How Sportradar used the Deep Java Library to construct production-scale ML platforms for elevated efficiency and effectivity
It is a visitor put up co-written with Fred Wu from Sportradar.
Sportradar is the world’s main sports activities know-how firm, on the intersection between sports activities, media, and betting. Greater than 1,700 sports activities federations, media retailers, betting operators, and shopper platforms throughout 120 nations depend on Sportradar knowhow and know-how to spice up their enterprise.
Sportradar makes use of information and know-how to:
- Preserve betting operators forward of the curve with the services and products they should handle their sportsbook
- Give media firms the instruments to interact extra with followers
- Give groups, leagues, and federations the info they should thrive
- Preserve the trade clear by detecting and stopping fraud, doping, and match fixing
This put up demonstrates how Sportradar used Amazon’s Deep Java Library (DJL) on AWS alongside Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Simple Storage Service (Amazon S3) to construct a production-ready machine studying (ML) inference answer that preserves important tooling in Java, optimizes operational effectivity, and will increase the crew’s productiveness by offering higher efficiency and accessibility to logs and system metrics.
The DJL is a deep studying framework constructed from the bottom as much as assist customers of Java and JVM languages like Scala, Kotlin, and Clojure. Proper now, most deep studying frameworks are constructed for Python, however this neglects the massive variety of Java builders and builders who’ve present Java code bases they wish to combine the more and more highly effective capabilities of deep studying into. With the DJL, integrating this deep studying is easy.
On this put up, the Sportradar crew discusses the challenges they encountered and the options they created to construct their mannequin inference platform utilizing the DJL.
Enterprise necessities
We’re the US squad of the Sportradar AI division. Since 2018, our crew has been growing quite a lot of ML fashions to allow betting merchandise for NFL and NCAA soccer. We just lately developed 4 extra new fashions.
The fourth down determination fashions for the NFL and NCAA predict the possibilities of the result of a fourth down play. A play end result may very well be a discipline aim try, play, or punt.
The drive end result fashions for the NFL and NCAA predict the possibilities of the result of the present drive. A drive end result may very well be an finish of half, discipline aim try, landing, turnover, turnover on downs, or punt.

Our fashions are the constructing blocks of different fashions the place we generate a listing of stay betting markets, embrace unfold, whole, win likelihood, subsequent rating sort, subsequent crew to attain, and extra.
The enterprise necessities for our fashions are as follows:
- The mannequin predictor ought to be capable to load the pre-trained mannequin file one time, then make predictions on many performs
- Now we have to generate the possibilities for every play underneath 50-milisecond latency
- The mannequin predictor (characteristic extraction and mannequin inference) must be written in Java, in order that the opposite crew can import it as a Maven dependency
Challenges with the in-place system
The primary problem we now have is find out how to bridge the hole between mannequin coaching in Python and mannequin inference in Java. Our information scientists practice the mannequin in Python utilizing instruments like PyTorch and save the mannequin as PyTorch scripts. Our authentic plan was to additionally host the fashions in Python and make the most of gRPC to speak with one other service, which can use the Java gRPC shopper to ship the request.
Nonetheless, just a few points got here with this answer. Primarily, we noticed the community overhead between two completely different providers working in separate run environments or pods, which resulted in greater latency. However the upkeep overhead was the primary purpose we deserted this answer. We needed to construct each the gRPC server and the shopper program individually and hold the protocol buffer information constant and updated. Then we wanted to Dockerize the applying, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and ensure it’s dependable and auto scalable.
One other downside was at any time when an error occurred on the gRPC server aspect, the applying shopper solely received a imprecise error message as an alternative of an in depth error traceback. The shopper needed to attain out to the gRPC server maintainer to study precisely which a part of the code precipitated the error.
Ideally, we as an alternative wish to load the mannequin PyTorch scripts, extract the options from mannequin enter, and run mannequin inference solely in Java. Then we will construct and publish it as a Maven library, hosted on our inner registry, which our service crew may import into their very own Java initiatives. After we did our analysis on-line, the Deep Java Library confirmed up on the highest. After studying just a few weblog posts and DJL’s official documentation, we had been certain DJL would supply the perfect answer to our downside.
Answer overview
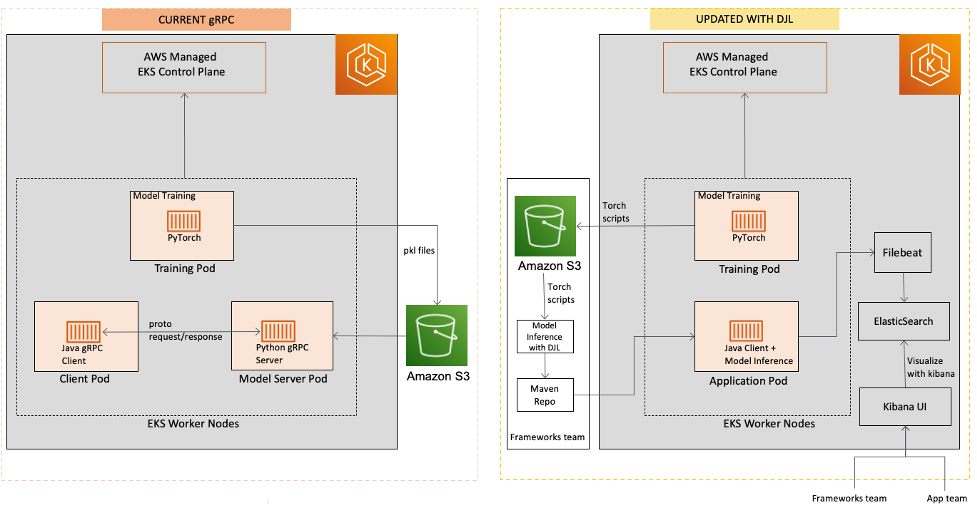
The next diagram compares the earlier and up to date structure.

The next diagram outlines the workflow of the DJL answer.

The steps are as follows:
- Coaching the fashions – Our information scientists practice the fashions utilizing PyTorch and save the fashions as torch scripts. These fashions are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket utilizing DVC, a model management device for ML fashions.
- Implementing characteristic extraction and feeding ML options – The framework crew pulls the fashions from Amazon S3 right into a Java repository the place they implement characteristic extraction and feed ML options into the predictor. They use the DJL PyTorch engine to initialize the mannequin predictor.
- Packaging and publishing the inference code and fashions – The GitLab CI/CD pipeline packages and publishes the JAR file that accommodates the inference code and fashions to an inner Apache Archiva registry.
- Importing the inference library and making calls – The Java shopper imports the inference library as a Maven dependency. All inference calls are made through Java operate calls throughout the identical Kubernetes pod. As a result of there are not any gRPC calls, the inferencing response time is improved. Moreover, the Java shopper can simply roll again the inference library to a earlier model if wanted. In distinction, the server-side error will not be clear for the shopper aspect in gRPC-based options, making error monitoring tough.
Now we have seen a secure inferencing runtime and dependable prediction outcomes. The DJL answer affords a number of benefits over gRPC-based options:
- Improved response time – With no gRPC calls, the inferencing response time is improved
- Simple rollbacks and upgrades – The Java shopper can simply roll again the inference library to a earlier model or improve to a brand new model
- Clear error monitoring – Within the DJL answer, the shopper can obtain detailed error trackback messages in case of inferencing errors
Deep Java Library overview
The DJL is a full deep studying framework that helps the deep studying lifecycle from constructing a mannequin, coaching it on a dataset, to deploying it in manufacturing. It has intuitive helpers and utilities for modalities like pc imaginative and prescient, pure language processing, audio, time sequence, and tabular information. DJL additionally options a simple mannequin zoo of a whole lot of pre-trained fashions that can be utilized out of the field and built-in into present programs.
It is usually a completely Apache-2 licensed open-source undertaking and can be found on GitHub. The DJL was created at Amazon and open-sourced in 2019. Immediately, DJL’s open-source group is led by Amazon and has grown to incorporate many nations, firms, and academic establishments. The DJL continues to develop in its capability to assist completely different {hardware}, fashions, and engines. It additionally consists of assist for brand new {hardware} like ARM (each in servers like AWS Graviton and laptops with Apple M1) and AWS Inferentia.
The structure of DJL is engine agnostic. It goals to be an interface describing what deep studying may seem like within the Java language, however leaves room for a number of completely different implementations that might present completely different capabilities or {hardware} assist. Hottest frameworks immediately equivalent to PyTorch and TensorFlow are constructed utilizing a Python entrance finish that connects to a high-performance C++ native backend. The DJL can use this to connect with these identical native backends to make the most of their work on {hardware} assist and efficiency.
For that reason, many DJL customers additionally use it for inference solely. That’s, they’ll practice a mannequin utilizing Python after which load it utilizing the DJL for deployment as a part of their present Java manufacturing system. As a result of the DJL makes use of the identical engine that powers Python, it’s in a position to run with none lower in efficiency or loss in accuracy. That is precisely the technique that we discovered to assist the brand new fashions.
The next diagram illustrates the workflow underneath the hood.

When the DJL masses, it finds all of the engine implementations obtainable within the class path utilizing Java’s ServiceLoader. On this case, it detects the DJL PyTorch engine implementation, which can act because the bridge between the DJL API and the PyTorch Native.
The engine then works to load the PyTorch Native. By default, it downloads the suitable native binary based mostly in your OS, CPU structure, and CUDA model, making it virtually easy to make use of. You too can present the binary utilizing one of many many obtainable native JAR information, that are extra dependable for manufacturing environments that always have restricted community entry for safety.
As soon as loaded, the DJL makes use of the Java Native Interface to translate all the straightforward high-level functionalities in DJL into the equal low-level native calls. Each operation within the DJL API is hand-crafted to finest match the Java conventions and make it simply accessible. This additionally consists of coping with native reminiscence, which isn’t supported by the Java Rubbish Collector.
Though all these particulars are throughout the library, calling it from a person standpoint couldn’t be simpler. Within the following part, we stroll by this course of.
How Sportradar applied DJL
As a result of we practice our fashions utilizing PyTorch, we use the DJL’s PyTorch engine for the mannequin inference.
Loading the mannequin is extremely straightforward. All it takes is to construct a standards describing the mannequin to load and the place it’s from. Then, we load it and use the mannequin to create a brand new predictor session. See the next code:

For our mannequin, we even have a customized translator, which we name MyTranslator. We use the translator to encapsulate the preprocessing code that converts from a handy Java sort into the enter anticipated by the mannequin and the postprocessing code that converts from the mannequin output right into a handy output. In our case, we selected to make use of a float[] because the enter sort and the built-in DJL classifications because the output sort. The next is a snippet of our translator code:

It’s fairly wonderful that with only a few strains of code, the DJL masses the PyTorch scripts and our customized translator, after which the predictor is able to make the predictions.
Conclusion
Sportradar’s product constructed on the DJL answer went stay earlier than the 2022–23 NFL common season began, and it has been working easily since then. Sooner or later, Sportradar plans to re-platform present fashions hosted on gRPC servers to the DJL answer.
The DJL continues to develop in many alternative methods. The latest launch, v0.21.0, has many enhancements, together with up to date engine assist, enhancements on Spark, Hugging Face batch tokenizers, an NDScope for simpler reminiscence administration, and enhancements to the time sequence API. It additionally has the primary main launch of DJL Zero, a brand new API aiming to permit assist for each utilizing pre-trained fashions and coaching your individual customized deep studying fashions even with zero data of deep studying.
The DJL additionally contains a mannequin server referred to as DJL Serving. It makes it easy to host a mannequin on an HTTP server from any of the ten supported engines, together with the Python engine to assist Python code. With v0.21.0 of DJL Serving, it consists of quicker transformer assist, Amazon SageMaker multi-model endpoint assist, updates for Secure Diffusion, enhancements for DeepSpeed, and updates to the administration console. Now you can use it to deploy large models with model parallel inference using DeepSpeed and SageMaker.
There may be additionally a lot upcoming with the DJL. The most important space underneath improvement is massive language mannequin assist for fashions like ChatGPT or Secure Diffusion. There may be additionally work to assist streaming inference requests in DJL Serving. Thirdly, there are enhancements to demos and the extension for Spark. In fact, there’s additionally commonplace persevering with work together with options, fixes, engine updates, and extra.
For extra info on the DJL and its different options, see Deep Java Library.
Observe our GitHub repo, demo repository, Slack channel, and Twitter for extra documentation and examples of the DJL!
In regards to the authors
 Fred Wu is a Senior Knowledge Engineer at Sportradar, the place he leads infrastructure, DevOps, and information engineering efforts for varied NBA and NFL merchandise. With intensive expertise within the discipline, Fred is devoted to constructing strong and environment friendly information pipelines and programs to assist cutting-edge sports activities analytics.
Fred Wu is a Senior Knowledge Engineer at Sportradar, the place he leads infrastructure, DevOps, and information engineering efforts for varied NBA and NFL merchandise. With intensive expertise within the discipline, Fred is devoted to constructing strong and environment friendly information pipelines and programs to assist cutting-edge sports activities analytics.
 Zach Kimberg is a Software program Developer within the Amazon AI org. He works to allow the event, coaching, and manufacturing inference of deep studying. There, he helped discovered and continues to develop the DeepJavaLibrary undertaking.
Zach Kimberg is a Software program Developer within the Amazon AI org. He works to allow the event, coaching, and manufacturing inference of deep studying. There, he helped discovered and continues to develop the DeepJavaLibrary undertaking.
 Kanwaljit Khurmi is a Principal Options Architect at Amazon Internet Providers. He works with the AWS prospects to supply steerage and technical help serving to them enhance the worth of their options when utilizing AWS. Kanwaljit focuses on serving to prospects with containerized and machine studying purposes.
Kanwaljit Khurmi is a Principal Options Architect at Amazon Internet Providers. He works with the AWS prospects to supply steerage and technical help serving to them enhance the worth of their options when utilizing AWS. Kanwaljit focuses on serving to prospects with containerized and machine studying purposes.