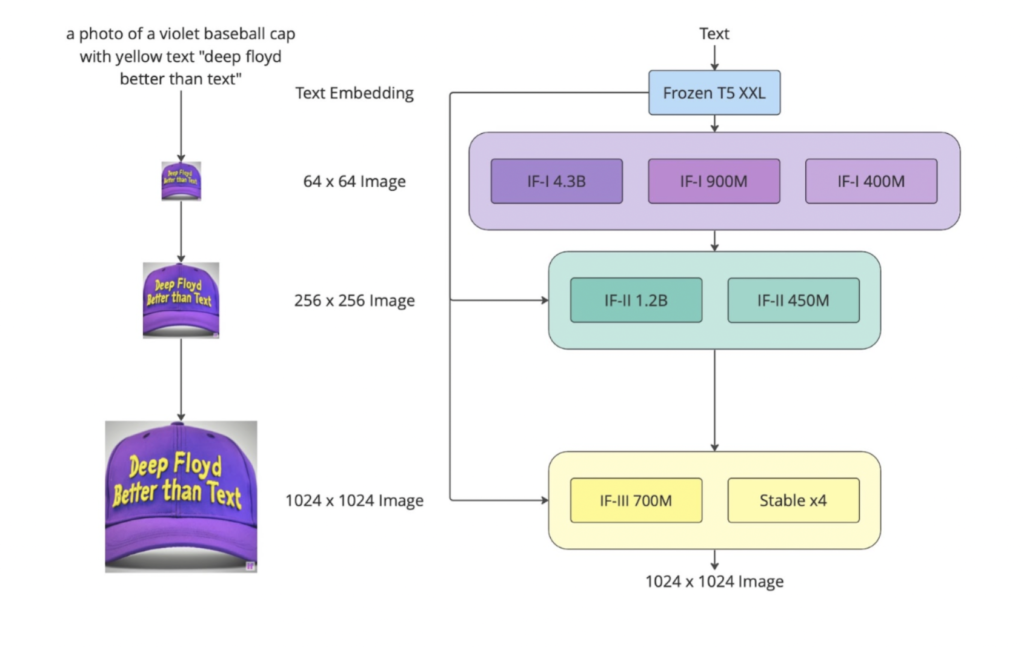
The newly launched DeepFloyd IF mannequin boasts a number of spectacular options. Firstly, it makes use of the T5-XXL-1.1 language mannequin as a textual content encoder to help in understanding textual content prompts. The mannequin additionally employs cross-attention layers to higher align the textual content immediate and the generated picture. One of many standout options of the DeepFloyd IF mannequin is its potential to precisely apply textual content descriptions to generate pictures with numerous objects showing in several spatial relations. This has beforehand been a difficult job for different text-to-image fashions. One other noteworthy function is the excessive diploma of photorealism within the generated pictures, mirrored within the mannequin’s spectacular zero-shot FID rating of 6.66 on the COCO dataset. The DeepFloyd IF mannequin can also generate pictures with non-standard facet ratios, together with vertical or horizontal orientations and the usual sq. facet.
Along with text-to-image technology, the DeepFloyd IF mannequin affords zero-shot image-to-image translations. That is achieved by resizing the unique picture to 64 pixels, including noise by means of ahead diffusion, and utilizing backward diffusion with a brand new immediate to denoise the picture. The fashion may be modified by means of super-resolution modules by way of a immediate textual content description. This strategy permits for the modification of favor, patterns, and particulars within the output picture whereas sustaining the first type of the supply picture with out the necessity for fine-tuning.
The DeepFloyd IF mannequin works in three levels to generate high-quality pictures from textual content prompts. A frozen T5-XXL language mannequin converts the textual content immediate right into a qualitative illustration within the first stage. Then, within the second stage, a base diffusion mannequin is utilized to remodel the qualitative textual content right into a 64×64 picture, which is then upscaled to 256×256 utilizing two text-conditional super-resolution fashions. Through the third stage of the method, a remaining mannequin is used to boost the picture to a transparent and high-quality 1024×1024 decision. The IF mannequin consists of totally different variations of the bottom and super-resolution fashions, which produce other parameters. Though the third-stage mannequin has but to be obtainable, different upscale fashions just like the Secure Diffusion x4 Upscaler may be utilized.
The DeepFloyd IF mannequin was skilled on a high-quality customized dataset known as LAION-A, which accommodates 1 billion (picture, textual content) pairs. The dataset is an aesthetic subset of the English a part of the LAION-5B dataset, and the information had been filtered utilizing customized filters to take away inappropriate content material. The mannequin is initially launched beneath a analysis license, and the creators welcome suggestions to enhance the mannequin’s efficiency and scalability. The mannequin can be utilized in numerous domains, reminiscent of artwork, design, storytelling, digital actuality, and accessibility. The creators pose a number of analysis questions associated to the mannequin’s technical, educational, and moral facets. Entry to the mannequin’s weights is offered on Deep Floyd’s Hugging Face space, and the mannequin card and code are additionally obtainable on GitHub. A Gradio demo is supplied for everybody, and the creators invite folks to affix public discussions.
Don’t overlook to affix our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd yr undergraduate, at the moment pursuing her B.Tech from Indian Institute of Expertise(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the most recent developments in these fields.