Automate Machine Studying Deployment with GitHub Actions | by Khuyen Tran | Apr, 2023
Quicker Time to Market and Enhance Effectivity
Within the earlier article, we realized about utilizing steady integration to securely and effectively merge a brand new machine-learning mannequin into the primary department.

Nevertheless, as soon as the mannequin is in the primary department, how can we deploy it into manufacturing?

Counting on an engineer to deploy the mannequin so can have some drawbacks, comparable to:
- Slowing down the discharge course of
- Consuming useful engineering time that might be used for different duties
These issues develop into extra pronounced if the mannequin undergoes frequent updates.

Wouldn’t or not it’s good if the mannequin is mechanically deployed into manufacturing each time a brand new mannequin is pushed to the primary department? That’s when steady integration is useful.
Steady deployment (CD) is the observe of mechanically deploying software program adjustments to manufacturing after they move a sequence of automated assessments. In a machine studying challenge, steady deployment can provide a number of advantages:
- Quicker time-to-market: Steady deployment reduces the time wanted to launch new machine studying fashions to manufacturing.
- Elevated effectivity: Automating the deployment course of reduces the assets required to deploy machine studying fashions to manufacturing.
This text will present you create a CD pipeline for a machine-learning challenge.
Be at liberty to play and fork the supply code of this text right here:
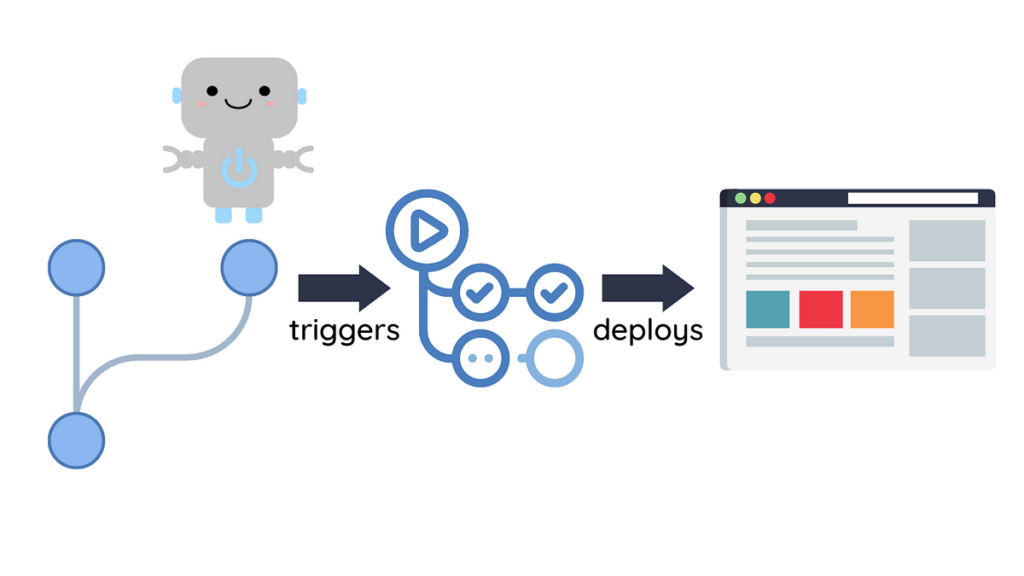
Earlier than constructing a CD pipeline, let’s establish the workflow for the pipeline:
- After a sequence of assessments, a brand new machine-learning mannequin is merged into the primary department
- A CD pipeline is triggered and a brand new mannequin is deployed into manufacturing

To construct a CD pipeline, we’ll carry out the next steps:
- Save mannequin object and mannequin metadata
- Serve the mannequin regionally
- Add the mannequin to a distant storage
- Arrange a platform to deploy your mannequin
- Create a GitHub workflow to deploy fashions into manufacturing
Let’s discover every of those steps intimately.
Save mannequin
We’ll use MLEM, an open-source software, to avoid wasting and deploy the mannequin.
To save lots of an experiment’s mannequin utilizing MLEM, start by calling its save methodology.
from mlem.api import save
...# as a substitute of joblib.dump(mannequin, "mannequin/svm")
save(mannequin, "mannequin/svm", sample_data=X_train)
Operating this script will create two recordsdata: a mannequin file and a metadata file.

The metadata file captures varied info from a mannequin object, together with:
- Mannequin artifacts such because the mannequin’s measurement and hash worth, that are helpful for versioning
- Mannequin strategies comparable to
predictandpredict_proba - Enter knowledge schema
- Python necessities used to coach the mannequin
artifacts:
knowledge:
hash: ba0c50b412f6b5d5c5bd6c0ef163b1a1
measurement: 148163
uri: svm
call_orders:
predict:
- - mannequin
- predict
object_type: mannequin
processors:
mannequin:
strategies:
predict:
args:
- identify: X
type_:
columns:
- ''
- mounted acidity
- unstable acidity
- citric acid
- residual sugar
- ...
dtypes:
- int64
- float64
- float64
- float64
- float64
- ...
index_cols:
- ''
sort: dataframe
identify: predict
returns:
dtype: int64
form:
- null
sort: ndarray
varkw: predict_params
sort: sklearn_pipeline
necessities:
- module: numpy
model: 1.24.2
- module: pandas
model: 1.5.3
- module: sklearn
package_name: scikit-learn
model: 1.2.2
Serve the mannequin regionally
Let’s check out the mannequin by serving it regionally. To launch a FastAPI mannequin server regionally, merely run:
mlem serve fastapi --model mannequin/svm
Go to http://0.0.0.0:8080 to view the mannequin. Click on “Strive it out” to check out the mannequin on a pattern dataset.

Push the mannequin to a distant storage
By pushing the mannequin to distant storage, we are able to retailer our fashions and knowledge in a centralized location that may be accessed by the GitHub workflow.

We’ll use DVC for mannequin administration as a result of it provides the next advantages:
- Model management: DVC allows retaining observe of adjustments to fashions and knowledge over time, making it simple to revert to earlier variations.
- Storage: DVC can retailer fashions and knowledge in several types of storage methods, comparable to Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage.
- Reproducibility: By versioning knowledge and fashions, experiments could be simply reproduced with the very same knowledge and mannequin variations.
To combine DVC with MLEM, we are able to use DVC pipeline. With the DVC pipeline, we are able to specify the command, dependencies, and parameters wanted to create sure outputs within the dvc.yaml file.
phases:
prepare:
cmd: python src/prepare.py
deps:
- knowledge/intermediate
- src/prepare.py
params:
- knowledge
- mannequin
- prepare
outs:
- mannequin/svm
- mannequin/svm.mlem:
cache: false
Within the instance above, we specify the outputs to be the recordsdata mannequin/svm and mannequin/svm.mlem below the outs subject. Particularly,
- The
mannequin/svmis cached, so will probably be uploaded to a DVC distant storage, however not dedicated to Git. This ensures that giant binary recordsdata don’t decelerate the efficiency of the repository. - The
mode/svm.mlemisn’t cached, so it gained’t be uploaded to a DVC distant storage however will likely be dedicated to Git. This enables us to trace adjustments within the mannequin whereas nonetheless retaining the repository’s measurement small.

To run the pipeline, sort the next command in your terminal:
$ dvc exp runOperating stage 'prepare':
> python src/prepare.py
Subsequent, specify the distant storage location the place the mannequin will likely be uploaded to within the file .dvc/config :
['remote "read"']
url = https://winequality-red.s3.amazonaws.com/
['remote "read-write"']
url = s3://your-s3-bucket/
To push the modified recordsdata to the distant storage location named “read-write”, merely run:
dvc push -r read-write
Arrange a platform to deploy your mannequin
Subsequent, let’s determine a platform to deploy our mannequin. MLEM helps deploying your mannequin to the next platforms:
- Docker
- Heroku
- Fly.io
- Kubernetes
- Sagemaker
This challenge chooses Fly.io as a deployment platform because it’s simple and low cost to get began.
To create purposes on Fly.io in a GitHub workflow, you’ll want an entry token. Right here’s how one can get one:
- Join a Fly.io account (you’ll want to offer a bank card, however they gained’t cost you till you exceed free limits).
- Log in and click on “Entry Tokens” below the “Account” button within the prime proper nook.
- Create a brand new entry token and replica it for later use.

Create a GitHub workflow
Now it involves the thrilling half: Making a GitHub workflow to deploy your mannequin! If you’re not conversant in GitHub workflow, I like to recommend studying this article for a fast overview.
We’ll create the workflow known as publish-model within the file .github/workflows/publish.yaml :

Right here’s what the file appears to be like like:
identify: publish-modelon:
push:
branches:
- foremost
paths:
- mannequin/svm.mlem
jobs:
publish-model:
runs-on: ubuntu-latest
steps:
- identify: Checkout
makes use of: actions/checkout@v2
- identify: Setting setup
makes use of: actions/setup-python@v2
with:
python-version: 3.8
- identify: Set up dependencies
run: pip set up -r necessities.txt
- identify: Obtain mannequin
env:
AWS_ACCESS_KEY_ID: ${{ secrets and techniques.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets and techniques.AWS_SECRET_ACCESS_KEY }}
run: dvc pull mannequin/svm -r read-write
- identify: Setup flyctl
makes use of: superfly/flyctl-actions/setup-flyctl@grasp
- identify: Deploy mannequin
env:
FLY_API_TOKEN: ${{ secrets and techniques.FLY_API_TOKEN }}
run: mlem deployment run flyio svm-app --model mannequin/svm
The on subject specifies that the pipeline is triggered on a push occasion to the primary department.
The publish-model job consists of the next steps:
- Trying out the code
- Establishing the Python surroundings
- Putting in dependencies
- Pulling a mannequin from a distant storage location utilizing DVC
- Establishing flyctl to make use of Fly.io
- Deploying the mannequin to Fly.io
Be aware that for the job to perform correctly, it requires the next:
- AWS credentials to tug the mannequin
- Fly.io’s entry token to deploy the mannequin
To make sure the safe storage of delicate info in our repository and allow GitHub Actions to entry them, we’ll use encrypted secrets.
To create encrypted secrets and techniques, click on “Settings” -> “Actions” -> “New repository secret.”

That’s it! Now let’s check out this challenge and see if it really works as anticipated.
Setup
To check out this challenge, begin with creating a brand new repository utilizing the challenge template.

Clone the brand new repository to your native machine:
git clone https://github.com/your-username/cicd-mlops-demo
Arrange the surroundings:
# Go to the challenge listing
cd cicd-mlops-demo# Create a brand new department
git checkout -b experiment
# Set up dependencies
pip set up -r necessities.txt
Pull knowledge from the distant storage location known as “learn”:
dvc pull -r learn
Create a brand new mannequin
svm_kernel is an inventory of values used to check the kernel hyperparameter whereas tuning the SVM mannequin. To generate a brand new mannequin, add rbf to svm__kernel within the params.yaml file.

Run a brand new experiment with the change:
dvc exp run
Push the modified mannequin to distant storage known as “read-write”:
dvc push -r read-write
Add, commit, and push adjustments to the repository within the “experiment” department:
git add .
git commit -m 'change svm kernel'
git push origin experiment
Create a pull request
Subsequent, create a pull request by clicking the Contribute button.

After making a pull request within the repository, a GitHub workflow will likely be triggered to run assessments on the code and mannequin.
After all of the assessments have handed, click on “Merge pull request.”

Deploy the mannequin
As soon as the adjustments are merged, a CD pipeline will likely be triggered to deploy the ML mannequin.
To view the workflow run, click on the workflow then click on the publish-model job.


Click on the hyperlink below the “Deploy mannequin” step to view the web site to which the mannequin is deployed.

Right here’s what the web site appears to be like like:
Congratulations! You have got simply realized create a CD pipeline to automate your machine-learning workflows. Combining CD with CI will enable your firms to catch errors early, scale back prices, and scale back time-to-market.



