Tremendous-Tuning OpenAI Language Fashions with Noisily Labeled Information
By Chris Mauck, Jonas Mueller
This text demonstrates how data-centric AI instruments can enhance a fine-tuned Massive Language Mannequin (LLM; a.ok.a. Basis Mannequin). These instruments optimize the dataset itself fairly than altering the mannequin structure/hyperparameters — working the very same fine-tuning code on the improved dataset boosts test-set efficiency by 37% on a politeness classification activity studied right here. We obtain comparable accuracy positive factors by way of the identical data-centric AI course of throughout 3 state-of-the-art LLM fashions one can fine-tune by way of the OpenAI API: Davinci, Ada, and Curie. These are variants of the bottom LLM underpinning GPT-3/ChatGPT.
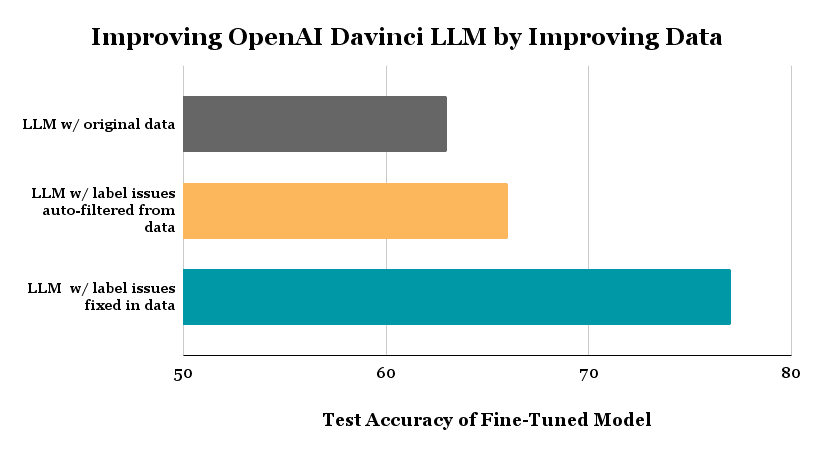
The above plot exhibits the check accuracy achieved for 3-class politeness classification of textual content by the identical LLM fine-tuning code (becoming Davinci by way of OpenAI API) run on 3 completely different datasets: (1) the unique dataset labeled by human annotators, (2) an auto-filtered model of this dataset wherein we eliminated examples robotically estimated to be mislabeled by way of Assured Studying, (3) a cleaned model of the unique information wherein we manually mounted labels of examples estimated to be mislabeled (fairly than filtering these examples).
Background
Labeled information powers AI/ML within the enterprise, however real-world datasets have been found to include between 7-50% annotation errors. Imperfectly-labeled textual content information hampers the coaching (and analysis of) ML fashions throughout duties like intent recognition, entity recognition, and sequence era. Though pretrained LLMs are geared up with a number of world information, their efficiency is adversely affected by noisy coaching information (as noted by OpenAI). Right here we illustrate data-centric strategies to mitigate the impact of label noise with out altering any code associated to mannequin structure, hyperparameters, or coaching. These information high quality enchancment strategies ought to thus stay relevant even for future superior LLMs like GPT-10.
LLMs purchase highly effective generative and discriminative capabilities after being pre-trained on most textual content throughout the web. Nonetheless, making certain the LLM produces dependable outputs for a selected enterprise use-case typically requires further coaching on precise information from this area labeled with the specified outputs. This domain-specific coaching is named fine-tuning the LLM and will be achieved by way of APIs offered by OpenAI. Imperfections within the information annotation course of inevitably introduce label errors on this domain-specific coaching information, posing a problem for correct fine-tuning and analysis of the LLM.
Listed here are quotes from OpenAI on their technique for coaching state-of-the-art AI methods:
“Since coaching information shapes the capabilities of any discovered mannequin, information filtering is a strong software for limiting undesirable mannequin capabilities.”
“We prioritized filtering out all the unhealthy information over leaving in all the good information. It’s because we will all the time fine-tune our mannequin with extra information later to show it new issues, but it surely’s a lot more durable to make the mannequin overlook one thing that it has already discovered.”
Clearly dataset high quality is a crucial consideration. Some organizations like OpenAI manually deal with points of their information to supply the perfect fashions, however that is tons of labor! Information-centric AI is an rising science of algorithms to detect information points, so you may systematically enhance your dataset extra simply with automation.
Our LLM in these experiments is the Davinci mannequin from OpenAI, which is their most succesful GPT-3 mannequin, upon which ChatGPT is predicated.
Right here we contemplate a 3-class variant of the Stanford Politeness Dataset, which has textual content phrases labeled as: rude, impartial, or well mannered. Annotated by human raters, a few of these labels are naturally low-quality.

This text walks by the next steps:
- Use the unique information to fine-tune completely different state-of-the-art LLMs by way of the OpenAI API: Davinci, Ada, and Curie.
- Set up the baseline accuracy of every fine-tuned mannequin on a check set with high-quality labels (established by way of consensus and high-agreement amongst many human annotators who rated every check instance).
- Use Assured Studying algorithms to robotically determine a whole lot of mislabeled examples.
- Take away the info with automatically-flagged label points from the dataset, after which fine-tune the very same LLMs on the auto-filtered dataset. This easy step reduces the error in Davinci mannequin predictions by 8%!
- Introduce a no-code resolution to effectively repair the label errors within the dataset, after which fine-tune the very same LLM on the mounted dataset. This reduces the error in Davinci mannequin predictions by 37%!
Related positive factors are achieved by way of these identical processes for the Ada and Curie fashions — in all circumstances, nothing was modified concerning the mannequin nor the fine-tuning code!
Right here’s a notebook you may run to breed the outcomes demonstrated on this article and perceive the code to implement every step.
You’ll be able to obtain the practice and check units right here: train test
Our coaching dataset has 1916 examples every labeled by a single human annotator, and thus some could also be unreliable. The check dataset has 480 examples every labeled by 5 annotators, and we use their consensus label as a high-quality approximation of the true politeness (measuring check accuracy towards these consensus labels). To make sure a good comparability, this check dataset stays mounted all through our experiments (all label cleansing / dataset modification is simply achieved within the coaching set). We reformat these CSV recordsdata into the jsonl file kind required by OpenAI’s fine-tuning API.
Right here’s how our code seems to fine-tune the Davinci LLM for 3-class classification and consider its check accuracy:
!openai api fine_tunes.create -t "train_prepared.jsonl" -v "test_prepared.jsonl" --compute_classification_metrics --classification_n_classes 3 -m davinci
--suffix "baseline"
>>> Created fine-tune: ft-9800F2gcVNzyMdTLKcMqAtJ5
As soon as the job completes, we question a fine_tunes.outcomes endpoint to see the check accuracy achieved when fine-tuning this LLM on the unique coaching dataset.
!openai api fine_tunes.outcomes -i ft-9800F2gcVNzyMdTLKcMqAtJ5 > baseline.csv
df = pd.read_csv('baseline.csv')
baseline_acc = df.iloc[-1]['classification/accuracy']
>>> Tremendous-tuning Accuracy: 0.6312500238418579
Our baseline Davinci LLM achieves a check accuracy of 63% when fine-tuned on the uncooked coaching information with probably noisy labels. Even a state-of-the-art LLM just like the Davinci mannequin produces lackluster outcomes for this classification activity, is it as a result of the info labels are noisy?
Confident Learning is a lately developed suite of algorithms to estimate which information are mislabeled in a classification dataset. These algorithms require out-of-sample predicted class possibilities for all of our coaching examples and apply a novel type of calibration to find out when to belief the mannequin over the given label within the information.
To acquire these predicted possibilities we:
- Use the OpenAI API to compute embeddings from the Davinci mannequin for all of our coaching examples. You’ll be able to obtain the embeddings here.
- Match a logistic regression mannequin on the embeddings and labels within the unique information. We use 10-fold cross-validation which permits us to supply out-of-sample predicted class possibilities for each instance within the coaching dataset.
# Get embeddings from OpenAI.
from openai.embeddings_utils import get_embedding
embedding_model = "text-similarity-davinci-001"
practice["embedding"] = practice.immediate.apply(lambda x: get_embedding(x, engine=embedding_model))
embeddings = practice["embedding"].values
# Get out-of-sample predicted class possibilities by way of cross-validation.
from sklearn.linear_model import LogisticRegression
mannequin = LogisticRegression()
labels = practice["completion"].values
pred_probs = cross_val_predict(estimator=mannequin, X=embeddings, y=labels, cv=10, technique="predict_proba")
The cleanlab bundle provides an open-source Python implementation of Assured Studying. With one line of code, we will run Assured Studying utilizing the mannequin predicted possibilities to estimate which examples have label points in our coaching dataset.
from cleanlab.filter import find_label_issues
# Get indices of examples estimated to have label points:
issue_idx = find_label_issues(labels, pred_probs,
return_indices_ranked_by='self_confidence') # type indices by probability of label error
Let’s check out a number of of the label points robotically recognized in our dataset. Right here’s one instance that’s clearly mislabeled:
- Phrase: I am going to check out getLogEntries when I’ve time. Would you thoughts including me as a committer?
- Label: rude
Labeling errors like this are why we is likely to be seeing poor mannequin outcomes.

Caption: A couple of of the highest errors that have been robotically recognized.
Notice: find_label_issues is ready to decide which of the given labels are doubtlessly incorrect given solely the out-of-sample pred_probs.
Now that we now have the indices of doubtless mislabeled examples (recognized by way of automated strategies), let’s take away these 471 examples from our coaching dataset. Tremendous-tuning the very same Davinci LLM on the filtered dataset achieves a check accuracy of 66% (on the identical check information the place our unique Davinci LLM achieved 63% accuracy). We lowered the error-rate of the mannequin by 8% utilizing much less however higher high quality coaching information!
# Take away information flagged with potential label error.
train_cl = practice.drop(issue_idx).reset_index(drop=True)
format_data(train_cl, "train_cl.jsonl")
# Prepare a extra strong classifier with much less misguided information.
!openai api fine_tunes.create -t "train_cl_prepared.jsonl" -v "test_prepared.jsonl" --compute_classification_metrics --classification_n_classes 3 -m davinci --suffix "dropped"
# Consider mannequin on check information.
!openai api fine_tunes.outcomes -i ft-InhTRQGu11gIDlVJUt0LYbEx > autofiltered.csv
df = pd.read_csv('autofiltered.csv')
dropped_acc = df.iloc[-1]['classification/accuracy']
>>> 0.6604166626930237
As a substitute of fixing the auto-detected label points robotically by way of filtering, the smarter (but extra advanced) manner to enhance our dataset can be to appropriate the label points by hand. This concurrently removes a loud information level and provides an correct one, however making such corrections manually is cumbersome. We did this manually utilizing Cleanlab Studio, an enterprise information correction interface.
After changing the unhealthy labels we noticed with extra appropriate ones, we fine-tune the very same Davinci LLM on the manually-corrected dataset. The ensuing mannequin achieves 77% accuracy (on the identical check dataset as earlier than), which is a 37% discount in error from our unique model of this mannequin.
# Load in and format information with the manually mounted labels.
train_studio = pd.read_csv('train_corrected.csv')
format_data(train_studio, "train_corrected.jsonl")
# Prepare a extra strong classifier with the mounted information.
!openai api fine_tunes.create -t "train_corrected_prepared.jsonl" -v "test_prepared.jsonl"
--compute_classification_metrics --classification_n_classes 3 -m davinci --suffix "corrected"
# Consider mannequin on check information.
!openai api fine_tunes.outcomes -i ft-MQbaduYd8UGD2EWBmfpoQpkQ > corrected .csv
df = pd.read_csv('corrected.csv')
corrected_acc = df.iloc[-1]['classification/accuracy']
>>> 0.7729166746139526
Notice: all through this whole course of, we by no means modified any code associated to mannequin structure/hyperparameters, coaching, or information preprocessing! All enchancment strictly comes from rising the standard of our coaching information, which leaves room for extra optimizations on the modeling facet.
We repeated this identical experiment with two different latest LLM fashions OpenAI provides for fine-tuning: Ada and Curie. The ensuing enhancements look just like these achieved for the Davinci mannequin.
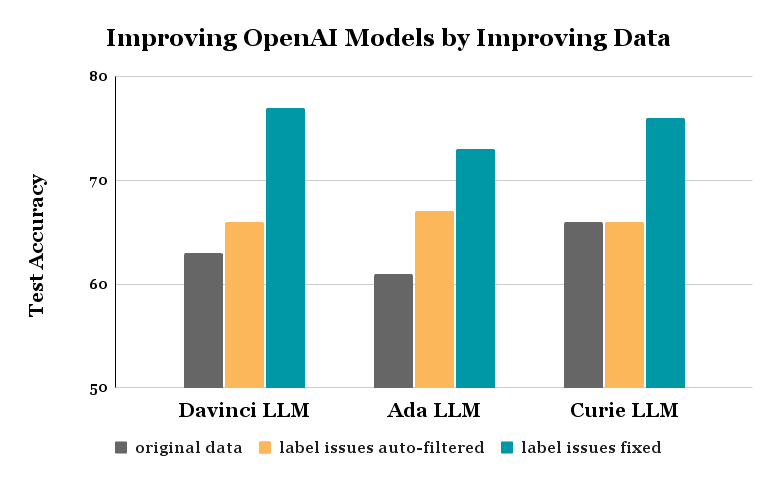
Information-centric AI is a strong paradigm for dealing with noisy information by way of AI/automated strategies fairly than tedious guide effort. There are actually instruments that will help you effectively discover and repair information and label points to enhance any ML mannequin (not simply LLMs) for many kinds of information (not simply textual content, but in addition photos, audio, tabular information, and so on). Such instruments make the most of any ML mannequin to diagnose/repair points within the information after which enhance the info for some other ML mannequin. These instruments will stay relevant with future advances in ML fashions like GPT-10, and can solely turn into higher at figuring out points when used with extra correct fashions!
Follow data-centric AI to systematically engineer higher information by way of AI/automation. This frees you to capitalize in your distinctive area information fairly than fixing normal information points like label errors.
Chris Mauck is Information Scientist at Cleanlab.





