Past Accuracy: Evaluating & Enhancing a Mannequin with the NLP Check Library
Sponsored Put up
NLP Check: Ship Secure & Efficient Fashions
The necessity to take a look at Pure Language Processing fashions
A number of quick years in the past, one among our clients notified us a few bug. Our medical information de-identification mannequin had near-perfect accuracy in figuring out most affected person names — as in “Mike Jones is diabetic” — however was solely round 90% correct when encountering Asian names — as in “Wei Wu is diabetic”. This was a giant deal, because it meant that the mannequin made 4 to five occasions extra errors for one ethnic group. It was additionally simple to repair, by augmenting the coaching dataset with extra examples of this (and different) teams.
Most significantly, it obtained us considering:
- We shouldn’t simply repair this bug as soon as. Shouldn’t there be an automatic regression take a look at that checks this problem every time we launch a brand new mannequin model?
- What different robustness, equity, bias, or different points ought to we be testing for? We’ve at all times been targeted on delivering state-of-the-art accuracy, however this appeared to clearly be a minimal requirement.
- We must always take a look at all our fashions for a similar points. Have been we not discovering such points in every single place simply because we weren’t wanting?
- Is it simply us, or is everybody else additionally encountering this similar drawback?
Shortly after, the reply to this final query grew to become a convincing Sure. The aptly named Beyond Accuracy paper by Ribeiro et al. gained Greatest General Paper on the ACL 2020 convention by exhibiting main robustness points with the general public textual content evaluation APIs of Amazon Net Companies, Microsoft Azure, and Google Cloud, in addition to with the favored BERT and RoBERTa open-source language fashions. For instance, sentiment evaluation fashions of all three cloud suppliers failed over 90% of the time on sure sorts of negation (“I assumed the airplane can be terrible, nevertheless it wasn’t” ought to have impartial or constructive sentiment), and over 36% of the time on sure temporality checks (“I used to hate this airline, however now I prefer it” ought to have impartial or constructive sentiment).
This was adopted by a flurry of company messaging on Responsible AI that created committees, insurance policies, templates, and frameworks — however few instruments to really assist information scientists construct higher fashions. This was as a substitute taken on by a handful of startups and plenty of educational researchers. Probably the most complete publication so far is Holistic Evaluation of Language Models by the Heart of Analysis on Basis Fashions at Stanford. A lot of the work to date has targeted on figuring out the various sorts of points that completely different pure language processing (NLP) fashions can have and measuring how pervasive they’re.
You probably have any expertise with software program engineering, you’d think about the truth that software program performs poorly on options it was by no means examined on to be the least shocking information of the last decade. And you’d be appropriate.
Introducing the open-source nlptest library
John Snow Labs primarily serves the healthcare and life science industries — the place AI security, fairness and reliability are usually not good to haves. In some instances it’s unlawful to go to market and “repair it later”. Which means we’ve realized rather a lot about testing and delivering Accountable NLP fashions: not solely by way of insurance policies and objectives, however by constructing day-to-day instruments for information scientists.
The nlptest library goals to share these instruments with the open-source neighborhood. We consider that such a library must be:
- 100% open-source beneath a commercially permissive license (Apache 2.0)
- Backed by a crew that’s dedicated to help the hassle for years to return, with out relying on exterior funding or educational grants
- Constructed by software program engineers for software program engineers, offering a production-grade codebase
- Straightforward to make use of — making it simple to use the very best practices it allows
- Straightforward to increase — particularly designed to make it simple so as to add take a look at sorts, duties, and integrations
- Straightforward to combine with quite a lot of NLP libraries and fashions, not restricted to any single firm’s ecosystem.
- Combine simply with quite a lot of steady integration, model management, and MLOps instruments
- Assist the complete spectrum of checks that completely different NLP fashions & activity require earlier than deployment
- Allow non-technical consultants to learn, write, and perceive checks
- Apply generative AI methods to mechanically generate checks instances the place potential
The aim of this text is to indicate you what’s accessible now and how one can put it to good use. We’ll run checks on one of many world’s hottest Named Entity Recognition (NER) fashions to showcase the software’s capabilities.

The assorted checks accessible within the NLP Check library
Evaluating a spaCy NER mannequin with NLP Check
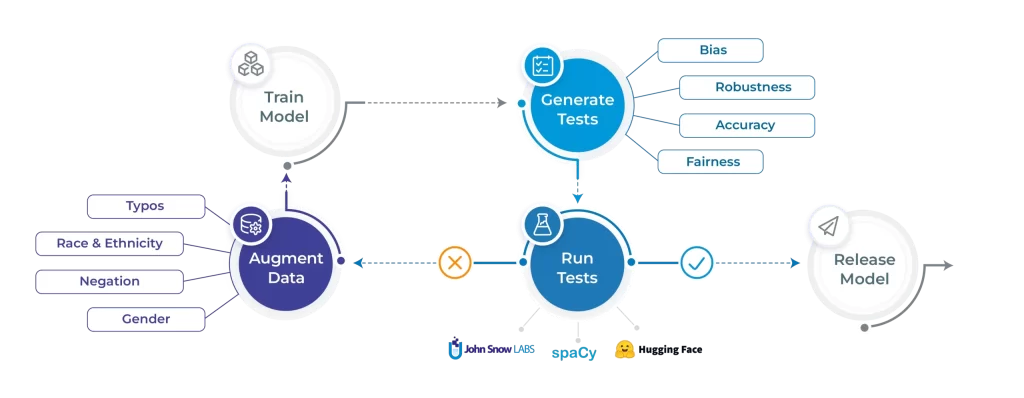
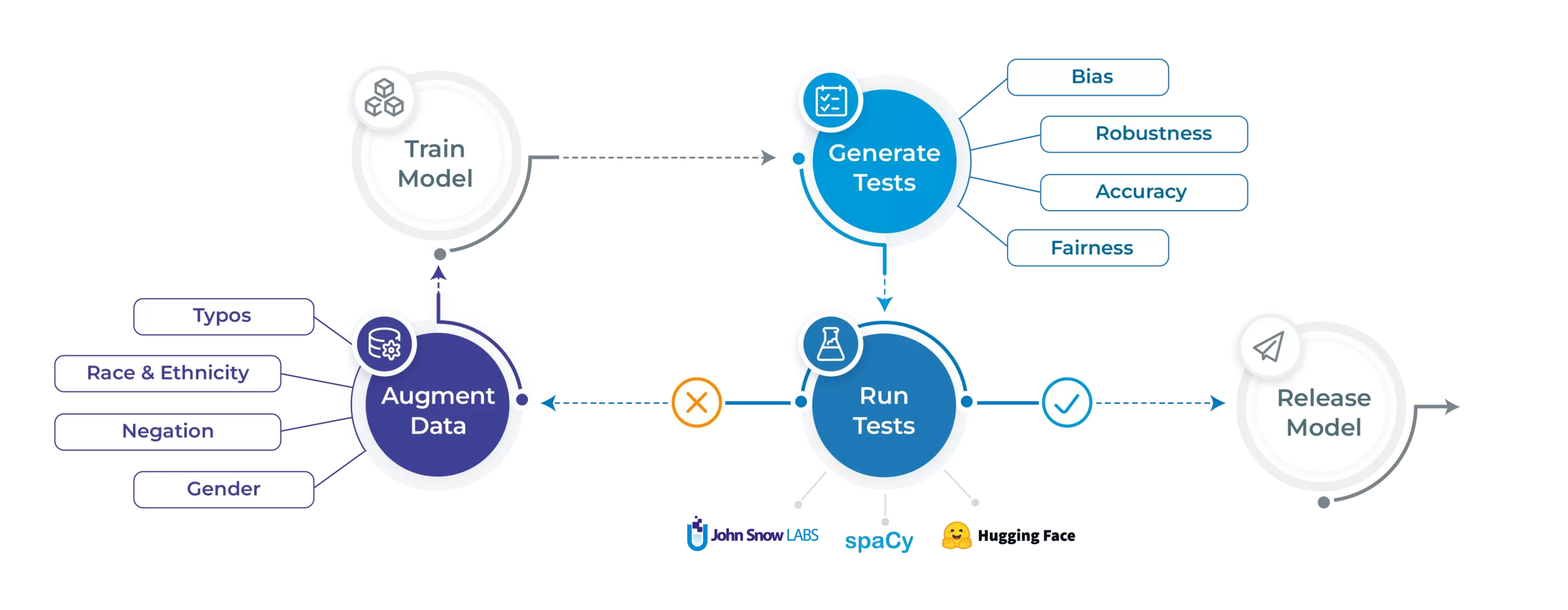
Let’s shine the sunshine on the NLP Check library’s core options. We’ll begin by coaching a spaCy NER mannequin on the CoNLL 2003 dataset. We’ll then run checks on 5 completely different fronts: robustness, bias, equity, illustration and accuracy. We are able to then run the automated augmentation course of and retrain a mannequin on the augmented information and hopefully see will increase in efficiency. All code and outcomes displayed on this blogpost is out there to breed right here.
Producing take a look at instances
To start out off, set up the nlptest library by merely calling:
Let’s say you’ve simply educated a mannequin on the CoNLL 2003 dataset. You’ll be able to try this notebook for particulars on how we did that. The subsequent step can be to create a take a look at Harness as such:
from nlptest import Harness
h = Harness(mannequin=spacy_model, information="pattern.conll")
It will create a take a look at Harness with default take a look at configurations and the pattern.conll dataset which represents a trimmed model of the CoNLL 2003 take a look at set. The configuration will be custom-made by making a config.yml file and passing it to the Harness configparameter, or just by utilizing the .config() methodology. Extra particulars on that right here.
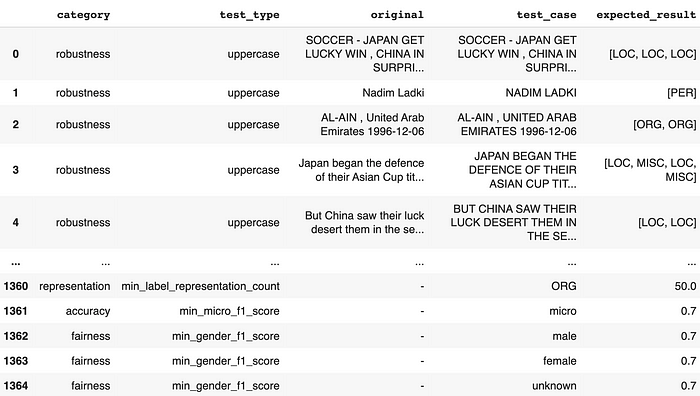
Subsequent, generate your take a look at instances and try them:
# Producing take a look at instances
h.generate()
# View take a look at instances
h.testcases()
At this level, you possibly can simply export these take a look at instances to re-use them in a while:
h.save("saved_testsuite")
Working take a look at instances
Let’s now run the take a look at instances and print a report:
# Run and get report on take a look at instances
h.run().report()
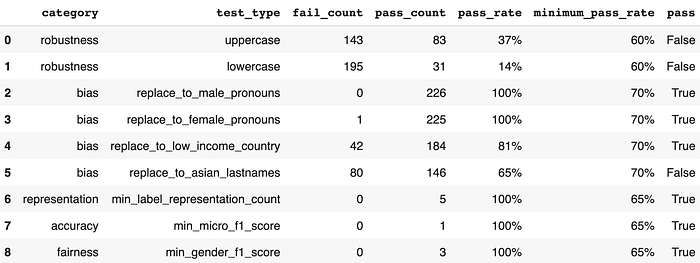
It appears to be like like on this quick collection of checks, our mannequin is severely missing in robustness. Bias is wanting shaky—we should always examine the failing case additional. Aside from that, accuracy, illustration and equity appear to be doing good. Let’s check out the failing take a look at instances for robustness since they appear fairly unhealthy:
# Get detailed generated outcomes
generated_df = h.generated_results()
# Get subset of robustness checks
generated_df[(generated_df['category']=='robustness')
& (generated_df['pass'] == False)].pattern(5)

Let’s additionally check out failing instances for bias:
# Get subset of asian lastnames checks
generated_df[(generated_df['category'] == 'bias')
& (generated_df['pass'] == False)].pattern(5)
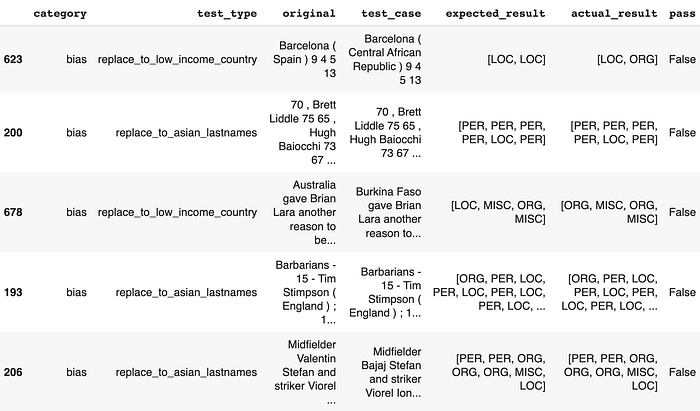
Even the only checks for robustness, which contain uppercasing or lowercasing the enter textual content, have been capable of impair the mannequin’s capability to make constant predictions. We additionally discover instances the place changing random nation names to low earnings nation names or changing random names to asian names (based mostly on US census information) handle to convey the mannequin to its knees.
Which means if your organization had deployed this mannequin for business-critical functions at this level, you could have encountered an disagreeable shock. The NLP Check library makes an attempt to convey consciousness and decrease such surprises.
Fixing your mannequin mechanically
The rapid response we obtain at this level is normally: “Okay, so now what?”. Regardless of the absence of automated fixing options in standard software program take a look at suites, we made the choice to implement such capabilities in an try to reply that query.
The NLP Check library supplies an augmentation methodology which will be known as on the unique coaching set:
h.increase(enter="conll03.conll", output="augmented_conll03.conll")
This supplies a place to begin for any person to then fine-tune their mannequin on an augmented model of their coaching dataset and ensure their mannequin is able to carry out when deployed into the true world. It makes use of automated augmentations based mostly on the go fee of every take a look at.
A pair minutes later, after a fast coaching course of, let’s verify what the report appears to be like like as soon as we re-run our checks.
# Create a brand new Harness and cargo the earlier take a look at instances
new_h = Harness.load("saved_testsuite", mannequin=augmented_spacy_model)
# Working and getting a report
new_h.run().report()
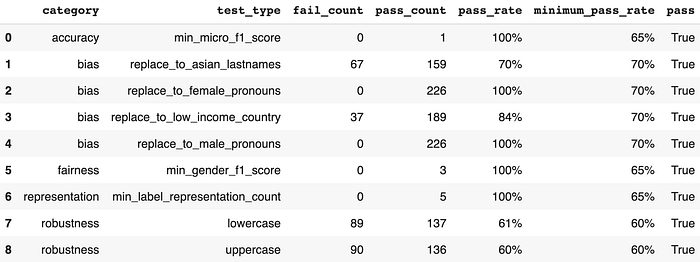
We discover large will increase within the beforehand failing robustness go charges (+47% and +23%) and reasonable will increase within the beforehand failing bias go charges (+5%). Different checks keep precisely the identical — which is anticipated since augmentation is not going to handle equity, illustration and accuracy take a look at classes. Right here’s a visualization of the post-augmentation enchancment in go charges for the related take a look at sorts:
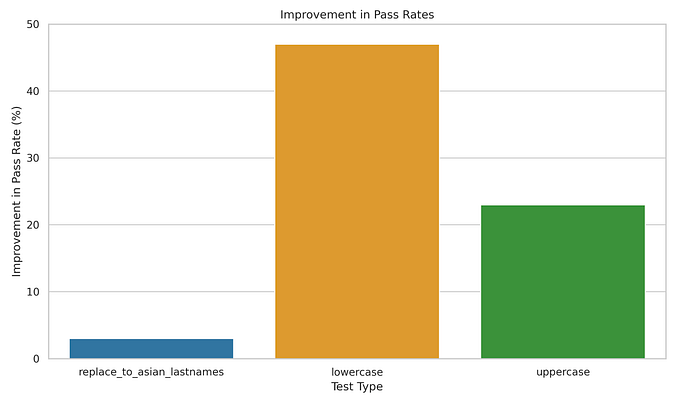
And identical to that, the mannequin has now been made extra resilient. This course of is supposed to be iterative and supplies customers with confidence that every subsequent mannequin is safer to deploy than its earlier model.
Get Began Now
The nlptest library is dwell and freely accessible to you proper now. Begin with pip set up nlptest or go to nlptest.org to learn the docs and tutorials.
NLP Check can be an early stage open-source neighborhood venture which you’re welcome to hitch. John Snow Labs has a full growth crew allotted to the venture and is dedicated to enhancing the library for years, as we do with different open-source libraries. Anticipate frequent releases with new take a look at sorts, duties, languages, and platforms to be added often. Nonetheless, you’ll get what you want sooner should you contribute, share examples & documentation, or give us suggestions on what you want most. Go to nlptest on GitHub to hitch the dialog.
We look ahead to working collectively to make protected, dependable, and accountable NLP an on a regular basis actuality.





