Meet ImageReward: A Revolutionary Textual content-to-Picture Mannequin Bridging the Hole between AI Generative Capabilities and Human Values
In machine studying, generative fashions that may produce photos based mostly on textual content inputs have made important progress lately, with numerous approaches displaying promising outcomes. Whereas these fashions have attracted appreciable consideration and potential purposes, aligning them with human preferences stays a main problem as a consequence of variations between pre-training and user-prompt distributions, leading to identified points with the generated photos.
A number of challenges come up when producing photos from textual content prompts. These embody difficulties with precisely aligning textual content and pictures, precisely depicting the human physique, adhering to human aesthetic preferences, and avoiding potential toxicity and biases within the generated content material. Addressing these challenges requires extra than simply enhancing mannequin structure and pre-training knowledge. One strategy explored in pure language processing is reinforcement studying from human suggestions, the place a reward mannequin is created via expert-annotated comparisons to information the mannequin towards human preferences and values. Nevertheless, this annotation course of can take effort and time.
To cope with these challenges, a analysis staff from China has offered a novel answer to producing photos from textual content prompts. They introduce ImageReward, the primary general-purpose text-to-image human desire reward mannequin, skilled on 137k pairs of professional comparisons based mostly on real-world consumer prompts and mannequin outputs.
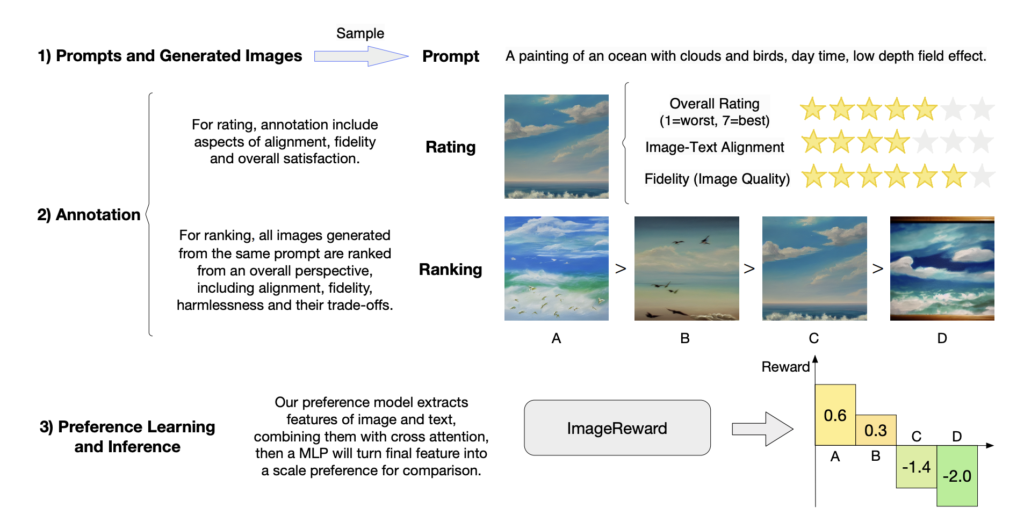
To assemble ImageReward, the authors used a graph-based algorithm to pick out numerous prompts and offered annotators with a system consisting of immediate annotation, text-image ranking, and picture rating. Additionally they recruited annotators with at the very least college-level schooling to make sure a consensus within the rankings and rankings of generated photos. The authors analyzed the efficiency of a text-to-image mannequin on several types of prompts. They collected a dataset of 8,878 helpful prompts and scored the generated photos based mostly on three dimensions. Additionally they recognized frequent issues in generated photos and located that physique issues and repeated technology had been probably the most extreme. They studied the affect of “perform” phrases in prompts on the mannequin’s efficiency and located that correct perform phrases enhance text-image alignment.
The experimental step concerned coaching ImageReward, a desire mannequin for generated photos, utilizing annotations to mannequin human preferences. BLIP was used because the spine, and a few transformer layers had been frozen to stop overfitting. Optimum hyperparameters had been decided via a grid search utilizing a validation set. The loss perform was formulated based mostly on the ranked photos for every immediate, and the aim was to routinely choose photos that people want.
Within the experiment step, the mannequin is skilled on a dataset of over 136,000 pairs of picture comparisons and is in contrast with different fashions utilizing desire accuracy, recall, and filter scores. ImageReward outperforms different fashions, with a desire accuracy of 65.14%. The paper additionally consists of an settlement evaluation between annotators, researchers, annotator ensemble, and fashions. The mannequin is proven to carry out higher than different fashions by way of picture constancy, which is extra complicated than aesthetics, and it maximizes the distinction between superior and inferior photos. As well as, an ablation research was carried out to investigate the influence of eradicating particular parts or options from the proposed ImageReward mannequin. The principle results of the ablation research is that eradicating any of the three branches, together with the transformer spine, the picture encoder, and the textual content encoder, would result in a major drop within the desire accuracy of the mannequin. Particularly, eradicating the transformer spine would trigger probably the most important efficiency drop, indicating the essential function of the transformer within the mannequin.
On this article, we offered a brand new investigation made by a Chinese language staff that launched ImageReward. This general-purpose text-to-image human desire reward mannequin addresses points in generative fashions by aligning with human values. They created a pipeline for annotation and a dataset of 137k comparisons and eight,878 prompts. Experiments confirmed ImageReward outperformed present strategies and could possibly be a really perfect analysis metric. The staff analyzed human assessments and deliberate to refine the annotation course of, lengthen the mannequin to cowl extra classes and discover reinforcement studying to push text-to-image synthesis boundaries.
Try the Paper and Github. Don’t neglect to affix our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. If in case you have any questions relating to the above article or if we missed something, be at liberty to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Mahmoud is a PhD researcher in machine studying. He additionally holds a
bachelor’s diploma in bodily science and a grasp’s diploma in
telecommunications and networking programs. His present areas of
analysis concern laptop imaginative and prescient, inventory market prediction and deep
studying. He produced a number of scientific articles about individual re-
identification and the research of the robustness and stability of deep
networks.