Put together picture information with Amazon SageMaker Knowledge Wrangler
The fast adoption of good telephones and different cell platforms has generated an infinite quantity of picture information. In accordance with Gartner, unstructured information now represents 80–90% of all new enterprise information, however simply 18% of organizations are benefiting from this information. That is primarily on account of a lack of know-how and the big quantity of effort and time that’s required to sift by way of all that info to determine high quality information and helpful insights.
Earlier than you should use picture information for labeling, coaching, or inference, it first must be cleaned (deduplicate, drop corrupted photographs or outliers, and so forth), analyzed (resembling group photographs primarily based on sure attributes), standardized (resize, change orientation, standardize lighting and coloration, and so forth), and augmented for higher labeling, coaching, or inference outcomes (improve distinction, blur some irrelevant objects, upscale, and so forth).
Right now, we’re blissful to announce that with Amazon SageMaker Data Wrangler, you may carry out picture information preparation for machine studying (ML) utilizing little to no code.
Knowledge Wrangler reduces the time it takes to mixture and put together information for ML from weeks to minutes. With Knowledge Wrangler, you may simplify the method of information preparation and have engineering, and full every step of the info preparation workflow (together with information choice, cleaning, exploration, visualization, and processing at scale) from a single visible interface.
Knowledge Wrangler’s picture information preparation function addresses your wants through a visible UI for picture preview, import, transformation, and export. You may browse, import, and remodel picture information similar to how you utilize Knowledge Wrangler for tabular information. On this put up, we present an instance of how one can use this function.
Resolution overview
For this put up, we give attention to the Knowledge Wrangler element of picture processing, which we use to assist a picture classification mannequin detect crashes with higher high quality photographs. We use the next companies:
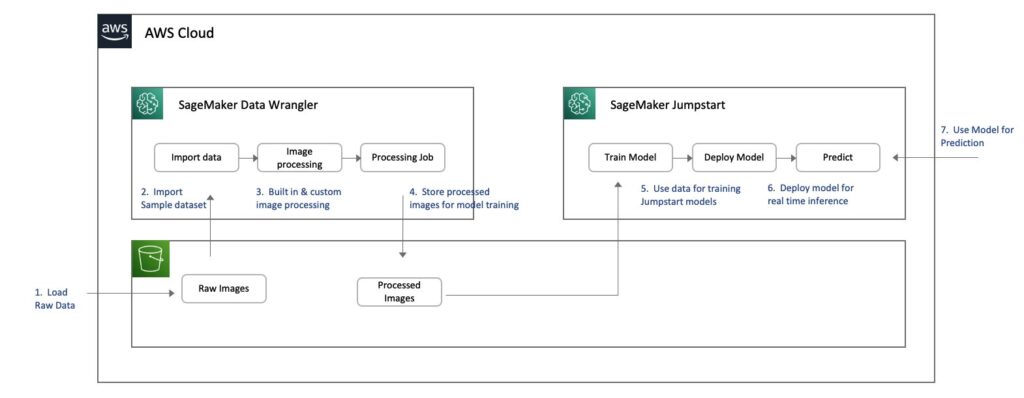
The next diagram illustrates the answer structure.

Knowledge Wrangler is a SageMaker function out there inside Studio. You may comply with the Studio onboarding process to spin up the Studio atmosphere and notebooks. Though you may select from just a few authentication strategies, the best method to create a Studio area is to comply with the Quick start instructions. The Fast begin makes use of the identical default settings as the usual Studio setup. It’s also possible to select to onboard utilizing AWS IAM Identity Center (successor to AWS Single Signal-On) for authentication (see Onboard to Amazon SageMaker Domain Using IAM Identity Center).
For this use case, we use CCTV footage information of accidents and non-accidents out there from Kaggle. The dataset incorporates frames captured from YouTube movies of accidents and non-accidents. The photographs are cut up into prepare, take a look at, and validation folders.
Stipulations
As a prerequisite, obtain the sample dataset and add it to an Amazon Simple Storage Service (Amazon S3) bucket. We use this dataset for picture processing and subsequently for coaching a customized mannequin.
Course of photographs utilizing Knowledge Wrangler
Begin your Studio atmosphere and create a brand new Data Wrangler flow referred to as car_crash_detection_data.movement. Now let’s import the dataset to Knowledge Wrangler from the S3 bucket the place the dataset was uploaded. Knowledge Wrangler lets you import datasets from totally different information sources, together with photographs.
Knowledge Wrangler helps quite a lot of built-in transformations for picture processing, together with the next:
- Blur picture – Knowledge Wrangler helps totally different strategies from an open-source picture library (Gaussian, Common, Median, Movement, and extra) for blurring photographs. For particulars of every approach, discuss with augmenters.blur.
- Corrupt picture – Knowledge Wrangler additionally helps totally different corruption strategies (Gaussian noise, Impulse noise, Speckle noise, and extra). For particulars of every approach, discuss with augmenters.imgcorruptlike.
- Improve picture distinction – You may deploy totally different distinction enhancement strategies (Gamma distinction, Sigmoid distinction, Log distinction, Linear distinction, Histogram equalization, and extra). For extra particulars, discuss with augmenters.contrast.
- Resize picture – Knowledge Wrangler helps totally different resizing strategies (cropping, padding, thumbnail, and extra). For extra particulars, discuss with augmenters.size.
On this put up, we spotlight a subset of those functionalities by way of the next steps:
- Add photographs from the supply S3 bucket and preview the picture.
- Create fast picture transformations utilizing the built-in transformers.
- Write customized code like discovering outliers or utilizing the Search Instance Snippets operate.
- Export the ultimate cleansed information to a different S3 bucket.
- Mix photographs from totally different Amazon S3 sources into one Knowledge Wrangler movement.
- Create a job to set off the Knowledge Wrangler movement.
Let’s have a look at every step intimately.
Add photographs from the supply bucket S3 and preview the picture
To add all the pictures underneath one folder, full the next steps:
- Choose the S3 folder containing the pictures.
- For File sort, select Picture.
- Choose Import nested directories.
- Select Import.

You may preview the pictures that you simply’re importing by turning the Preview possibility on. Be aware that Date Wrangler solely imports 100 random photographs for the interactive information preparation.
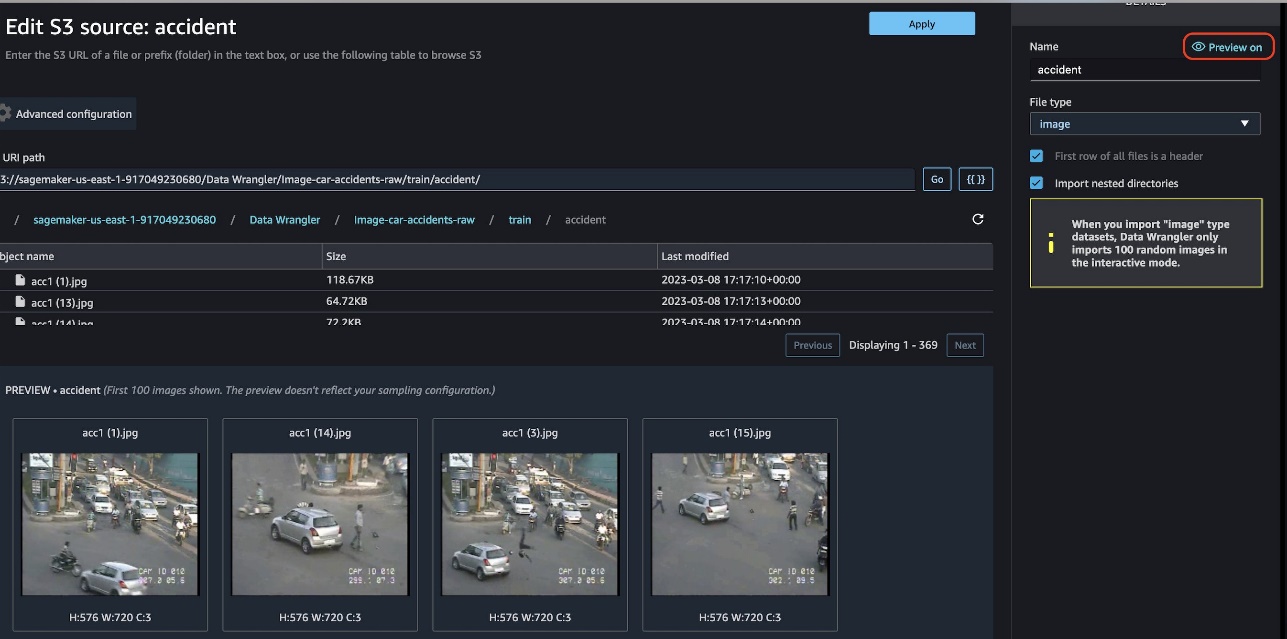
The preview operate lets you view photographs and preview the standard of photographs imported.

For this put up, we load the pictures from each the accident and non-accident folders. We create a set of transformations for every: one movement to deprave photographs, resize, and take away outliers, and one other movement to boost picture distinction, resize, and take away outliers.
Rework photographs utilizing built-in transformations
Picture information transformation is essential to regularize your mannequin community and improve the dimensions of your coaching set. These transformations can change the pictures’ pixel values however nonetheless hold virtually all the knowledge of the picture, so {that a} human might hardly inform whether or not it was augmented or not. This forces the mannequin to be extra versatile with the wide range of objects within the picture, concerning place, orientation, measurement, coloration, and so forth. Fashions skilled with information augmentation normally generalize higher.
Knowledge Wrangler provides you built-in and customized transformations to enhance the standard of photographs for labeling, coaching, or inference. We use a few of these transformations to enhance the picture dataset fed to the mannequin for machine studying.
Corrupt photographs
The primary built-in transformation we use is Corrupt photographs.
We add a step with Corruption set to Impulse noise and set our severity.
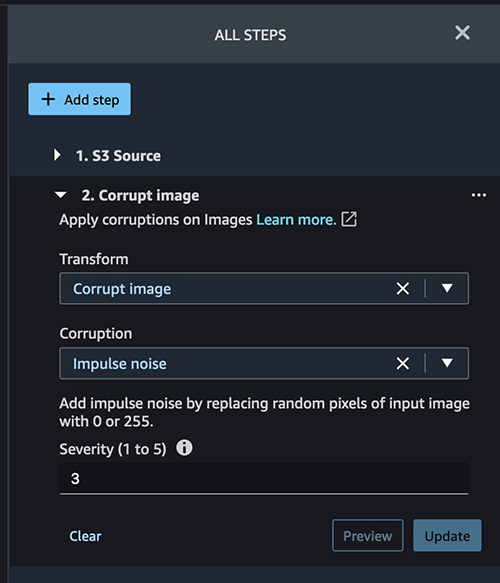
Corrupting a picture or creating any form of noise helps make a mannequin extra strong. The mannequin can predict with extra accuracy even when it receives a corrupted picture as a result of it was skilled with corrupt and non-corrupt photographs.
Improve distinction
We additionally add a remodel to boost the Gamma distinction.

Resize photographs
We are able to use a built-in transformation to resize all the pictures so as to add symmetry. Knowledge Wrangler provides a number of resize choices, as proven within the following screenshot.
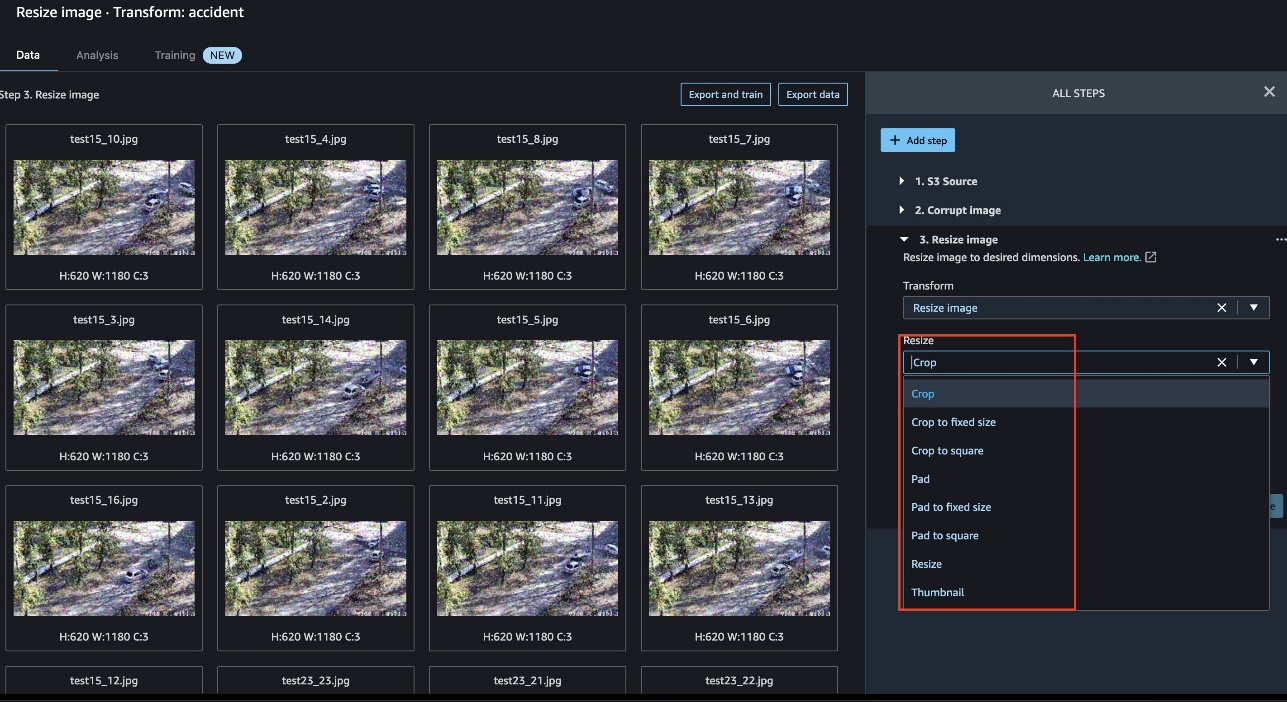
The next instance reveals photographs previous to resize: 720 x 1280.

The next photographs have been resized to 620 x 1180.

Add a customized transformation to detect and take away picture outliers
With picture preparation in Knowledge Wrangler, we will additionally invoke one other endpoint for one more mannequin. You’ll find some pattern scripts with boilerplate code within the Search instance snippets part.
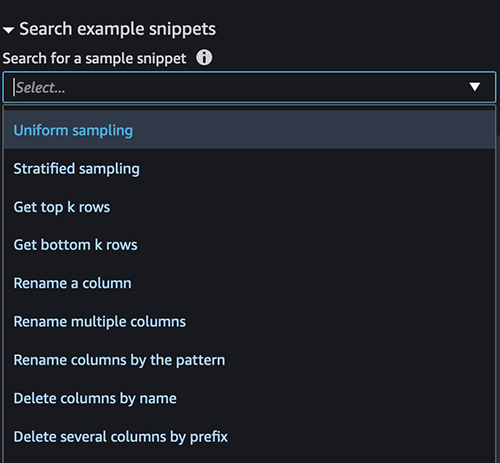
For our instance, we create a brand new transformation to take away outliers. Please observe that this code is only for demonstration function. You could want to change code to swimsuit any manufacturing workload wants.
It is a customized snippet written in PySpark. Earlier than working this step, we have to have a picture embedding mannequin mobile-net (for instance, jumpstart-dft-mobilenet-v2-100-224-featurevector-4). After the endpoint is deployed, we will name a JumpStart mannequin endpoint.
JumpStart fashions resolve widespread ML duties resembling picture classification, object detection, textual content classification, sentence pair classification, and query answering, and can be found for fast mannequin creation and deployment.
To learn to create a picture embedding mannequin in JumpStart, discuss with the GitHub repo. The steps to comply with are just like creating an image classification model with Jumpstart. See the next code:
The next screenshots present an instance of our customized remodel.
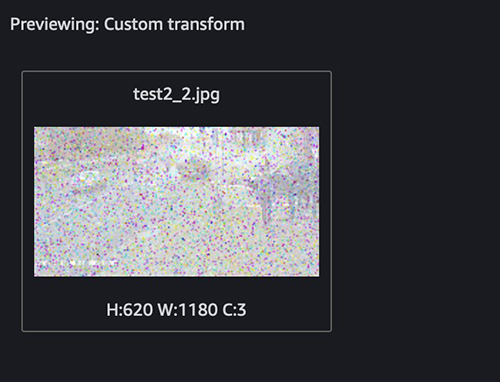
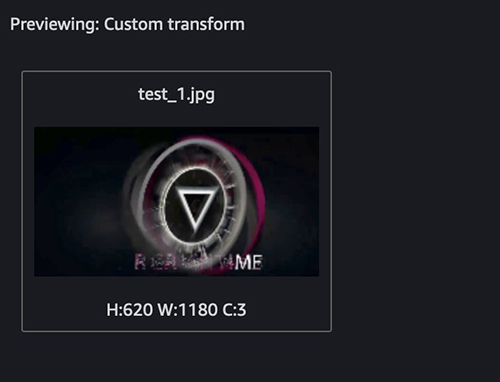
This identifies the outlier. Subsequent, let’s filter out the outlier. You should use the next snippet in the long run of the customized remodel:
Select Preview and Add to avoid wasting the modifications.
Export the ultimate cleansed information to a different S3 bucket
After including all of the transformations, let’s outline the vacation spot in Amazon S3.
Present the situation of your S3 bucket.
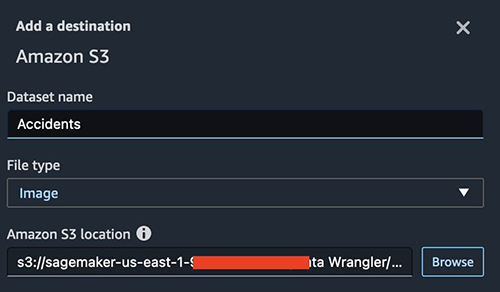
Mix photographs from totally different Amazon S3 sources into one Knowledge Wrangler movement
Within the earlier sections, we processed photographs of accidents. We are able to implement an analogous movement for another photographs (in our case, non-accident photographs). Select Import and comply with the identical steps to create a second movement.
Now we will view the flows for every dataset.

Create a job to run the automated movement
Once we create a job, we scale the recipe to the complete dataset, which may very well be 1000’s or thousands and thousands of photographs. It’s also possible to schedule the movement to run periodically, and you may parameterize the enter information supply to scale the processing. For particulars on job scheduling and enter parameterization, discuss with Create a Schedule to Automatically Process New Data.
Select Create job to run a job for the end-to-end movement.

Present the small print of the job and choose each datasets.
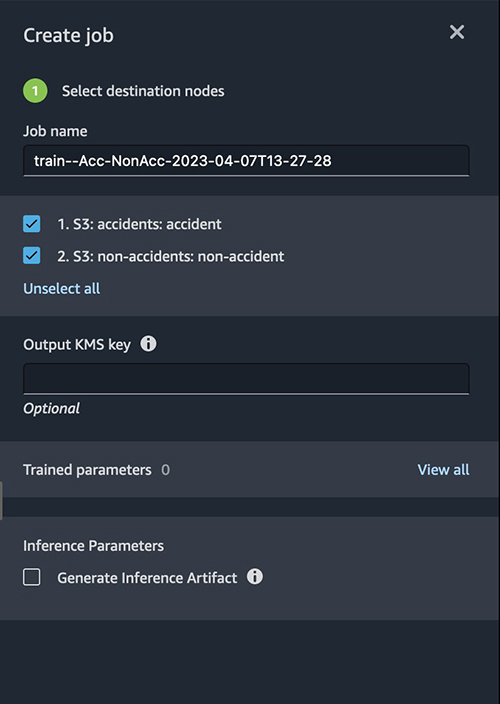
Congratulations! You have got efficiently created a job to course of photographs utilizing Knowledge Wrangler.
Mannequin coaching and deployment
JumpStart supplies one-click, end-to-end options for a lot of widespread ML use instances. We are able to use the pictures ready with Knowledge Wrangler when creating a fast picture classification mannequin in JumpStart. For directions, discuss with Run image classification with Amazon SageMaker JumpStart.
Clear up
Whenever you’re not utilizing Knowledge Wrangler, it’s essential to close down the occasion on which it runs to keep away from incurring extra charges.
Knowledge Wrangler robotically saves your information movement each 60 seconds. To keep away from shedding work, save your information movement earlier than shutting Knowledge Wrangler down.
- To save lots of your information movement in Studio, select File, then select Save Knowledge Wrangler Circulate.
- To close down the Knowledge Wrangler occasion, in Studio, select Working Situations and Kernels.
- Underneath RUNNING APPS, select the shutdown icon subsequent to the
sagemaker-data-wrangler-1.0app. - Select Shut down all to substantiate.
Knowledge Wrangler runs on an ml.m5.4xlarge occasion. This occasion disappears from RUNNING INSTANCES once you shut down the Knowledge Wrangler app.
- Shut down the JumpStart endpoint that you simply created for the outlier transformation picture embedding.
After you shut down the Knowledge Wrangler app, it has to restart the subsequent time you open a Knowledge Wrangler movement file. This will take a couple of minutes.
Conclusion
On this put up, we demonstrated utilizing picture information preparation for ML on Knowledge Wrangler. To get began with Knowledge Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler, and take a look at the newest info on the Data Wrangler product page.
Concerning the Authors
 Deepmala Agarwal works as an AWS Knowledge Specialist Options Architect. She is keen about serving to prospects construct out scalable, distributed, and data-driven options on AWS. When not at work, Deepmala likes spending time with household, strolling, listening to music, watching motion pictures, and cooking!
Deepmala Agarwal works as an AWS Knowledge Specialist Options Architect. She is keen about serving to prospects construct out scalable, distributed, and data-driven options on AWS. When not at work, Deepmala likes spending time with household, strolling, listening to music, watching motion pictures, and cooking!
 Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a ardour to design, create, and promote human-centered information and analytics experiences. Meena focusses on creating sustainable techniques that ship measurable, aggressive benefits for strategic prospects of AWS. Meena is a connector, design thinker, and strives to drive enterprise to new methods of working by way of innovation, incubation and democratization.
Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a ardour to design, create, and promote human-centered information and analytics experiences. Meena focusses on creating sustainable techniques that ship measurable, aggressive benefits for strategic prospects of AWS. Meena is a connector, design thinker, and strives to drive enterprise to new methods of working by way of innovation, incubation and democratization.
 Lu Huang is a Senior Product Supervisor on Knowledge Wrangler. She’s keen about AI, machine studying, and massive information.
Lu Huang is a Senior Product Supervisor on Knowledge Wrangler. She’s keen about AI, machine studying, and massive information.
 Nikita Ivkin is a Senior Utilized Scientist at Amazon SageMaker Knowledge Wrangler with pursuits in machine studying and information cleansing algorithms.
Nikita Ivkin is a Senior Utilized Scientist at Amazon SageMaker Knowledge Wrangler with pursuits in machine studying and information cleansing algorithms.






