Unveiling the Potential of CTGAN: Harnessing Generative AI for Artificial Knowledge
Everyone knows that GANs are gaining traction within the technology of unstructured artificial information, similar to pictures and texts. Nonetheless, little or no work has been performed on producing artificial tabular information utilizing GANs. Artificial information has quite a few advantages, together with its use in machine studying purposes, information privateness, information evaluation, and information augmentation. There are just a few fashions obtainable for producing artificial tabular information, and CTGAN (Conditional Tabular Generative Adversarial Community) is certainly one of them. Like different GANs, it makes use of a generator and discriminator neural community to create artificial information with related statistical properties to actual information. CTGAN can protect the underlying construction of the actual information, together with correlations between columns. The added advantages of CTGAN embody augmentation of the coaching process with mode-specific normalization, a couple of architectural modifications, and addressing information imbalance by using a conditional generator and training-by-sampling.
On this weblog publish, I used CTGAN to generate artificial information primarily based on a dataset on Credit score Evaluation collected from Kaggle.
Execs of CTGAN
- Generates artificial tabular information which have related statistical properties as the actual information, together with correlations between completely different columns.
- Preserves the underlying construction of actual information.
- The artificial information generated by CTGAN can be utilized for a wide range of purposes, similar to information augmentation, information privateness, and information evaluation.
- Can deal with steady, discrete, and categorical information.
Cons of CTGAN
- CTGAN requires a considerable amount of actual tabular information to coach the mannequin and generate artificial information which have related statistical properties to the actual information.
- CTGAN is computationally intensive and will require a major quantity of computing assets.
- The standard of the artificial information generated by CTGAN might range relying on the standard of the actual information used to coach the mannequin.
Tuning CTGAN
Like all different machine studying fashions CTGAN performs higher when it’s tuned. And there are a number of parameters to be thought of whereas tuning CTGANs. Nonetheless, for this demonstration, I used all of the default parameters that include ‘ctgan library’:
- Epochs: Variety of occasions generator and discriminator networks are skilled on the dataset.
- Studying fee: The speed at which the mannequin adjusts the weights throughout coaching.
- Batch dimension: Variety of samples utilized in every coaching iteration.
- Generator and discriminator networks dimension.
- Alternative of the optimization algorithm.
CTGAN additionally takes account of hyperparameters, such because the dimensionality of the latent area, the variety of layers within the generator and discriminator networks, and the activation capabilities utilized in every layer. The selection of parameters and hyperparameters impacts the efficiency and high quality of the generated artificial information.
Validation of CTGAN
Validation of CTGAN is hard because it comes with limitations similar to difficulties within the analysis of the standard of the generated artificial information, significantly in relation to tabular information. Although there are metrics that can be utilized to guage the similarity between the actual and artificial information, it could actually nonetheless be difficult to find out if the artificial information precisely represents the underlying patterns and relationships in the actual information. Moreover, CTGAN is weak to overfitting and may produce artificial information that’s too just like the coaching information, which can restrict their means to generalize to new information.
Just a few frequent validations methods embody:
- Statistical Checks: To check statistical properties of generated information and actual information. For instance, checks similar to correlation evaluation, Kolmogorov-Smirnov take a look at, Anderson-Darling take a look at, and chi-squared take a look at to check the distributions of the generated and actual information.
- Visualization: By plotting histograms, scatterplots, or heatmaps to visualise the similarities and variations.
- Software Testing: Through the use of artificial information in real-world purposes see if it performs equally to the actual information.
About Credit score Evaluation Knowledge
Credit score evaluation information comprises consumer information in steady and discrete/categorical codecs. For demonstration functions, I’ve pre-processed the info by eradicating rows with null values and deleting a couple of columns that weren’t wanted for this demonstration. Resulting from limitations in computational assets, working all the info and all columns would require loads of computation energy that I don’t have. Right here is the listing of columns for steady and categorical variables (discrete values similar to Depend of Youngsters (CNT_CHINDREN) are handled as categorical variables):
Categorical Variables:
TARGET
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDREN
Steady Variables:
AMT_INCOME_TOTAL
AMT_CREDIT
AMT_ANNUITY
AMT_GOODS_PRICE
Generative fashions require a considerable amount of clear information to be skilled on for higher outcomes. Nonetheless, as a result of limitations in computation energy, I’ve chosen solely 10,000 rows (exactly 9,993) from the over 300,000 rows of actual information for this demonstration. Though this quantity could also be thought of comparatively small, it must be adequate for the aim of this demonstration.
Location of the Actual Knowledge:
https://www.kaggle.com/datasets/kapoorshivam/credit-analysis
Location of the generated artificial Knowledge:

Credit score Evaluation Knowledge | Picture by Creator
I’ve generated 10k (9997 to be precise) artificial information factors and in contrast them to the actual information. The outcomes look good, though there’s nonetheless potential for enchancment. In my evaluation, I used the default parameters, with ‘relu’ because the activation perform and 3000 epochs. Rising the variety of epochs ought to lead to a greater technology of real-like artificial information. The generator and discriminator loss additionally appears good, with decrease losses indicating nearer similarity between the artificial and actual information:
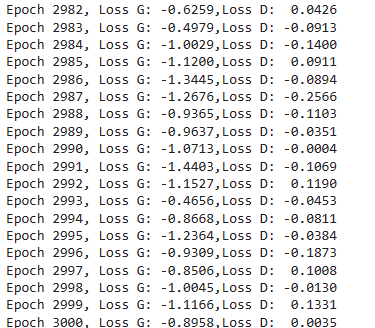
Generator and Discriminator loss | Picture by Creator
The dots alongside the diagonal line within the Absolute Log Imply and Customary Deviation diagram point out that the standard of the generated information is nice.
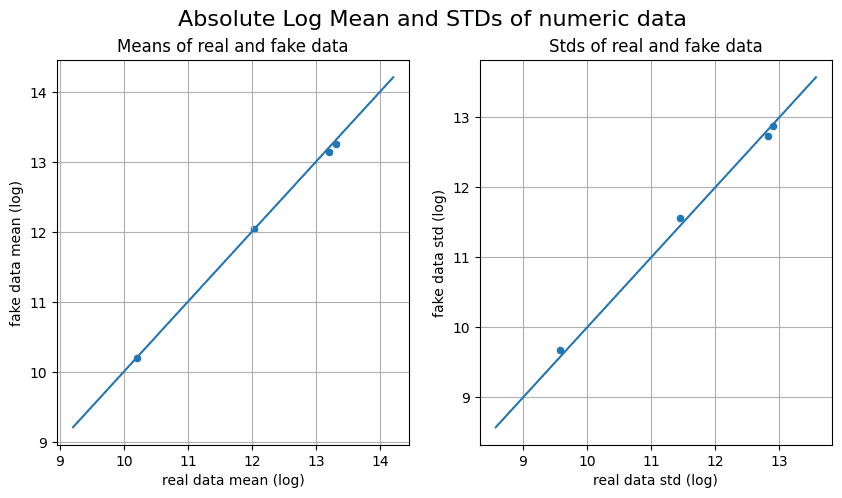
Absolute Log Imply and Customary Deviations of Numeric Knowledge | Picture by Creator
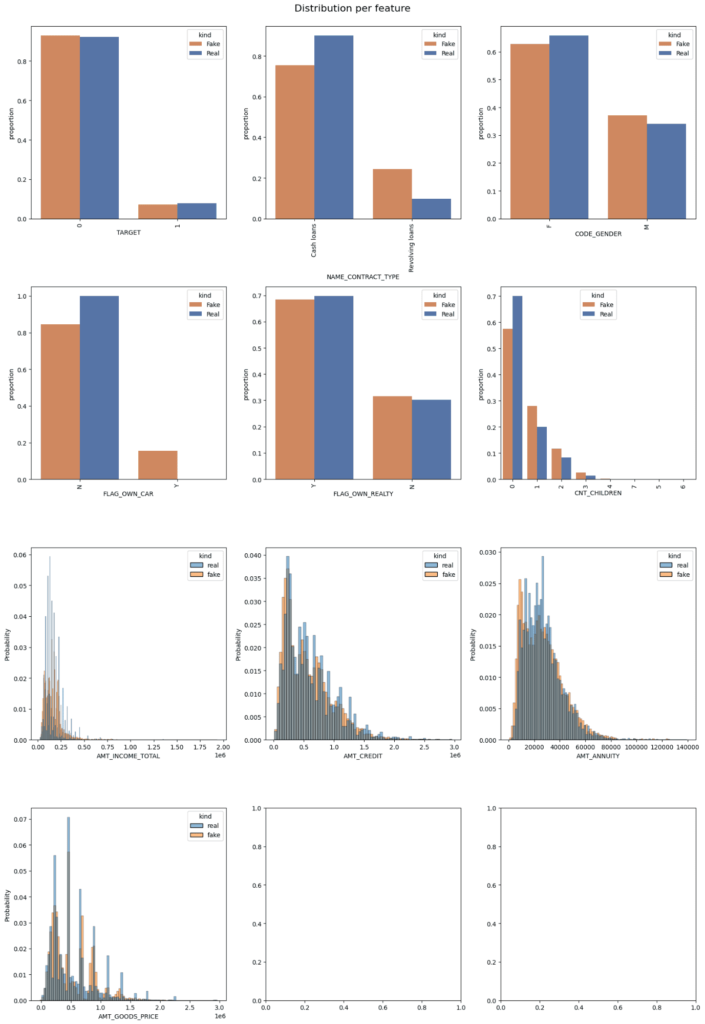
The cumulative sums within the following figures for steady columns aren’t precisely overlapping, however they’re shut, which signifies an excellent technology of artificial information and the absence of overfitting. The overlap in categorical/discrete information means that the artificial information generated is near-real. Additional statistical analyses are introduced within the following figures:
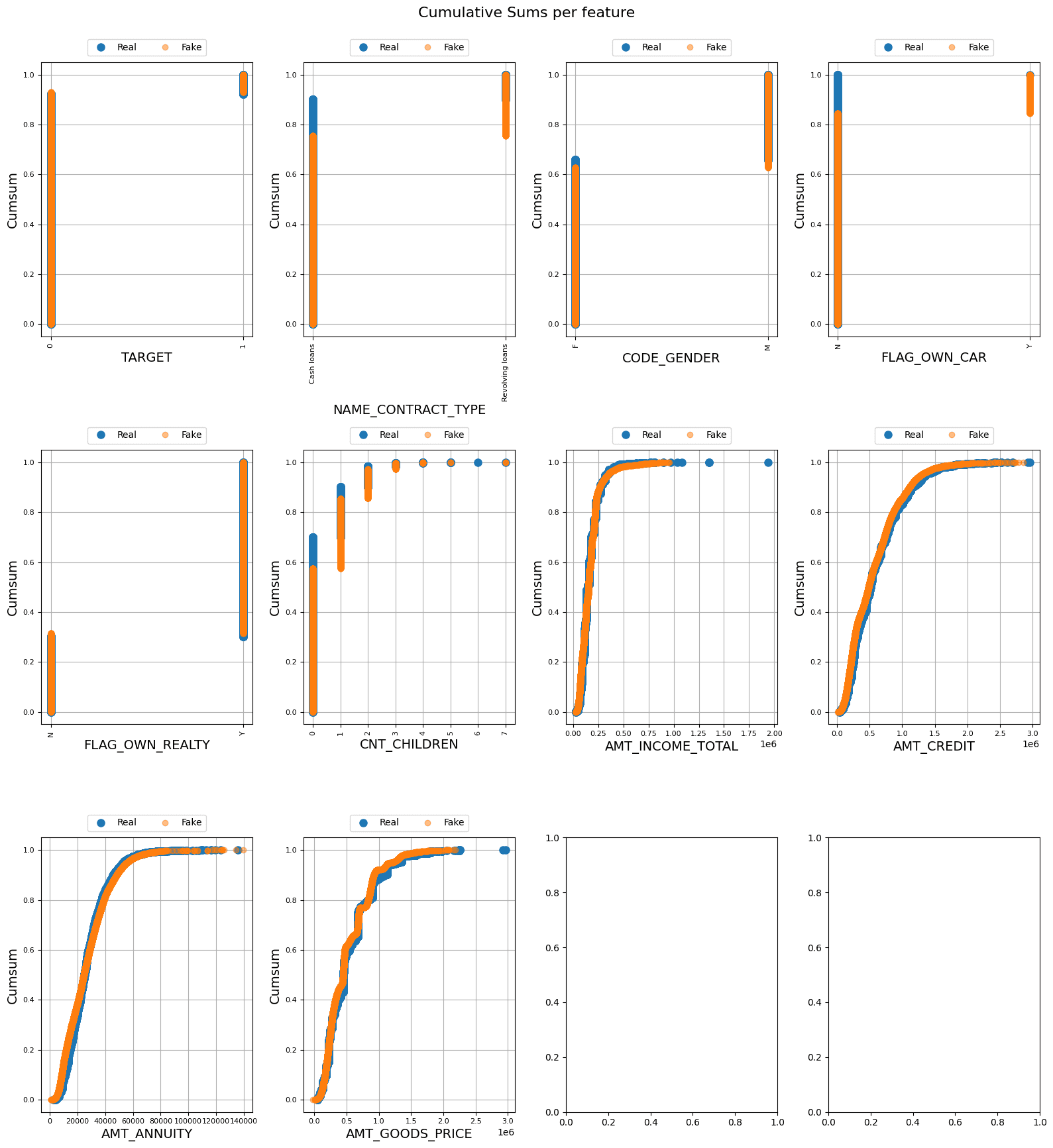
Cumulative Sums per Function | Picture by Creator
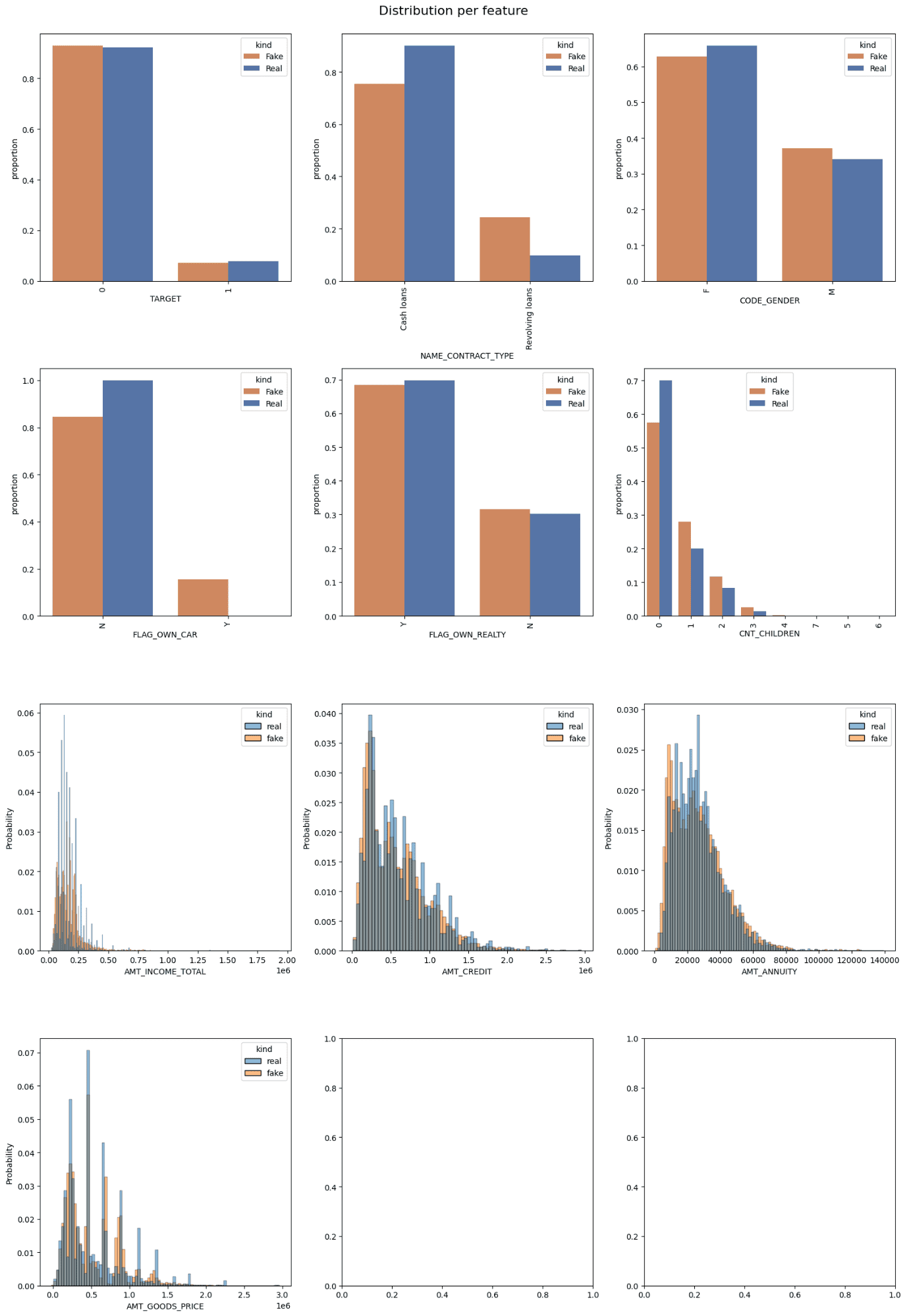
Distribution of Options| Picture by Creator
Distribution of Options | Picture by Creator
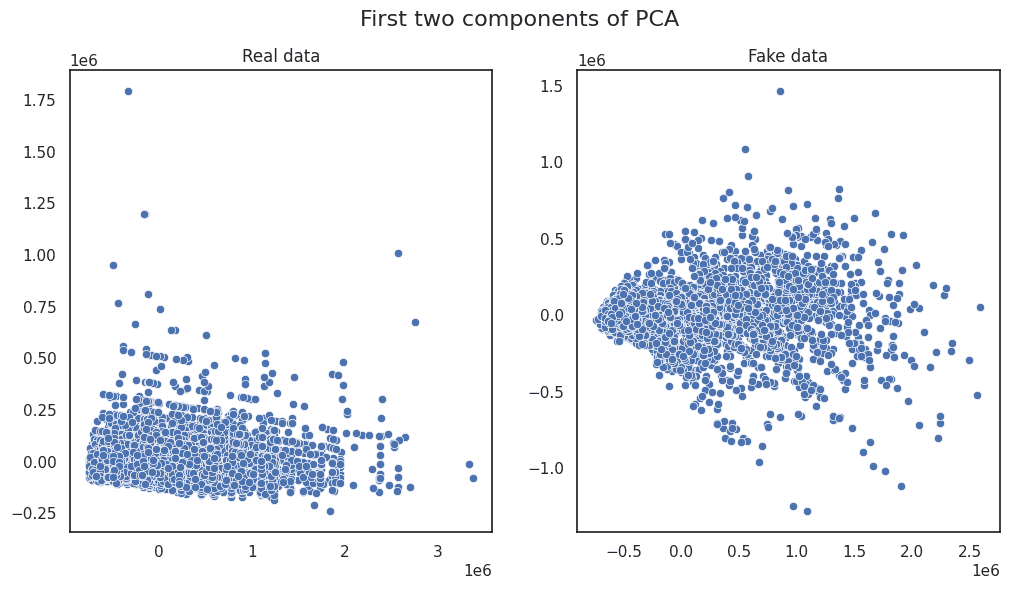
Principal Part Evaluation | Picture by Creator
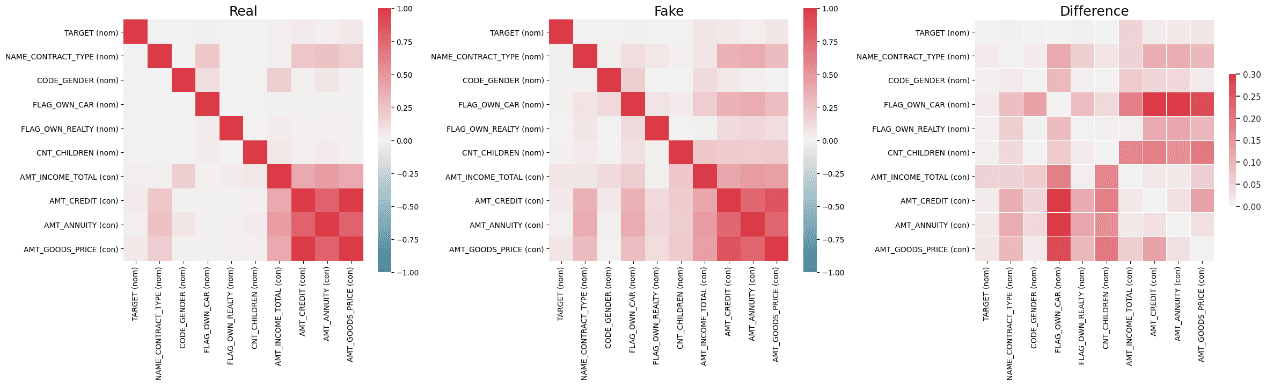
The next correlation diagram reveals noticeable correlations between the variables. It is very important be aware that even after thorough fine-tuning, there could also be variations in properties between actual and artificial information. These variations can really be useful, as they could reveal hidden properties throughout the dataset that may be leveraged to create novel options. It has been noticed that growing the variety of epochs results in enhancements within the high quality of artificial information.
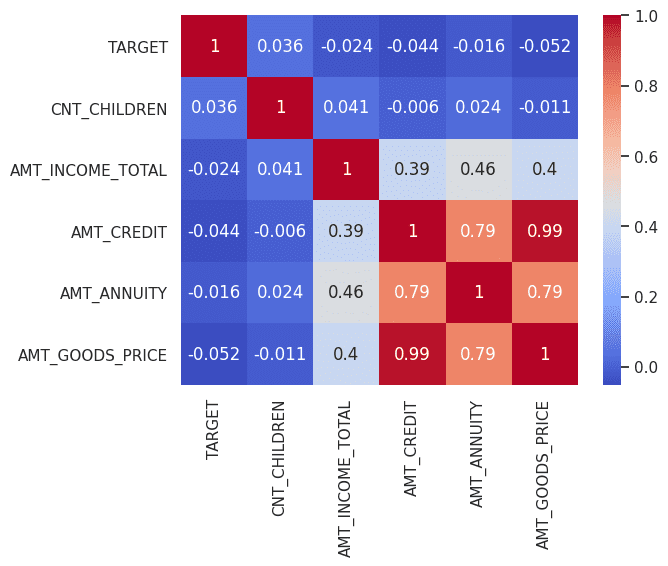
Correlation amongst variables (Actual Knowledge) | Picture by Creator
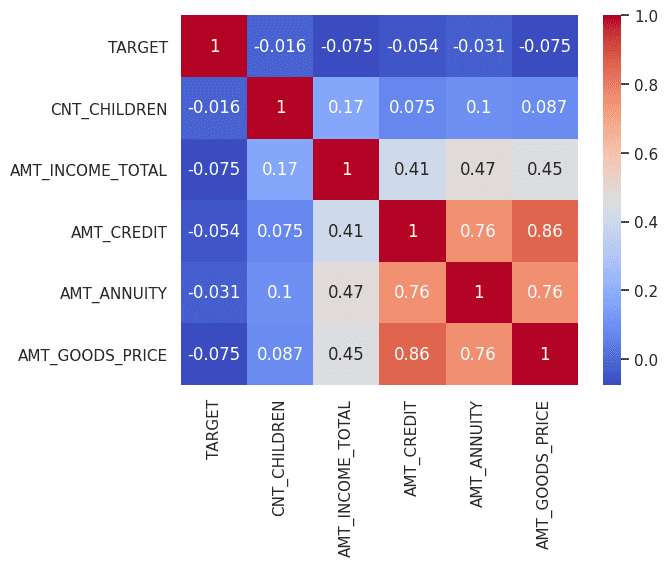
Correlation amongst variables (Artificial Knowledge) | Picture by Creator
The abstract statistics of each the pattern information and actual information additionally look like passable.
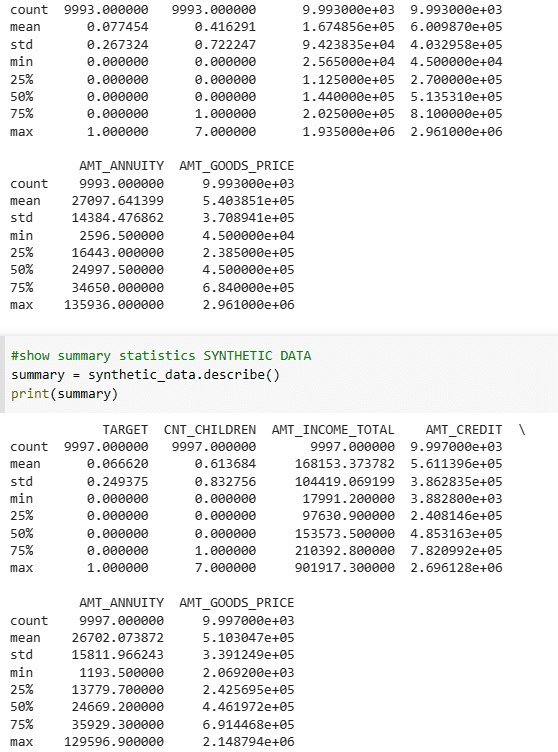
Abstract Statistics of Actual Knowledge and Artificial Knowledge | Picture by Creator
# Set up CTGAN
!pip set up ctgan
# Set up desk evaluator to research generated artificial information
!pip set up table_evaluator
# Import libraries
import torch
import pandas as pd
import seaborn as sns
import torch.nn as nn
from ctgan import CTGAN
from ctgan.synthesizers.ctgan import Generator
# Import coaching Knowledge
information = pd.read_csv("./application_data_edited_2.csv")
# Declare Categorical Columns
categorical_features = [
"TARGET",
"NAME_CONTRACT_TYPE",
"CODE_GENDER",
"FLAG_OWN_CAR",
"FLAG_OWN_REALTY",
"CNT_CHILDREN",
]
# Declare Steady Columns
continuous_cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
# Practice Mannequin
from ctgan import CTGAN
ctgan = CTGAN(verbose=True)
ctgan.match(information, categorical_features, epochs=100000)
# Generate synthetic_data
synthetic_data = ctgan.pattern(10000)
# Analyze Artificial Knowledge
from table_evaluator import TableEvaluator
print(information.form, synthetic_data.form)
table_evaluator = TableEvaluator(information, synthetic_data, cat_cols=categorical_features)
table_evaluator.visual_evaluation()
# compute the correlation matrix
corr = synthetic_data.corr()
# plot the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm")
# present abstract statistics SYNTHETIC DATA
abstract = synthetic_data.describe()
print(abstract)
The coaching means of CTGAN is predicted to converge to some extent the place the generated artificial information turns into indistinguishable from the actual information. Nonetheless, in actuality, convergence can’t be assured. A number of elements can have an effect on the convergence of CTGAN, together with the selection of hyperparameters, the complexity of the info, and the structure of the fashions. Moreover, the instability of the coaching course of can result in mode collapse, the place the generator produces solely a restricted set of comparable samples as a substitute of exploring the complete variety of the info distribution.
Ray Islam is a Knowledge Scientist (AI and ML) and Advisory Specialist Chief at Deloitte, USA. He holds a PhD in Engineering from the College of Maryland, Faculty Park, MD, USA and has labored with main firms like Lockheed Martin and Raytheon, serving shoppers similar to NASA and the US Airforce. Ray additionally has MASc in Engineering from Canada, a MSc in Worldwide Advertising and marketing, and an MBA from, UK. He’s additionally the Editor-in-Chief of the upcoming peer-reviewed Worldwide Analysis Journal of Ethics for AI (INTJEAI), and his analysis pursuits embody generative AI, augmented actuality, XAI, and ethics in AI.






