Speed up Amazon SageMaker inference with C6i Intel-based Amazon EC2 situations

It is a visitor publish co-written with Antony Vance from Intel.
Prospects are at all times in search of methods to enhance the efficiency and response instances of their machine studying (ML) inference workloads with out rising the price per transaction and with out sacrificing the accuracy of the outcomes. Operating ML workloads on Amazon SageMaker working Amazon Elastic Compute Cloud (Amazon EC2) C6i situations with Intel’s INT8 inference deployment will help enhance the general efficiency by as much as 4 instances per greenback spent whereas preserving the loss in inference accuracy lower than 1% as in comparison with FP32 when utilized to sure ML workloads. With regards to working the fashions in embedded gadgets the place kind issue and measurement of the mannequin is necessary, quantization will help.
Quantization is a way to cut back the computational and reminiscence prices of working inference by representing the weights and activations with low-precision knowledge varieties like 8-bit integer (INT8) as an alternative of the same old 32-bit floating level (FP32). Within the following instance determine, we present INT8 inference efficiency in C6i for a BERT-base mannequin.

The BERT-base was fine-tuned with SQuAD v1.1, with PyTorch (v1.11) being the ML framework used with Intel® Extension for PyTorch. A batch measurement of 1 was used for the comparability. Greater batch sizes will present totally different value per 1 million inferences.
On this publish, we present you tips on how to construct and deploy INT8 inference along with your own processing container for PyTorch. We use Intel extensions for PyTorch for an efficient INT8 deployment workflow.
Overview of the expertise
EC2 C6i instances are powered by third-generation Intel Xeon Scalable processors (additionally known as Ice Lake) with an all-core turbo frequency of three.5 GHz.
Within the context of deep studying, the predominant numerical format used for analysis and deployment has up to now been 32-bit floating level, or FP32. Nonetheless, the necessity for decreased bandwidth and compute necessities of deep studying fashions has pushed analysis into utilizing lower-precision numerical codecs. It has been demonstrated that weights and activations will be represented utilizing 8-bit integers (or INT8) with out incurring important loss in accuracy.
EC2 C6i situations supply many new capabilities that lead to efficiency enhancements for AI and ML workloads. C6i situations present efficiency benefits in FP32 and INT8 mannequin deployments. FP32 inference is enabled with AVX-512 enhancements, and INT8 inference is enabled by AVX-512 VNNI directions.
C6i is now out there on SageMaker endpoints, and builders ought to anticipate it to offer over two instances price-performance enhancements for INT8 inference over FP32 inference and as much as 4 instances efficiency enchancment compared with C5 occasion FP32 inference. Confer with the appendix as an illustration particulars and benchmark knowledge.
Deep studying deployment on the sting for real-time inference is vital to many software areas. It considerably reduces the price of speaking with the cloud when it comes to community bandwidth, community latency, and energy consumption. Nonetheless, edge gadgets have restricted reminiscence, computing sources, and energy. Which means a deep studying community have to be optimized for embedded deployment. INT8 quantization has grow to be a preferred strategy for such optimizations for ML frameworks like TensorFlow and PyTorch. SageMaker gives you with a convey your individual container (BYOC) strategy and built-in instruments in an effort to run quantization.
For extra data, consult with Lower Numerical Precision Deep Learning Inference and Training.
Answer overview
The steps to implement the answer are as follows:
- Provision an EC2 C6i occasion to quantize and create the ML mannequin.
- Use the provided Python scripts for quantization.
- Create a Docker picture to deploy the mannequin in SageMaker utilizing the BYOC strategy.
- Use an Amazon Simple Storage Service (Amazon S3) bucket to repeat the mannequin and code for SageMaker entry.
- Use Amazon Elastic Container Registry (Amazon ECR) to host the Docker picture.
- Use the AWS Command Line Interface (AWS CLI) to create an inference endpoint in SageMaker.
- Run the supplied Python take a look at scripts to invoke the SageMaker endpoint for each INT8 and FP32 variations.
This inference deployment setup makes use of a BERT-base mannequin from the Hugging Face transformers repository (csarron/bert-base-uncased-squad-v1).
Stipulations
The next are stipulations for creating the deployment setup:
- A Linux shell terminal with the AWS CLI put in
- An AWS account with entry to EC2 occasion creation (C6i occasion sort)
- SageMaker entry to deploy a SageMaker mannequin, endpoint configuration, endpoint
- AWS Identity and Access Management (IAM) entry to configure an IAM function and coverage
- Entry to Amazon ECR
- SageMaker entry to create a pocket book with directions to launch an endpoint
Generate and deploy a quantized INT8 mannequin on SageMaker
Open an EC2 occasion for creating your quantized mannequin and push the mannequin artifacts to Amazon S3. For endpoint deployment, create a customized container with PyTorch and Intel® Extension for PyTorch to deploy the optimized INT8 mannequin. The container will get pushed into Amazon ECR and a C6i primarily based endpoint is created to serve FP32 and INT8 fashions.
The next diagram illustrates the high-level stream.
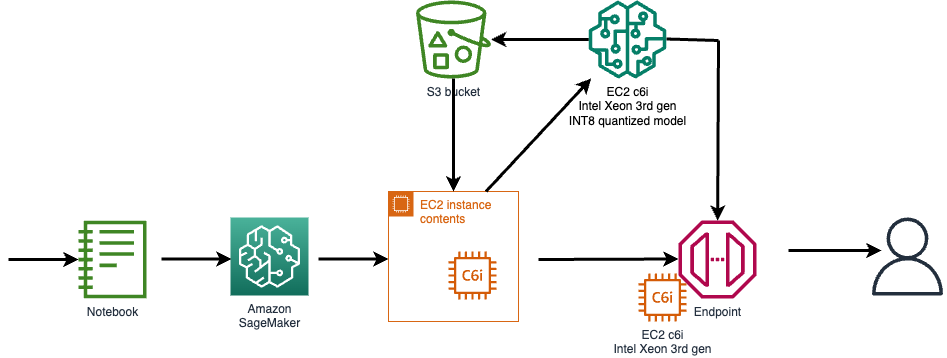
To entry the code and documentation, consult with the GitHub repo.
Instance use case
The Stanford Query Answering Dataset (SQuAD) is a studying comprehension dataset consisting of questions posed by crowd-workers on a set of Wikipedia articles, the place the reply to each query is a phase of textual content, or span, from the corresponding studying passage, or the query is likely to be unanswerable.
The next instance is a query answering algorithm utilizing a BERT-base mannequin. Given a doc as an enter, the mannequin will reply easy questions primarily based on the educational and contexts from the enter doc.
The next is an instance enter doc:
The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or normally Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), additionally identified in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers many of the Amazon basin of South America. This basin encompasses 7,000,000 sq. kilometers (2,700,000 sq mi), of which 5,500,000 sq. kilometers (2,100,000 sq mi) are coated by the rainforest.
For the query “Which title can be used to explain the Amazon rainforest in English?” we get the reply:
For the query “What number of sq. kilometers of rainforest is roofed within the basin?” we get the reply:
Quantizing the mannequin in PyTorch
This part provides a fast overview of mannequin quantization steps with PyTorch and Intel extensions.
The code snippets are derived from a SageMaker instance.
Let’s go over the modifications intimately for the operate IPEX_quantize within the file quantize.py.
- Import intel extensions for PyTorch to assist with quantization and optimization and import torch for array manipulations:
- Apply mannequin calibration for 100 iterations. On this case, you’re calibrating the mannequin with the SQuAD dataset:
- Put together pattern inputs:
- Convert the mannequin to an INT8 mannequin utilizing the next configuration:
- Run two iterations of ahead move to allow fusions:
- As a final step, save the TorchScript mannequin:
Clear up
Confer with the Github repo for steps to wash up the AWS sources created.
Conclusion
New EC2 C6i situations in an SageMaker endpoint can speed up the inference deployment as much as 2.5 instances larger with INT8 quantization. Quantizing the mannequin in PyTorch is feasible with just a few APIs from Intel PyTorch extensions. It’s beneficial to quantize the mannequin in C6i situations in order that mannequin accuracy is maintained in endpoint deployment. The SageMaker examples GitHub repo now gives an end-to-end deployment instance pipeline for quantizing and internet hosting INT8 fashions.
We encourage you to create a brand new mannequin or migrate an current mannequin utilizing INT8 quantization utilizing the EC2 C6i occasion sort and see the efficiency good points for your self.
Discover and disclaimers
No license (specific or implied, by estoppel or in any other case) to any mental property rights is granted by this doc, with the only exception that code included on this doc is licensed topic to the Zero-Clause BSD open source license (0BSD)
Appendix
New AWS situations in SageMaker with INT8 deployment help
The next desk lists SageMaker situations with and with out DL Boost help.
| Occasion Title | Xeon Gen Codename | INT8 Enabled? | DL Enhance Enabled? |
| ml.c5. xlarge – ml.c5.9xlarge | Skylake/1st | Sure | No |
| ml.c5.18xlarge | Skylake/1st | Sure | No |
| ml.c6i.1x – 32xlarge | Ice Lake/3rd | Sure | Sure |
To summarize, INT8 enabled helps the INT8 knowledge sort and computation; DL Enhance enabled helps Deep Studying Enhance.
Benchmark knowledge
The next desk compares the price and relative efficiency between c5 and c6 situations.
Latency and throughput measured with 10000 Inference queries to Sage maker endpoints.
| E2E Latency of Inference Endpoint and Price evaluation | |||||
| P50(ms) | P90(ms) | Queries/Sec | $/1M Queries | Relative $/Efficiency | |
| C5.2xLarge-FP32 | 76.6 | 125.3 | 11.5 | $10.2 | 1.0x |
| c6i.2xLarge-FP32 | 70 | 110.8 | 13 | $9.0 | 1.1x |
| c6i.2xLarge-INT8 | 35.7 | 48.9 | 25.56 | $4.5 | 2.3x |
INT8 fashions are anticipated to offer 2–4 instances sensible efficiency enhancements with lower than 1% accuracy loss for many of the fashions. Above desk covers overhead latency (NW and demo software)
Accuracy for BERT-base mannequin
The next desk summarizes the accuracy for the INT8 mannequin with the SQUaD v1.1 dataset.
| Metric | FP32 | INT8 |
| Actual Match | 85.8751 | 85.5061 |
| F1 | 92.0807 | 91.8728 |
The GitHub repo comes with the scripts to examine the accuracy of the SQuAD dataset. Confer with invoke-INT8.py and invoke-FP32.py scripts for testing.
Intel Extension for PyTorch
Intel® Extension for PyTorch* (an open–supply challenge at GitHub) extends PyTorch with optimizations for further efficiency boosts on Intel {hardware}. Many of the optimizations shall be included in inventory PyTorch releases ultimately, and the intention of the extension is to ship up-to-date options and optimizations for PyTorch on Intel {hardware}. Examples embody AVX-512 Vector Neural Community Directions (AVX512 VNNI) and Intel® Superior Matrix Extensions (Intel® AMX).
The next determine illustrates the Intel Extension for PyTorch structure.

For extra detailed consumer steering (options, efficiency tuning, and extra) for Intel® Extension for PyTorch, consult with Intel® Extension for PyTorch* user guidance.
In regards to the Authors
 Rohit Chowdhary is a Sr. Options Architect within the Strategic Accounts group at AWS.
Rohit Chowdhary is a Sr. Options Architect within the Strategic Accounts group at AWS.
 Aniruddha Kappagantu is a Software program Growth Engineer within the AI Platforms group at AWS.
Aniruddha Kappagantu is a Software program Growth Engineer within the AI Platforms group at AWS.
 Antony Vance is an AI Architect at Intel with 19 years of expertise in laptop imaginative and prescient, machine studying, deep studying, embedded software program, GPU, and FPGA.
Antony Vance is an AI Architect at Intel with 19 years of expertise in laptop imaginative and prescient, machine studying, deep studying, embedded software program, GPU, and FPGA.




