RLPrompt: Optimizing Discrete Textual content Prompts with Reinforcement Studying – Machine Studying Weblog | ML@CMU
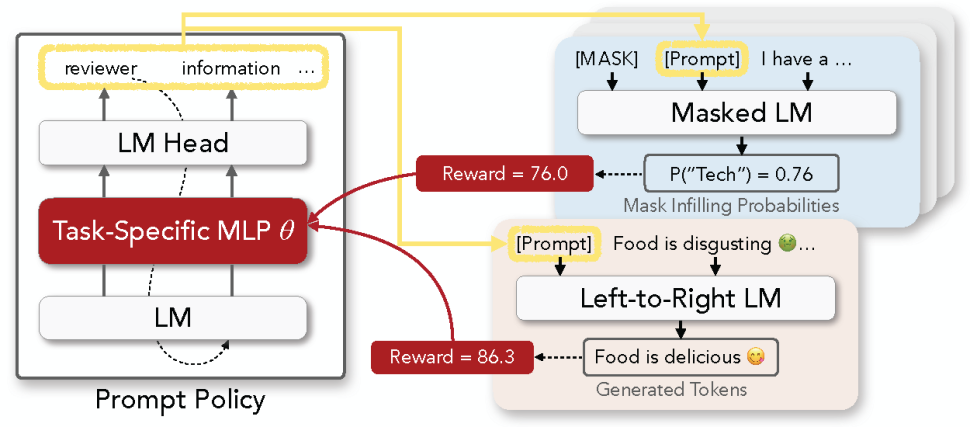
Determine 1: Overview of RL Immediate for discrete immediate optimization. All language fashions (LMs) are frozen. We construct our coverage community by coaching a task-specific multi-layer perceptron (MLP) community inserted right into a frozen pre-trained LM. The determine above illustrates 1) era of a immediate (left), 2) instance usages in a masked LM for classification (prime proper) and a left-to-right LM for era (backside proper), and three) replace of the MLP utilizing RL reward alerts (purple arrows).
TL;DR: Prompting allows giant language fashions (LLMs) to carry out varied NLP duties with out altering the mannequin. Discrete prompts have many fascinating properties, however are tough to optimize. We suggest an environment friendly method utilizing reinforcement studying, which reveals superior efficiency and facilitates wealthy interpretations and analyses. You may simply adapt it to your personal duties utilizing our library here.
Prompting has emerged as a promising method to fixing a variety of NLP issues utilizing giant pre-trained language fashions (LMs), together with left-to-right fashions resembling GPTs and masked LMs resembling BERT, RoBERTa, and so forth.
In comparison with standard fine-tuning that expensively updates the large LM parameters for every downstream activity, prompting concatenates the inputs with a further piece of textual content that steers the LM to provide the specified outputs. A key query with prompting is easy methods to discover the optimum prompts to enhance the LM’s efficiency on varied duties, usually with only some coaching examples.
Most current work resorts to tuning mushy immediate (e.g., embeddings) which falls wanting interpretability, reusability throughout LMs, and applicability when gradients usually are not accessible. Discrete immediate, then again, is tough to optimize, and is usually created by “enumeration (e.g., paraphrasing)-then-selection” heuristics that don’t discover the immediate house systematically.
In our EMNLP 2022 paper, we as a substitute suggest RLPrompt, an environment friendly discrete immediate optimization method with reinforcement studying (RL). RLPrompt is flexibly relevant to various kinds of LMs (e.g., BERT and GPTs) for each classification and era duties. Experiments on few-shot classification and unsupervised textual content model switch present superior efficiency over a variety of current finetuning or prompting strategies.
Curiously, the ensuing optimized prompts are sometimes ungrammatical gibberish textual content; and surprisingly, these gibberish prompts are transferable between completely different LMs to retain important efficiency, indicating LMs could have grasped shared constructions for prompting, however don’t observe human language patterns.
Discrete Immediate Optimization with RL
This paper presents RLPrompt, a brand new discrete immediate optimization method based mostly on reinforcement studying (RL). This method brings collectively a variety of fascinating properties for environment friendly use on numerous duties and LMs (see the desk beneath).
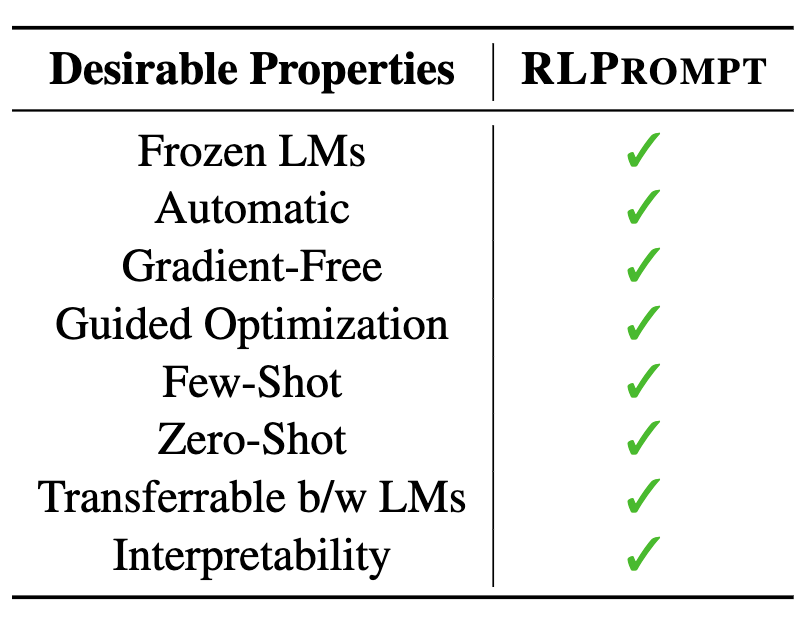
Crucially, slightly than immediately enhancing the discrete tokens, which has been tough and inefficient, RLPrompt trains a coverage community that generates the specified prompts. Discrete immediate optimization thus quantities to studying a small variety of coverage parameters which we set as an MLP layer inserted right into a frozen compact mannequin resembling distilGPT-2. We describe the precise formulations in Part §2.1-2.3 of our paper.
This formulation additionally permits us to make use of off-the-shelf RL algorithms (e.g., soft Q-learning) that be taught the coverage with arbitrary reward features—outlined both with out there information (e.g., in few-shot classification) or different weak alerts when no supervised information is accessible (e.g., in controllable textual content era).
Reward Stabilization
Then again, RL for immediate optimization poses new challenges to studying effectivity: the big black-box LM presents a extremely advanced atmosphere that, given the immediate (i.e., actions), goes by means of an extended sequence of advanced transitions (e.g., studying the enter and inferring the output) earlier than computing the rewards. This makes the reward alerts extraordinarily unstable and laborious to be taught from.
To beat this issue, we suggest two easy but surprisingly efficient methods to stabilize the rewards and enhance the optimization effectivity.
- Normalizing the coaching sign by computing the z-score of rewards for a similar enter.
- Designing piecewise reward features that present a sparse, qualitative bonus to fascinating behaviors (e.g., sure accuracy on sure class).
We describe extra particulars in Part §2.4 of our paper.
Experiments
We consider our method on each classification (within the few-shot setting) and era (unsupervised textual content model switch), and carry out wealthy analyses for brand spanking new insights on LM prompting. We describe implementation particulars resembling reward perform design in Part §3 our paper, and publish the code at our Github codebase.
Few-Shot Textual content Classification
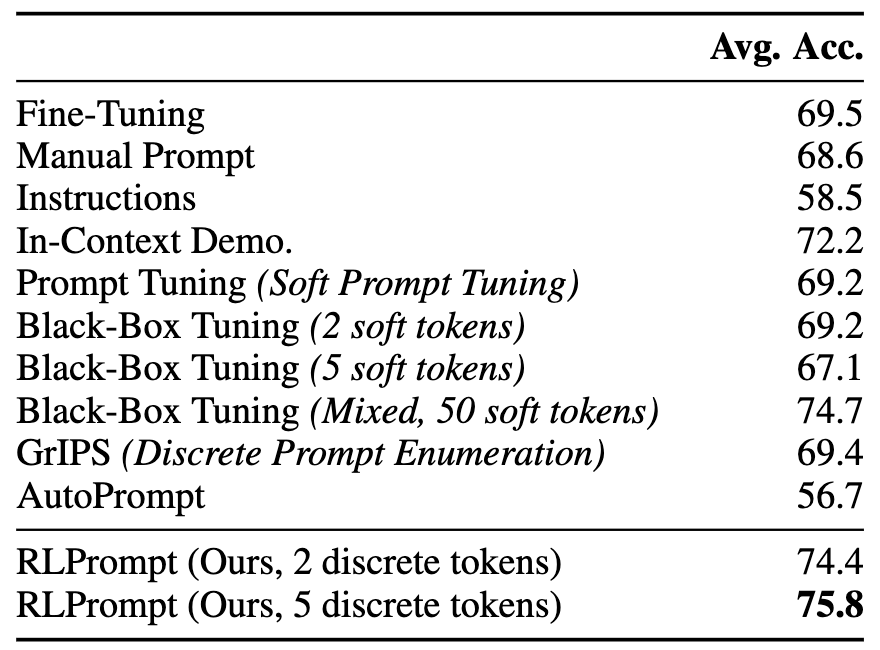
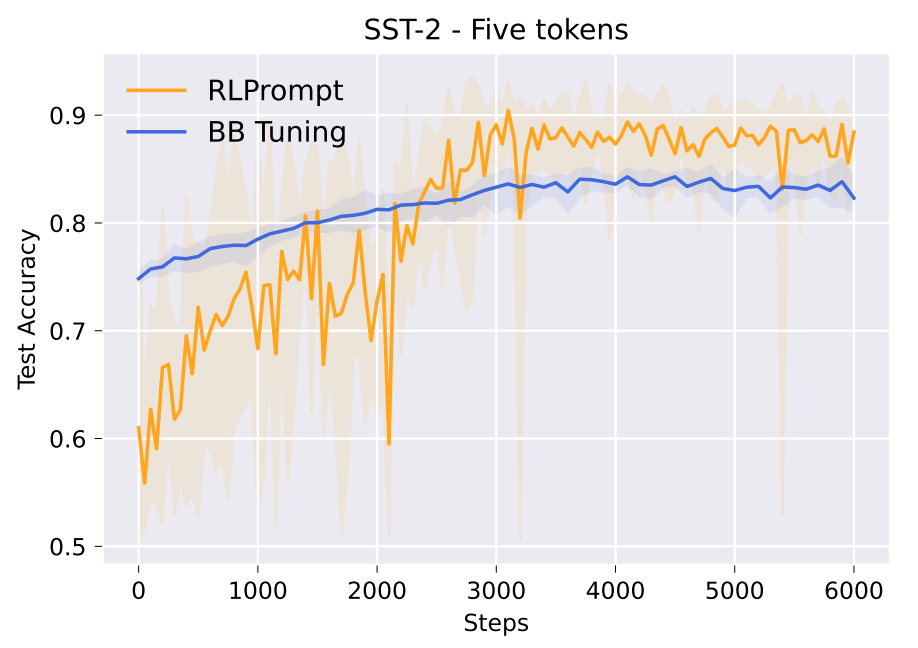
For few-shot classification, we observe earlier work and experiment on fashionable sentiment and matter classification duties, utilizing 16 examples per class for both training and validation. Outcomes utilizing RoBERTa-large (left desk beneath) present our method enhancing over a variety of fine-tuning and prompting strategies, and is as environment friendly to optimize as related strategies that tune mushy prompts (e.g., proper determine beneath). We report detailed dataset-level leads to Part §3.1 of our paper.
Unsupervised Textual content Model Switch
For textual content model switch, we consider on the favored Yelp sentiment switch dataset utilizing fashionable computerized metrics for content material preservation, model accuracy, and fluency, and report their sentence-level joint product (J(cdot)) beneath. Our full paper additionally consists of few-shot experiments on the Shakespeare dataset and human evaluations.
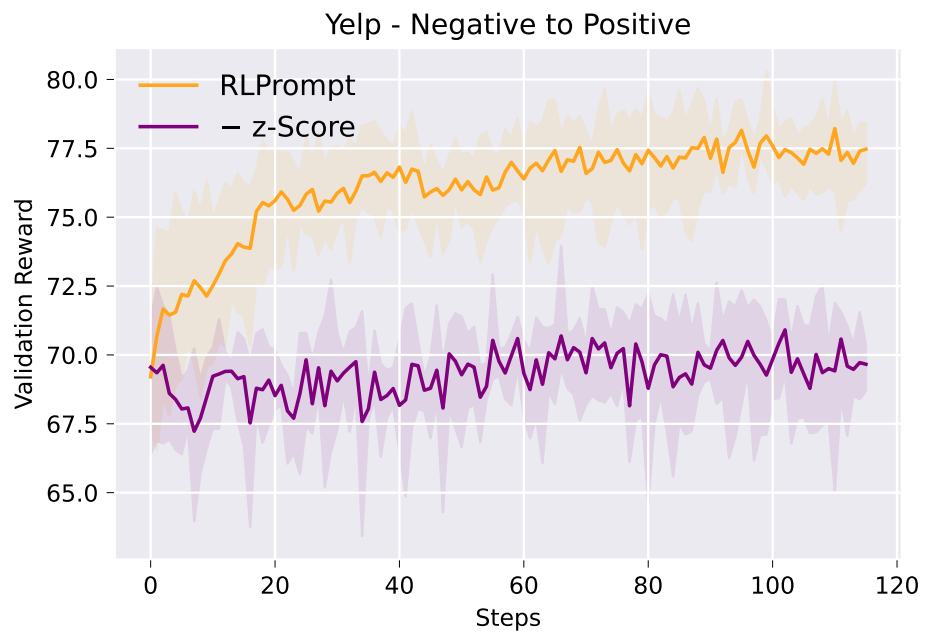
Outcomes utilizing GPT-2 (left desk beneath) present our methodology outperforms or competes with varied fine-tuning and prompting baselines, together with DiRR which expensively fine-tunes all parameters of a GPT-2 mannequin. Ablation research (proper determine beneath) reveals that our proposed reward normalization method is essential to optimization success. We describe the complete analysis leads to Part §3.2 of our paper.

Evaluation
Optimum Prompts Don’t Comply with Human Language
The ensuing discrete prompts additionally facilitate wealthy interpretations and analyses for brand spanking new insights into LM prompting. Particularly, the optimized prompts, although inducing robust activity efficiency, are usually gibberish textual content with out clear human-understandable that means (e.g., desk beneath), echoing latest analysis (e.g., Webson and Pavlick (2021), Zhao et al., (2021), and Prasad et al., (2022)) that LMs making use of prompts don’t essentially observe human language patterns.

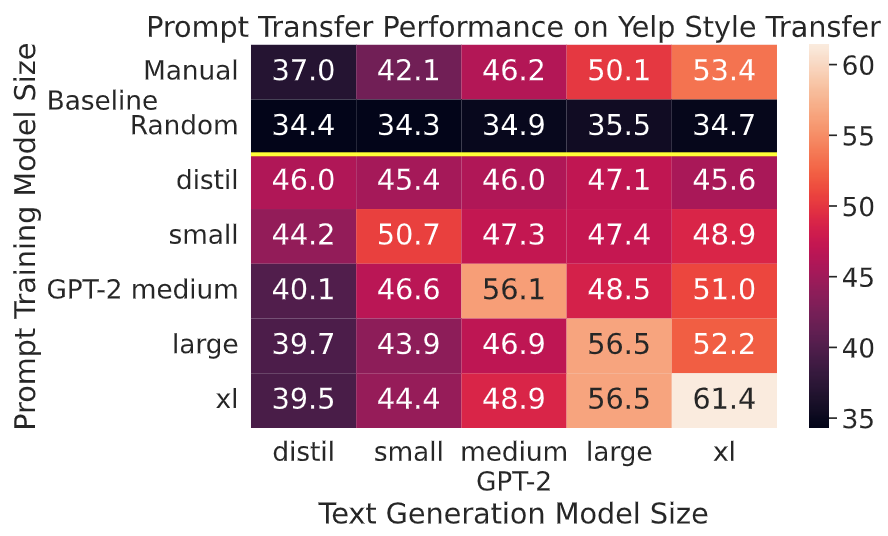
Realized Prompts Switch Trivially Throughout LMs
Maybe surprisingly, these gibberish prompts realized with one LM can be utilized in different LMs for important efficiency, indicating that these completely different pre-trained LMs have grasped shared constructions for prompting (e.g., figures beneath).

Conclusion
We’ve introduced RLPrompt, an environment friendly and versatile method for discrete immediate optimization utilizing RL, which improves over a variety of fine-tuning and prompting strategies in experiments on few-shot classification and unsupervised textual content model switch.
Evaluation reveals that robust optimized prompts are incoherent however transferable between LMs for exceptional efficiency. The statement opens up many promising potentialities for prompting, resembling studying prompts cheaply from smaller fashions and performing inference with bigger fashions. We’re excited to discover additional.






