The Technical Components of GPT-4
OpenAI has introduced the creation of GPT-4, a big multimodal mannequin able to accepting picture and textual content inputs whereas emitting textual content outputs. The mannequin displays human-level efficiency on numerous skilled and educational benchmarks, although it’s much less succesful than people in lots of real-world situations. For example, GPT-4’s simulated bar examination rating is across the high 10% of check takers, in comparison with GPT-3.5’s rating, which was across the backside 10%. OpenAI spent 6 months iteratively aligning GPT-4 utilizing classes from their adversarial testing program and different sources. Consequently, the mannequin performs higher than earlier variations in areas comparable to factuality, steerability, and staying inside guardrails, however there’s nonetheless room for enchancment.
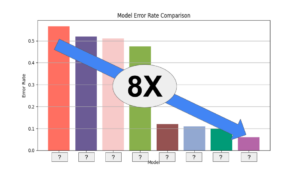
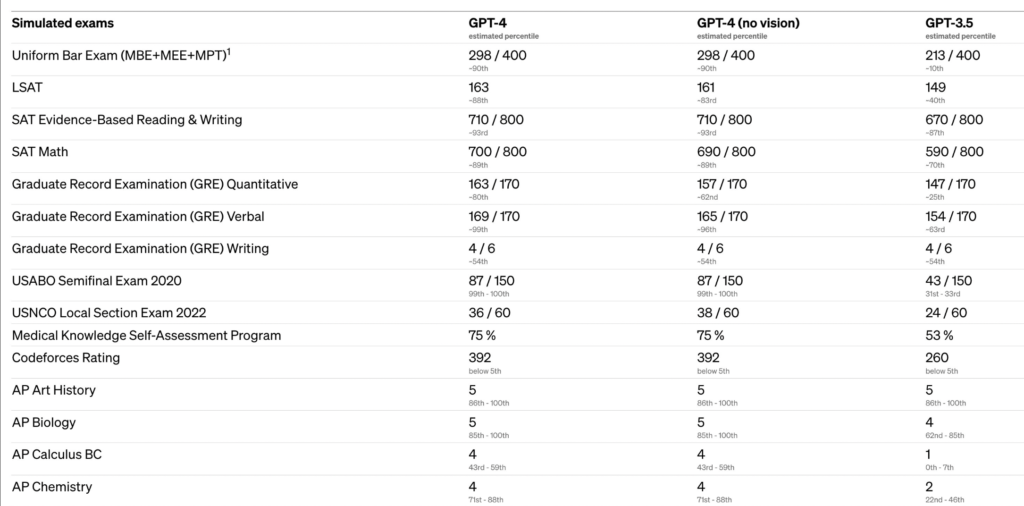
The distinction between GPT-3.5 and GPT-4 could also be refined in informal conversations, however it turns into obvious when coping with complicated duties. GPT-4 outperforms GPT-3.5 concerning reliability, creativity, and talent to deal with nuanced directions. Numerous benchmarks have been used to check the distinction between the 2 fashions, together with simulated exams initially meant for people. The checks used have been both the most recent publicly accessible or 2022-2023 follow exams explicitly bought for this function. No particular coaching was executed for these exams, though the mannequin beforehand encountered a small portion of the issues throughout coaching. The outcomes obtained are believed to be consultant and might be discovered within the technical report.
A few of the outcomes of the comparisons
Visible inputs
GPT-4 can course of textual content and picture inputs, permitting customers to specify any language or imaginative and prescient job. It could actually generate textual content outputs comparable to pure language and code based mostly on inputs that embody textual content and pictures in numerous domains, comparable to paperwork with textual content, images, diagrams, or screenshots. GPT-4 shows comparable capabilities on text-only and blended inputs. It will also be enhanced with strategies developed for text-only language fashions like few-shot and chain-of-thought prompting. Nevertheless, the picture enter characteristic continues to be within the analysis part and isn’t publicly accessible.
Limitations
Regardless of its spectacular capabilities, GPT-4 shares comparable limitations with its predecessors. Considered one of its main limitations is its lack of full reliability, because it nonetheless tends to supply incorrect info and reasoning errors, generally generally known as “hallucinations.” Subsequently, it’s essential to train warning when using language mannequin outputs, particularly in high-stakes conditions. To deal with this difficulty, totally different approaches, comparable to human evaluate, grounding with extra context, or avoiding high-stakes makes use of altogether, needs to be adopted based mostly on particular use circumstances.
Though it nonetheless faces reliability challenges, GPT-4 reveals vital enhancements in decreasing hallucinations in comparison with earlier fashions. Inside adversarial factuality evaluations point out that GPT-4 scores 40% greater than the most recent GPT-3.5 mannequin, which improved significantly from earlier iterations.
The language mannequin, GPT-4, could exhibit biases in its outputs regardless of efforts to cut back them. The mannequin’s data is proscribed to occasions earlier than September 2021 and must be taught from expertise. It could actually generally make reasoning errors, be overly gullible, and fail at laborious issues, just like people. GPT-4 could confidently make incorrect predictions, and its calibration is diminished via the present post-training course of. Nevertheless, efforts are being made to make sure that the mannequin has cheap default behaviors that mirror a variety of person values and might be custom-made inside sure bounds with enter from the general public.
Take a look at the Technical Paper and OpenAI Article. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd yr undergraduate, presently pursuing her B.Tech from Indian Institute of Expertise(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Information science and AI and an avid reader of the most recent developments in these fields.