Meet SparseFormer: A Neural Structure for Sparse Visible Recognition with Restricted Tokens
Creating neural networks for visible recognition has lengthy been a captivating however tough topic in pc imaginative and prescient. Newly recommended imaginative and prescient transformers replicate the human consideration course of by utilizing consideration operations on every patch or unit to work together dynamically with different models. Convolutional neural networks (CNNs) assemble options by making use of convolutional filters to every unit of images or characteristic maps. To conduct operations intensively, convolution-based and Transformer-based architectures should traverse each unit, corresponding to a pixel or patch on the grid map. The sliding home windows that give rise to this intensive per-unit traversal mirror the concept that foreground gadgets could present up constantly about their spatial placements in an image.
They don’t, nonetheless, have to have a look at each side of a state of affairs to determine it since they’re people. As a substitute, they will shortly determine textures, edges, and high-level semantics inside these areas after broadly figuring out discriminative areas of curiosity with quite a few glances. Distinction this with present visible networks, the place it’s customary to discover every visible unit totally. At larger enter resolutions, the dense paradigm incurs exorbitant computing prices but doesn’t explicitly reveal what a imaginative and prescient mannequin seems at in a picture. On this examine, the authors from Present Lab of NU Singapore, Tencent AI lab, and Nanjing College recommend a brand-new imaginative and prescient structure known as SparseFormer to analyze sparse visible recognition by exactly mimicking human imaginative and prescient.
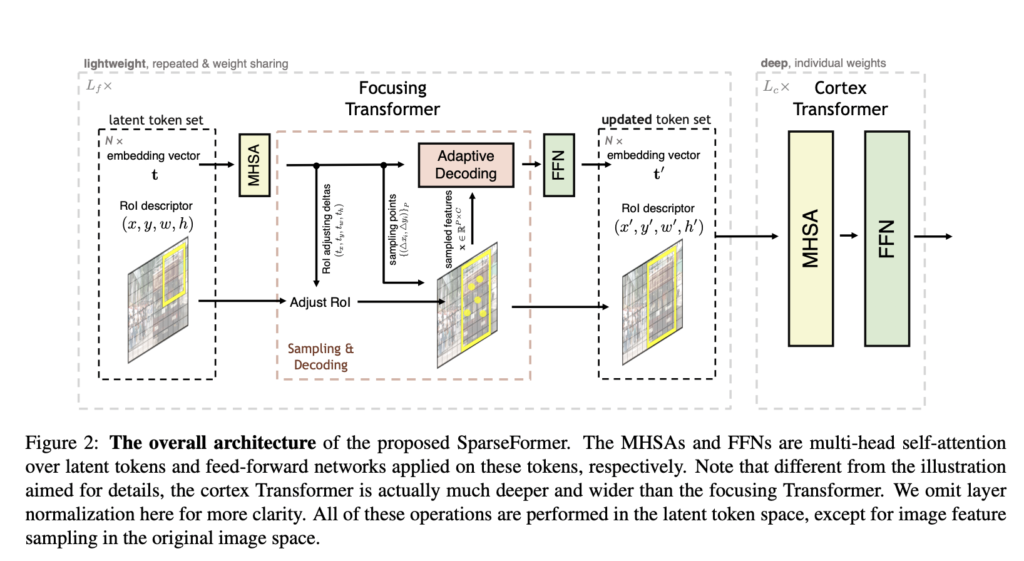
A light-weight early convolution module within the SparseFormer pulls picture options from a given image. Specifically, from the very starting, SparseFormer learns to signify an image by way of latent transformers and a really small variety of tokens (for instance, right down to 49) within the latent house. Every latent token has a area of curiosity (RoI) description that could be honed throughout a number of levels. To generate latent token embeddings iteratively, a latent focusing transformer modifies token RoIs to concentrate on foregrounds and sparsely recovers image options based on these token RoIs. SparseFormer feeds tokens with these space properties into an even bigger and deeper community or a typical transformer encoder within the latent house to attain correct recognition.
The restricted tokens within the latent house are the one ones to carry out the transformer operations. It’s applicable to check with their structure as a sparse answer for visible identification, provided that the variety of latent tokens is extraordinarily small and the characteristic sampling process is sparse (i.e., based mostly on direct bilinear interpolation). Apart from the early convolution element, which is mild in design, the general computing price of the SparseFormer is sort of unrelated to the enter decision. Furthermore, SparseFormer could also be absolutely skilled on classification indicators alone with none additional prior coaching on localizing indicators.
SparseFormer goals to analyze another paradigm for imaginative and prescient modeling as a primary step in the direction of sparse visible recognition slightly than to supply cutting-edge outcomes with bells and whistles. On the tough ImageNet classification benchmark, SparseFormer nonetheless achieves extremely encouraging outcomes corresponding to dense equivalents however at a decreased computing price. The reminiscence footprints are smaller, and throughputs are larger than dense architectures as a result of most SparseFormer operators function on tokens within the latent house slightly than the dense picture house. In spite of everything, the variety of tokens is constrained. This ends in a greater accuracy throughput trade-off, particularly within the low-compute area.
Video categorization, which is extra data-intensive and computationally costly for dense imaginative and prescient fashions however applicable for the SparseFormer structure, could also be added to the SparseFormer structure because of its easy design. As an example, with ImageNet 1K coaching, Swin-T with 4.5G FLOPs achieves 81.3 at the next throughput of 726 photographs/s. In distinction, the compact variation of SparseFormer with 2.0G FLOPs obtains 81.0 top-1 accuracy at a throughput of 1270 photographs/s. Visualizations of SparseFormer show its functionality to differentiate between foregrounds and backgrounds utilizing simply classification indicators from starting to complete. In addition they have a look at varied scaling-up SparseFormer methods for higher efficiency. Their enlargement of SparseFormer in video classification produces promising efficiency with decrease compute than dense architectures, based on experimental findings on the tough video classification Kinetics-400 benchmark. This demonstrates how the recommended sparse imaginative and prescient structure performs nicely when given denser enter knowledge.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to affix our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.



