In the direction of Habits-Pushed AI Improvement – Machine Studying Weblog | ML@CMU
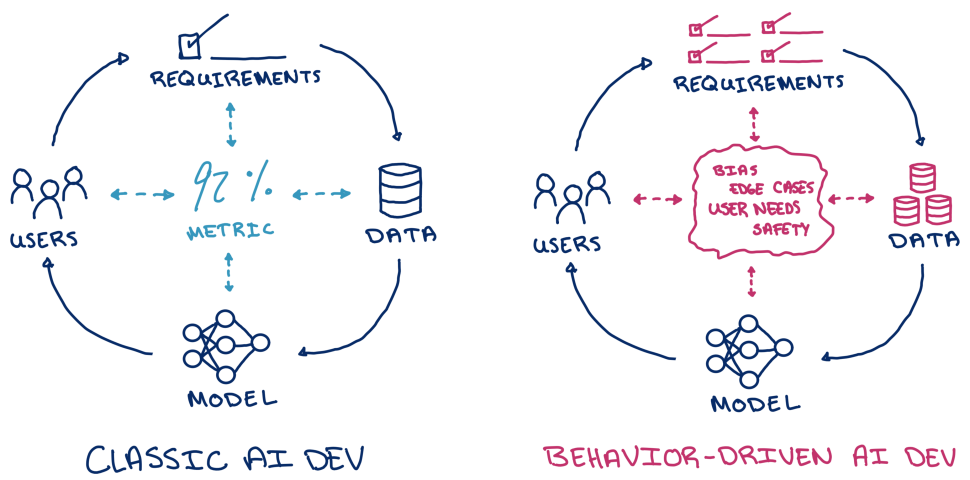
Determine 1: Habits-driven AI improvement facilities mannequin iteration on evaluating and enhancing particular real-world use instances.
It has by no means been simpler to prototype AI-driven programs. With a little bit of programming information and a few hours, you’ll be able to spin up a chatbot for your notes, a text-based image editor, or a instrument for summarizing customer feedback. However mess around along with your prototype for a bit, and also you may discover that it doesn’t work in addition to you first anticipated. Your system might make up facts or reply with racist suggestions. How would you consider your mannequin and predict its efficiency in deployment?
The canonical course of for benchmarking AI programs revolves round model-centric metrics. Calculate a metric (F1-score, precision, and many others.), and if it will increase, you’re going in the correct course. However these metrics are oversimplified aims that sand away the complexity of mannequin habits and can’t totally symbolize a mannequin’s efficiency. A metric could let you know how properly your mannequin can predict the subsequent phrase in a sentence, but it surely gained’t let you know how factually correct, logical, or truthful your mannequin is throughout various, real-world use instances. Generative AI programs akin to ChatGPT or Stable Diffusion make analysis much more difficult since there are not any well-defined metrics that may summarize their efficiency.
When creating deployed AI merchandise, practitioners as a substitute concentrate on the particular use instances their prospects have and whether or not or not their fashions are fulfilling them. In interviews with 18 AI practitioners, we discovered that they continuously accumulate consumer suggestions and develop “golden take a look at units” of behaviors that they anticipate deployed fashions to have. We time period this behavior-driven AI improvement, a improvement course of targeted on evaluating and updating fashions to enhance efficiency on real-world use instances. Whereas chatbot A may sound extra human-like, a practitioner will deploy chatbot B if it produces concise and correct solutions that prospects favor.
The panorama of AI analysis instruments primarily revolves round model-centric metrics that don’t seize vital behaviors like these chatbot traits. Whereas there are particular instruments for behavior-driven improvement, akin to fairness toolkits and robustness analysis libraries, practitioners find yourself cobbling collectively disparate instruments into ad-hoc scripts or computational notebooks which are laborious to keep up and reproduce.
I consider that there are a set of abstractions that may unify AI analysis consistent with mannequin use instances in apply. This philosophy revolves round mannequin behaviors: metrics summarizing patterns of output on subgroups of cases. This straightforward idea can encode any mannequin analysis or evaluation, from equity audits to language mannequin hallucinations. We present what this could seem like with Zeno, an interactive platform we constructed for behavior-driven improvement that helps interactive information exploration, slicing, and reporting. By investigating their very own fashions utilizing Zeno, practitioners have been in a position to pinpoint vital and actionable points akin to biases and systematic failures.
What’s mannequin habits?
The dictionary describes habits as something that an organism does involving motion and response to stimulation. Within the case of AI programs, mannequin habits is a selected sample of output for a semantically significant subgroup of enter information (stimulus). By semantically significant, I imply subgroups that may be described with human-interpretable ideas, akin to “audio with noise within the background” or “individuals who determine as ladies.” Equally, a sample of output could possibly be “excessive audio transcription error” or “low mortgage approval price.”
Behaviors may be quantified as metrics on subgroups of information, usually utilizing the identical metrics as are used for model-centric analysis. However in contrast to abstract metrics throughout a whole dataset, metrics in behavior-centric improvement quantify particular patterns of habits, like how usually a picture era mannequin produces unintelligible textual content. Assessments of mannequin behaviors are like exams for particular topics, whereas abstract metrics resemble IQ checks.
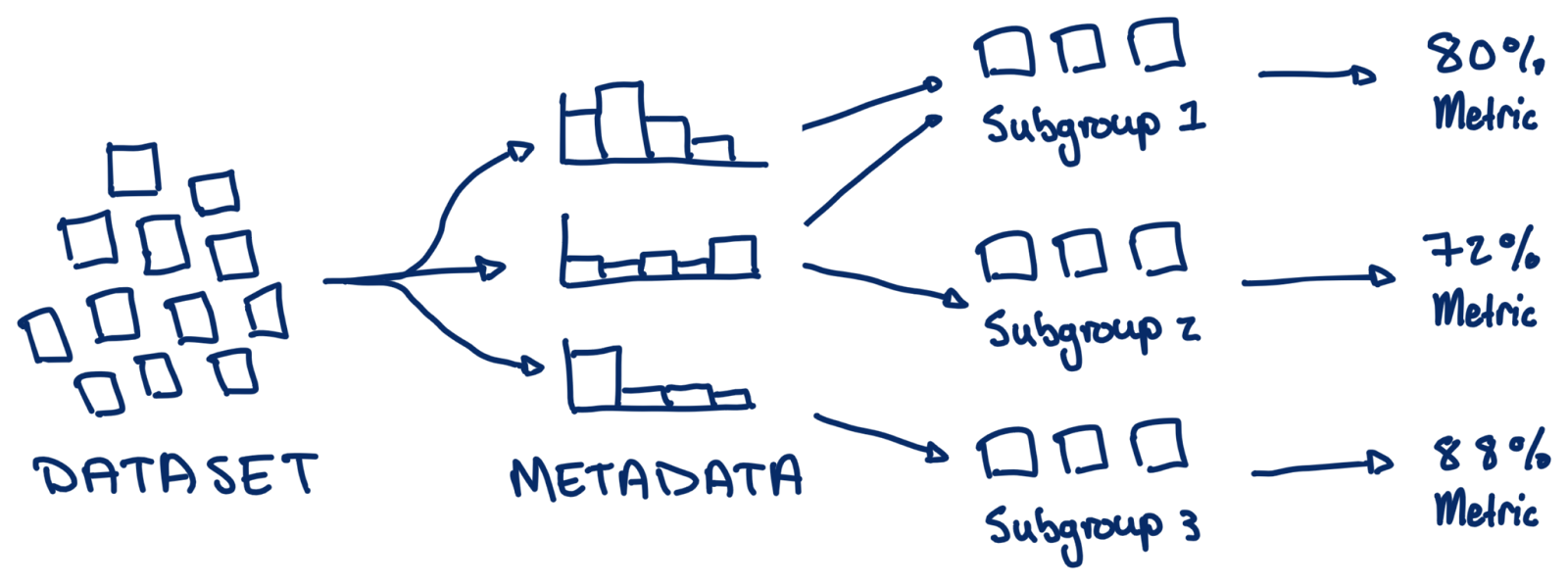
Mannequin behaviors are a comparatively easy idea, however encoding behaviors may be difficult in apply. Practitioners could not have sufficient information to validate or repair vital mannequin behaviors and have to gather or generate extra information. If they’ve in depth information, they want methods to subdivide it into significant teams of cases – how do I discover all photographs which have textual content? Lastly, for every subgroup, practitioners should derive the suitable metrics to quantify the prevalence of habits – how do I detect blurry textual content? Succinctly, behavior-driven improvement requires enough information that’s consultant of anticipated behaviors and metadata for outlining and quantifying the behaviors.
A platform for behavior-driven AI improvement
The great thing about a behavior-based framing on AI improvement is that it’s nonetheless information and mannequin agnostic. Whereas the particular behaviors for every ML activity will likely be vastly totally different, subgroups of information and metrics are common ideas.
To check this principle, we constructed a platform for behavior-driven AI improvement referred to as Zeno. Zeno is a platform that empowers customers to discover information and mannequin outputs, interactively create subgroups of information, and calculate and quantify mannequin behaviors. Zeno consists of a Python API for scaffolding the information wanted for evaluation and a consumer interface for interactively creating subgroups and evaluating behaviors.
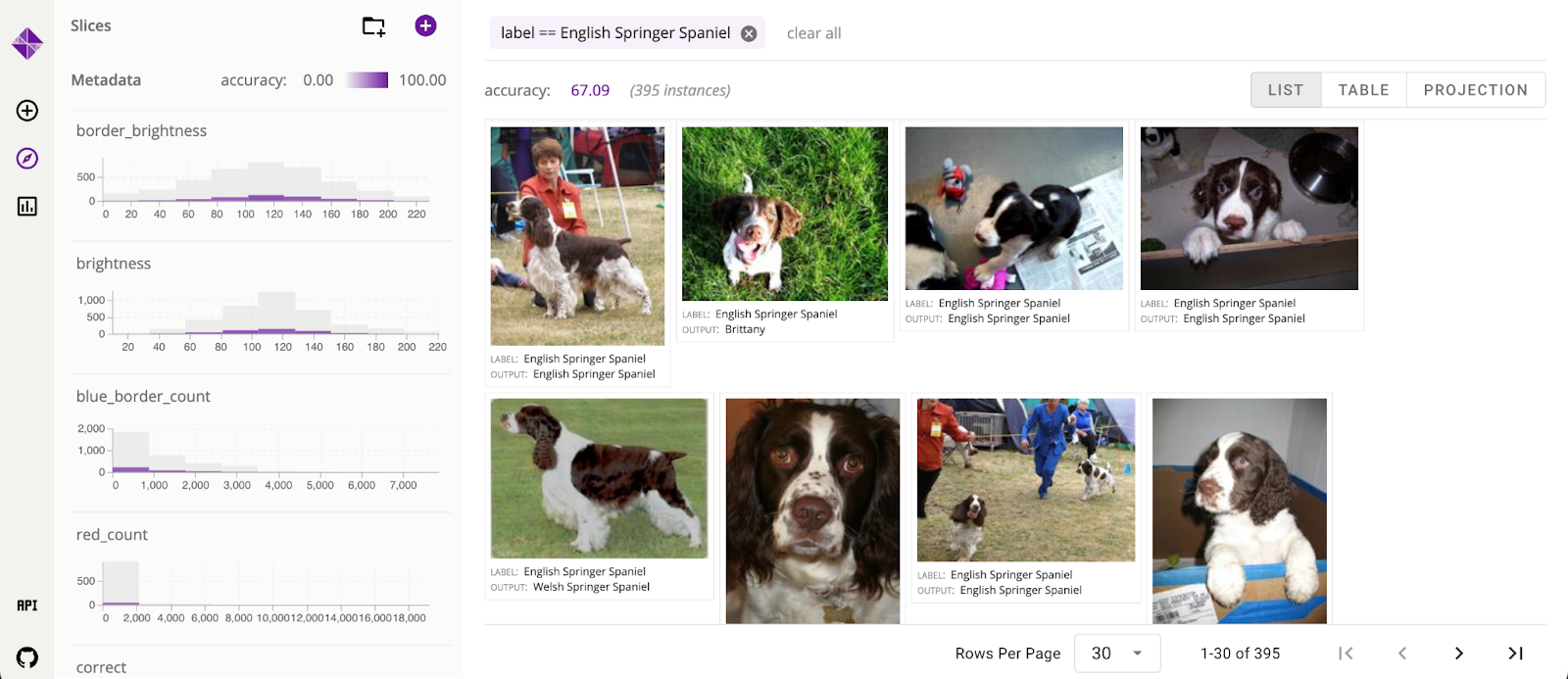
The Python API is a set of decorator capabilities (wrappers on user-defined capabilities) that can be utilized to plug in ML fashions and derive metadata options and metrics from enter information. Because the decorators are generic wrappers, Zeno helps any Python-based mannequin, processing perform, or metric. Zeno preprocesses the enter information with these capabilities, which it passes into the UI for evaluation.
Zeno’s UI is the first interface for behavior-driven analysis. It permits customers to interactively discover and filter their information, create slices, calculate metrics, and create exportable visualizations. On the correct aspect of the UI is Zeno’s occasion view, the place customers can discover the uncooked information on which the mannequin is being evaluated. Along with the usual checklist view, customers may see the information in a desk or a 2D scatterplot illustration. The left aspect of the interface holds the metadata panel. All of the metadata columns that both got here with the dataset or have been generated with the Python API have their distributions displayed within the panel. Customers can interactively filter the distributions to replace the occasion view and create named subgroups.
The UI additionally has a report web page for creating interactive abstract visualizations of behaviors. For instance, a consumer may create a bar chart evaluating the efficiency of three fashions throughout ten totally different slices. Or they may create a line chart displaying how a mannequin performs on information slices from every day of information. These visualizations may be exported or shared straight with different stakeholders.
Case Research
We’ve labored with numerous ML practitioners to use Zeno to the fashions and duties on which they work. Utilizing Zeno, practitioners discovered vital mannequin points and areas for enchancment, together with gender biases and regional mannequin disparities.
Audio transcription. This primary case examine I ran myself after I heard that OpenAI launched a brand new speech-to-text mannequin, Whisper, with state-of-the-art efficiency. I used to be curious how the mannequin in comparison with some current off-the-shelf transcription fashions. As a substitute of combination metrics, I ran the fashions on the Speech Accent Archive dataset, which has audio system worldwide saying the identical phrase. By filtering the dataset’s in depth metadata, I discovered that the fashions carry out worse for English audio system who realized the language later in life and audio system from nations the place English just isn’t the native language.
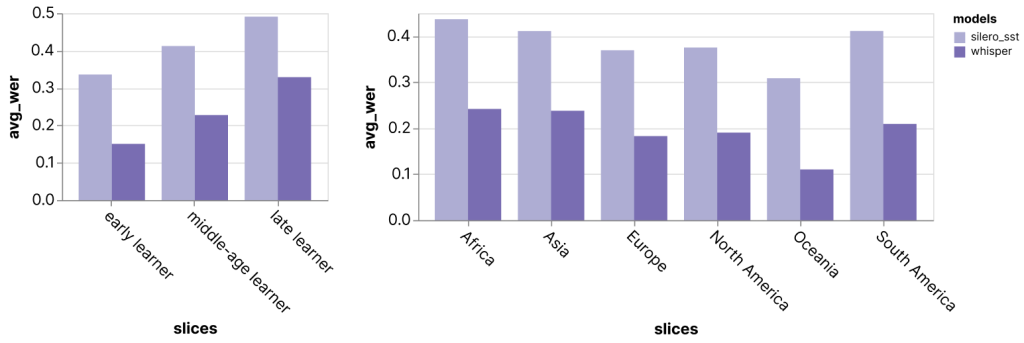
Charts exported straight from the Zeno Report UI.
Most cancers classification. In one other case examine, we labored with a researcher who wished to enhance a breast most cancers classifier for mammogram photographs. Because the information was anonymized and lacked significant metadata, the practitioner wrote dozens of capabilities utilizing a Python library to extract significant metadata options. By exploring the distributions, they discovered that photographs with increased “entropy” correlating with denser breast tissue had a considerably increased error price than photographs with decrease entropy, or much less dense, tissue. This discovering matches performance differences in human radiologists, who additionally carry out worse for photographs of denser breast tissue because it makes it tougher to detect lesions.
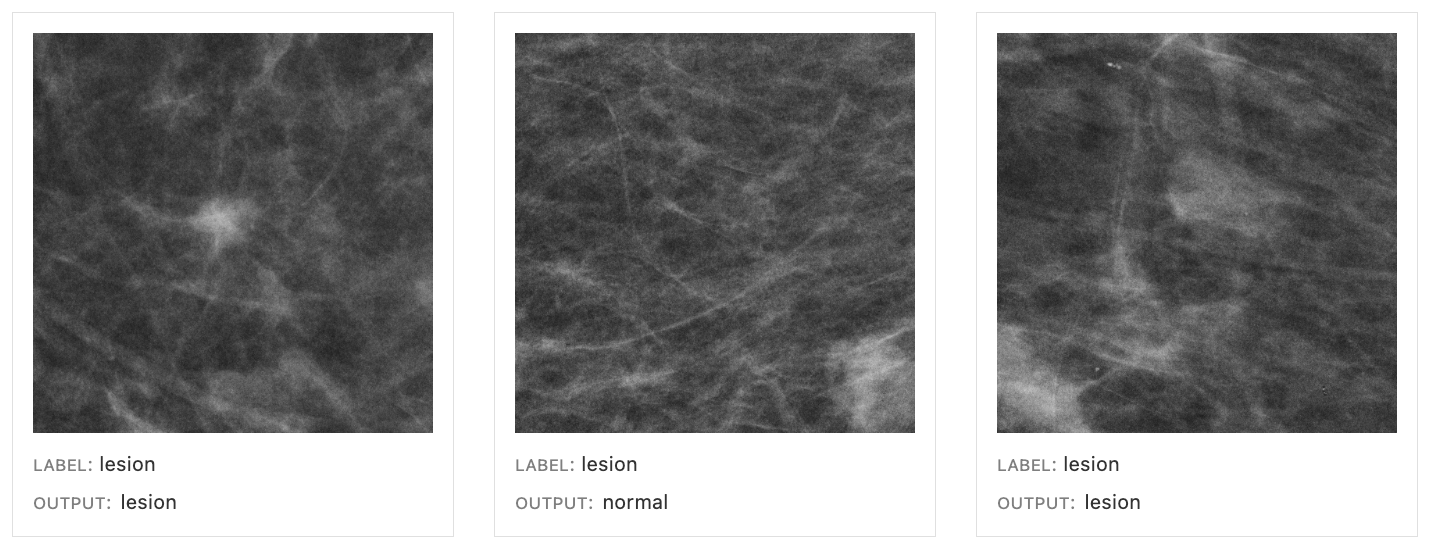

| Low density (4937) entropy < 2.75 && grey stage variance < 2.5 |
Excessive density (656) entropy > 2.75 && grey stage variance > 2.5 |
|
| AUC | 0.86 | 0.76 |
Picture era. Fashions with advanced outputs usually would not have clearly outlined metrics, together with text-to-image era fashions akin to DALL*E and Steady Diffusion. We will as a substitute have a look at metrics that measure particular behaviors. On this instance, a practitioner we labored with was exploring the DiffusionDB dataset, which has over two million prompt-image pairs from the Stable Diffusion mannequin. The dataset additionally has metadata for the way NSFW or inappropriate the prompts and pictures are. This information was used to derive an “common NSFW” metric, which might present us attention-grabbing potential biases within the mannequin. For instance, the participant in contrast the photographs generated utilizing prompts with the phrase “boy” versus “lady” and located that prompts with “lady” generated photographs with a considerably increased NSFW stage than prompts with “boy”, displaying potential biases within the kinds of photographs created by the mannequin.
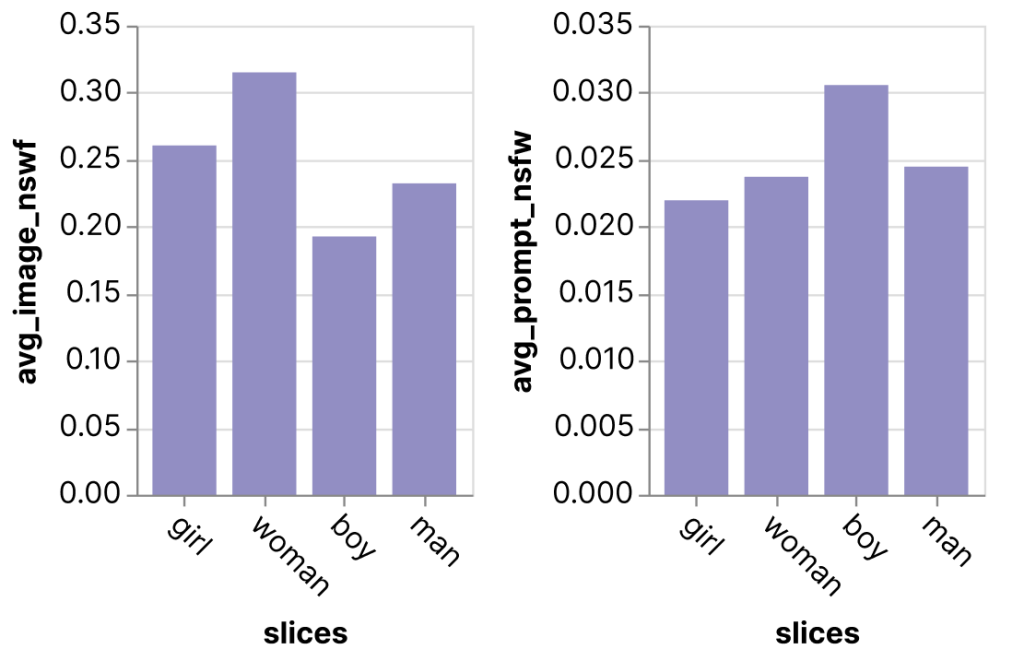
Charts exported straight from the Zeno Report UI.
Dialogue and Alternatives
Mannequin iteration remains to be a primarily reactive strategy of discovering and defining behaviors after a mannequin has been deployed and the client complaints begin rolling in. There stays vital room for enhancing this course of, from making it simpler to ideate mannequin behaviors to monitoring mannequin modifications over time.
Discovering behaviors. Whereas practitioners usually want a mannequin to find the behaviors the mannequin ought to have, strategies for outlining anticipated mannequin behaviors earlier than deployment can forestall severe real-world mannequin points. For instance, crowdsourcing techniques for eliciting potential edge instances may preemptively catch mannequin errors. Algorithmic methods that discover clusters of information with excessive error have additionally proven promise for surfacing problematic behaviors.
Knowledge discovery and era. Having high-quality, consultant information stays a persistent impediment for behavioral analysis. In some domains with ample information, akin to pure photographs, strategies like Steady Diffusion have proven promise for producing new information for analysis or coaching. In much less data-rich domains, strategies for looking via giant unlabeled datasets, akin to text-based image search, can floor precious information for analysis and retraining. Additionally it is difficult to derive metadata from cases for creating subgroups and calculating metrics. Whereas it may be straightforward to generate metadata for easy ideas like “picture brightness,” many behaviors are outlined by advanced metadata akin to “photographs with an individual carrying clear glasses” that can’t be encoded by a easy perform. Basis fashions have proven some promise in utilizing text-based descriptions to generate advanced metadata and metrics.
Mannequin comparability. Fashions are virtually by no means one-off jobs and may be up to date each day or weekly. Whereas it’s straightforward to check combination metrics, it may be difficult to check mannequin efficiency in behavior-driven improvement. To select between fashions, customers could have to check dozens of behaviors and qualitative insights. Improved visible encodings or clever suggestions of mannequin variations may assist customers make knowledgeable selections and deploy the correct fashions.
Fixing behaviors. Discovering and encoding behaviors is one factor, however fixing behaviors is one other large problem. A typical strategy to fixing points is to collect extra information and retrain the mannequin, however this course of can result in catastrophic forgetting and regressions. There are latest strategies that align properly with behavior-driven improvement, akin to slice-based learning, which might selectively repair mannequin behaviors with out new information.
Conclusion
There’s vital pleasure for this new period of AI programs. However together with their rising functionality, the complexity of their habits can also be rising. We want highly effective instruments to empower behavior-driven improvement and guarantee we construct clever programs that align with human values. Zeno gives a general-purpose platform that empowers customers to do that deep analysis throughout the varied duties of contemporary AI. Study extra about Zeno at zenoml.com, learn the full paper, or reach out if you need to make use of Zeno in your fashions!
Acknowledgments
I’d prefer to thank Will Epperson, Jason I. Hong, Yi-Cheng Huang, Misha Khodak, Adam Perer, Venkat Sivaraman, Ameet Talwalkar, and Kristen Vossler for his or her considerate suggestions and recommendation.






