Construct end-to-end doc processing pipelines with Amazon Textract IDP CDK Constructs

Clever doc processing (IDP) with AWS helps automate info extraction from paperwork of various varieties and codecs, rapidly and with excessive accuracy, with out the necessity for machine studying (ML) abilities. Quicker info extraction with excessive accuracy might help you make high quality enterprise choices on time, whereas lowering general prices. For extra info, check with Intelligent document processing with AWS AI services: Part 1.
Nonetheless, complexity arises when implementing real-world eventualities. Paperwork are sometimes despatched out of order, or they might be despatched as a mixed bundle with a number of kind varieties. Orchestration pipelines must be created to introduce enterprise logic, and likewise account for various processing strategies relying on the kind of kind inputted. These challenges are solely magnified as groups cope with giant doc volumes.
On this submit, we display easy methods to clear up these challenges utilizing Amazon Textract IDP CDK Constructs, a set of pre-built IDP constructs, to speed up the event of real-world doc processing pipelines. For our use case, we course of an Acord insurance coverage doc to allow straight-through processing, however you possibly can prolong this answer to any use case, which we focus on later within the submit.
Acord doc processing at scale
Straight-through processing (STP) is a time period used within the monetary business to explain the automation of a transaction from begin to end with out the necessity for handbook intervention. The insurance coverage business makes use of STP to streamline the underwriting and claims course of. This includes the automated extraction of knowledge from insurance coverage paperwork equivalent to functions, coverage paperwork, and claims varieties. Implementing STP may be difficult because of the great amount of knowledge and the number of doc codecs concerned. Insurance coverage paperwork are inherently various. Historically, this course of includes manually reviewing every doc and coming into the information right into a system, which is time-consuming and susceptible to errors. This handbook method shouldn’t be solely inefficient however can even result in errors that may have a major impression on the underwriting and claims course of. That is the place IDP on AWS is available in.
To attain a extra environment friendly and correct workflow, insurance coverage firms can combine IDP on AWS into the underwriting and claims course of. With Amazon Textract and Amazon Comprehend, insurers can learn handwriting and totally different kind codecs, making it simpler to extract info from varied sorts of insurance coverage paperwork. By implementing IDP on AWS into the method, STP turns into simpler to attain, lowering the necessity for handbook intervention and rushing up the general course of.
This pipeline permits insurance coverage carriers to simply and effectively course of their industrial insurance coverage transactions, lowering the necessity for handbook intervention and bettering the general buyer expertise. We display easy methods to use Amazon Textract and Amazon Comprehend to mechanically extract knowledge from industrial insurance coverage paperwork, equivalent to Acord 140, Acord 125, Affidavit of Residence Possession, and Acord 126, and analyze the extracted knowledge to facilitate the underwriting course of. These providers might help insurance coverage carriers enhance the accuracy and velocity of their STP processes, in the end offering a greater expertise for his or her prospects.
Resolution overview
The answer is constructed utilizing the AWS Cloud Development Kit (AWS CDK), and consists of Amazon Comprehend for doc classification, Amazon Textract for doc extraction, Amazon DynamoDB for storage, AWS Lambda for software logic, and AWS Step Functions for workflow pipeline orchestration.
The pipeline consists of the next phases:
- Cut up the doc packages and classification of every kind sort utilizing Amazon Comprehend.
- Run the processing pipelines for every kind sort or web page of kind with the suitable Amazon Textract API (Signature Detection, Desk Extraction, Types Extraction, or Queries).
- Carry out postprocessing of the Amazon Textract output into machine-readable format.
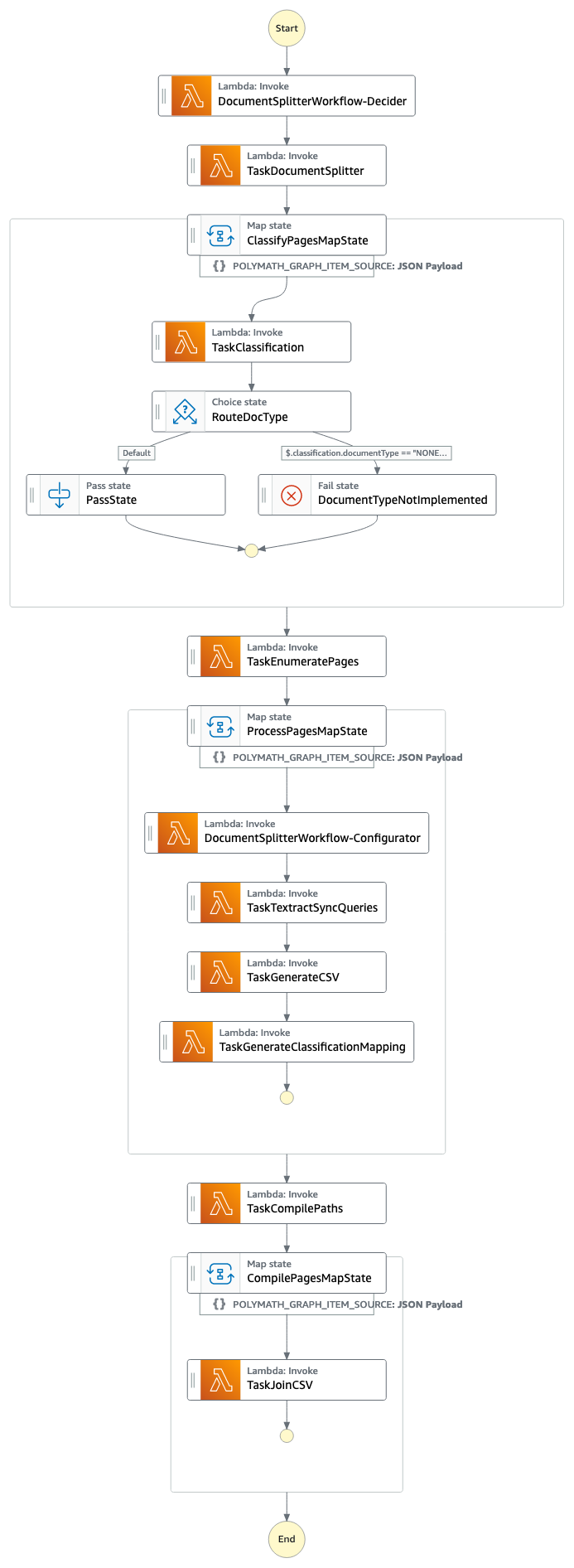
The next screenshot of the Step Features workflow illustrates the pipeline.
Conditions
To get began with the answer, guarantee you might have the next:
- AWS CDK model 2 put in
- Docker put in and operating in your machine
- Applicable entry to Step Features, DynamoDB, Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon Textract, and Amazon Comprehend
Clone the GitHub repo
Begin by cloning the GitHub repository:
Create an Amazon Comprehend classification endpoint
We first want to supply an Amazon Comprehend classification endpoint.
For this submit, the endpoint detects the next doc courses (guarantee naming is constant):
acord125acord126acord140property_affidavit
You’ll be able to create one through the use of the comprehend_acord_dataset.csv pattern dataset within the GitHub repository. To coach and create a customized classification endpoint utilizing the pattern dataset offered, observe the directions in Train custom classifiers. If you want to make use of your individual PDF recordsdata, check with the primary workflow within the submit Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend.
After coaching your classifier and creating an endpoint, you need to have an Amazon Comprehend customized classification endpoint ARN that appears like the next code:
Navigate to docsplitter/document_split_workflow.py and modify traces 27–28, which comprise comprehend_classifier_endpoint. Enter your endpoint ARN in line 28.
Set up dependencies
Now you put in the undertaking dependencies:
Initialize the account and Area for the AWS CDK. This may create the Amazon Simple Storage Service (Amazon S3) buckets and roles for the AWS CDK device to retailer artifacts and have the ability to deploy infrastructure. See the next code:
Deploy the AWS CDK stack
When the Amazon Comprehend classifier and doc configuration desk are prepared, deploy the stack utilizing the next code:
Add the doc
Confirm that the stack is totally deployed.
Then within the terminal window, run the aws s3 cp command to add the doc to the DocumentUploadLocation for the DocumentSplitterWorkflow:
We now have created a pattern 12-page doc bundle that comprises the Acord 125, Acord 126, Acord 140, and Property Affidavit varieties. The next pictures present a 1-page excerpt from every doc.
All knowledge within the varieties is artificial, and the Acord commonplace varieties are the property of the Acord Company, and are used right here for demonstration solely.
Run the Step Features workflow
Now open the Step Operate workflow. You may get the Step Operate workflow hyperlink from the document_splitter_outputs.json file, the Step Features console, or through the use of the next command:
Relying on the dimensions of the doc bundle, the workflow time will fluctuate. The pattern doc ought to take 1–2 minutes to course of. The next diagram illustrates the Step Features workflow.

When your job is full, navigate to the enter and output code. From right here you will note the machine-readable CSV recordsdata for every of the respective varieties.
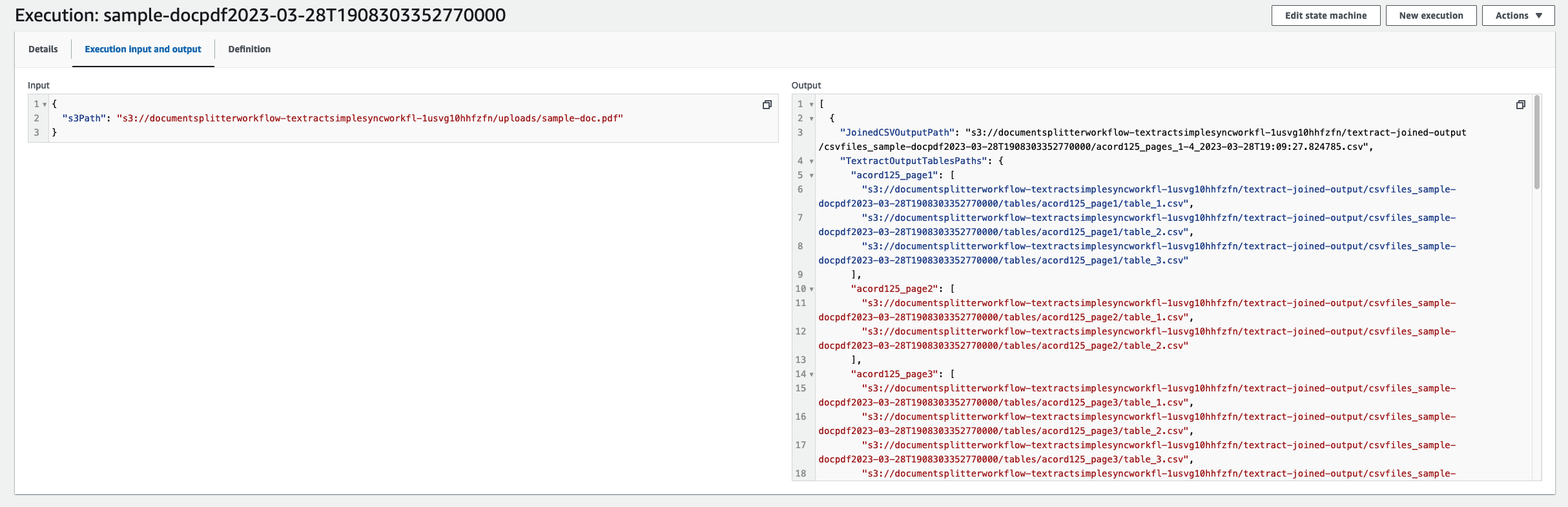
To obtain these recordsdata, open getfiles.py. Set recordsdata to be the record outputted by the state machine run. You’ll be able to run this operate by operating python3 getfiles.py. This may generate the csvfiles_<TIMESTAMP> folder, as proven within the following screenshot.

Congratulations, you might have now carried out an end-to-end processing workflow for a industrial insurance coverage software.
Prolong the answer for any sort of kind
On this submit, we demonstrated how we may use the Amazon Textract IDP CDK Constructs for a industrial insurance coverage use case. Nonetheless, you possibly can prolong these constructs for any kind sort. To do that, we first retrain our Amazon Comprehend classifier to account for the brand new kind sort, and modify the code as we did earlier.
For every of the shape varieties you skilled, we should specify its queries and textract_features within the generate_csv.py file. This customizes every kind sort’s processing pipeline through the use of the suitable Amazon Textract API.
Queries is an inventory of queries. For instance, “What’s the main e-mail handle?” on web page 2 of the pattern doc. For extra info, see Queries.
textract_features is an inventory of the Amazon Textract options you wish to extract from the doc. It may be TABLES, FORMS, QUERIES, or SIGNATURES. For extra info, see FeatureTypes.
Navigate to generate_csv.py. Every doc sort wants its classification, queries, and textract_features configured by creating CSVRow situations.
For our instance we’ve 4 doc varieties: acord125, acord126, acord140, and property_affidavit. In within the following we wish to use the FORMS and TABLES options on the acord paperwork, and the QUERIES and SIGNATURES options for the property affidavit.
Discuss with the GitHub repository for a way this was accomplished for the pattern industrial insurance coverage paperwork.
Clear up
To take away the answer, run the cdk destroy command. You’ll then be prompted to substantiate the deletion of the workflow. Deleting the workflow will delete all of the generated sources.
Conclusion
On this submit, we demonstrated how one can get began with Amazon Textract IDP CDK Constructs by implementing a straight-through processing state of affairs for a set of economic Acord varieties. We additionally demonstrated how one can prolong the answer to any kind sort with easy configuration adjustments. We encourage you to strive the answer together with your respective paperwork. Please increase a pull request to the GitHub repo for any characteristic requests you will have. To be taught extra about IDP on AWS, check with our documentation.
In regards to the Authors
 Raj Pathak is a Senior Options Architect and Technologist specializing in Monetary Companies (Insurance coverage, Banking, Capital Markets) and Machine Studying. He makes a speciality of Pure Language Processing (NLP), Massive Language Fashions (LLM) and Machine Studying infrastructure and operations tasks (MLOps).
Raj Pathak is a Senior Options Architect and Technologist specializing in Monetary Companies (Insurance coverage, Banking, Capital Markets) and Machine Studying. He makes a speciality of Pure Language Processing (NLP), Massive Language Fashions (LLM) and Machine Studying infrastructure and operations tasks (MLOps).
 Aditi Rajnish is a Second-year software program engineering scholar at College of Waterloo. Her pursuits embrace pc imaginative and prescient, pure language processing, and edge computing. She can also be obsessed with community-based STEM outreach and advocacy. In her spare time, she may be discovered mountain climbing, taking part in the piano, or studying easy methods to bake the proper scone.
Aditi Rajnish is a Second-year software program engineering scholar at College of Waterloo. Her pursuits embrace pc imaginative and prescient, pure language processing, and edge computing. She can also be obsessed with community-based STEM outreach and advocacy. In her spare time, she may be discovered mountain climbing, taking part in the piano, or studying easy methods to bake the proper scone.
 Enzo Staton is a Options Architect with a ardour for working with firms to extend their cloud information. He works intently as a trusted advisor and business specialist with prospects across the nation.
Enzo Staton is a Options Architect with a ardour for working with firms to extend their cloud information. He works intently as a trusted advisor and business specialist with prospects across the nation.





