Scale AI coaching and inference for drug discovery by Amazon EKS and Karpenter
It is a visitor submit co-written with the management staff of Iambic Therapeutics.
Iambic Therapeutics is a drug discovery startup with a mission to create revolutionary AI-driven applied sciences to carry higher medicines to most cancers sufferers, quicker.
Our superior generative and predictive synthetic intelligence (AI) instruments allow us to go looking the huge house of potential drug molecules quicker and extra successfully. Our applied sciences are versatile and relevant throughout therapeutic areas, protein courses, and mechanisms of motion. Past creating differentiated AI instruments, we have now established an built-in platform that merges AI software program, cloud-based knowledge, scalable computation infrastructure, and high-throughput chemistry and biology capabilities. The platform each allows our AI—by supplying knowledge to refine our fashions—and is enabled by it, capitalizing on alternatives for automated decision-making and knowledge processing.
We measure success by our means to supply superior scientific candidates to deal with pressing affected person want, at unprecedented velocity: we superior from program launch to scientific candidates in simply 24 months, considerably quicker than our rivals.
On this submit, we deal with how we used Karpenter on Amazon Elastic Kubernetes Service (Amazon EKS) to scale AI coaching and inference, that are core components of the Iambic discovery platform.
The necessity for scalable AI coaching and inference
Each week, Iambic performs AI inference throughout dozens of fashions and hundreds of thousands of molecules, serving two main use circumstances:
- Medicinal chemists and different scientists use our internet utility, Perception, to discover chemical house, entry and interpret experimental knowledge, and predict properties of newly designed molecules. All of this work is completed interactively in actual time, creating a necessity for inference with low latency and medium throughput.
- On the identical time, our generative AI fashions routinely design molecules concentrating on enchancment throughout quite a few properties, looking hundreds of thousands of candidates, and requiring huge throughput and medium latency.
Guided by AI applied sciences and skilled drug hunters, our experimental platform generates hundreds of distinctive molecules every week, and every is subjected to a number of organic assays. The generated knowledge factors are routinely processed and used to fine-tune our AI fashions each week. Initially, our mannequin fine-tuning took hours of CPU time, so a framework for scaling mannequin fine-tuning on GPUs was crucial.
Our deep studying fashions have non-trivial necessities: they’re gigabytes in dimension, are quite a few and heterogeneous, and require GPUs for quick inference and fine-tuning. Trying to cloud infrastructure, we would have liked a system that enables us to entry GPUs, scale up and down shortly to deal with spiky, heterogeneous workloads, and run massive Docker photos.
We wished to construct a scalable system to assist AI coaching and inference. We use Amazon EKS and had been in search of one of the best resolution to auto scale our employee nodes. We selected Karpenter for Kubernetes node auto scaling for numerous causes:
- Ease of integration with Kubernetes, utilizing Kubernetes semantics to outline node necessities and pod specs for scaling
- Low-latency scale-out of nodes
- Ease of integration with our infrastructure as code tooling (Terraform)
The node provisioners assist easy integration with Amazon EKS and different AWS assets similar to Amazon Elastic Compute Cloud (Amazon EC2) cases and Amazon Elastic Block Store volumes. The Kubernetes semantics utilized by the provisioners assist directed scheduling utilizing Kubernetes constructs similar to taints or tolerations and affinity or anti-affinity specs; additionally they facilitate management over the quantity and forms of GPU cases which may be scheduled by Karpenter.
Answer overview
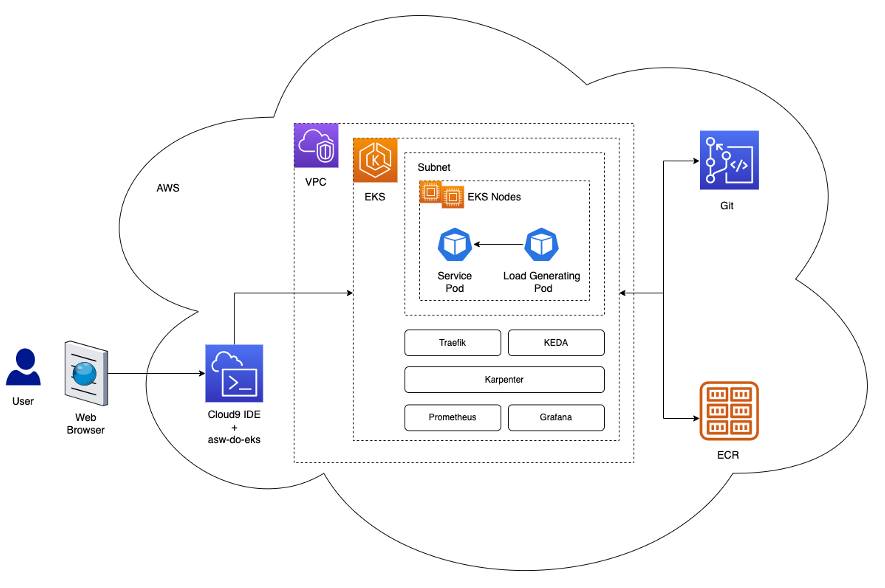
On this part, we current a generic structure that’s much like the one we use for our personal workloads, which permits elastic deployment of fashions utilizing environment friendly auto scaling primarily based on customized metrics.
The next diagram illustrates the answer structure.

The structure deploys a simple service in a Kubernetes pod inside an EKS cluster. This could possibly be a mannequin inference, knowledge simulation, or every other containerized service, accessible by HTTP request. The service is uncovered behind a reverse-proxy utilizing Traefik. The reverse proxy collects metrics about calls to the service and exposes them by way of a regular metrics API to Prometheus. The Kubernetes Occasion Pushed Autoscaler (KEDA) is configured to routinely scale the variety of service pods, primarily based on the customized metrics accessible in Prometheus. Right here we use the variety of requests per second as a customized metric. The identical architectural method applies in case you select a special metric on your workload.
Karpenter displays for any pending pods that may’t run because of lack of adequate assets within the cluster. If such pods are detected, Karpenter provides extra nodes to the cluster to supply the required assets. Conversely, if there are extra nodes within the cluster than what is required by the scheduled pods, Karpenter removes a number of the employee nodes and the pods get rescheduled, consolidating them on fewer cases. The variety of HTTP requests per second and variety of nodes will be visualized utilizing a Grafana dashboard. To display auto scaling, we run a number of simple load-generating pods, which ship HTTP requests to the service utilizing curl.
Answer deployment
Within the step-by-step walkthrough, we use AWS Cloud9 as an surroundings to deploy the structure. This permits all steps to be accomplished from an internet browser. You can too deploy the answer from a neighborhood pc or EC2 occasion.
To simplify deployment and enhance reproducibility, we comply with the ideas of the do-framework and the construction of the depend-on-docker template. We clone the aws-do-eks mission and, utilizing Docker, we construct a container picture that’s outfitted with the required tooling and scripts. Throughout the container, we run by all of the steps of the end-to-end walkthrough, from creating an EKS cluster with Karpenter to scaling EC2 instances.
For the instance on this submit, we use the next EKS cluster manifest:
apiVersion: eksctl.io/v1alpha5
variety: ClusterConfig
metadata:
identify: do-eks-yaml-karpenter
model: '1.28'
area: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- identify: aws-ebs-csi-driver
model: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- identify: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueThis manifest defines a cluster named do-eks-yaml-karpenter with the EBS CSI driver put in as an add-on. A managed node group with two c5.xlarge nodes is included to run system pods which can be wanted by the cluster. The employee nodes are hosted in non-public subnets, and the cluster API endpoint is public by default.
You may additionally use an present EKS cluster as an alternative of making one. We deploy Karpenter by following the instructions within the Karpenter documentation, or by operating the next script, which automates the deployment directions.
The next code reveals the Karpenter configuration we use on this instance:
apiVersion: karpenter.sh/v1beta1
variety: NodePool
metadata:
identify: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
function: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
variety: EC2NodeClass
identify: default
necessities:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
variety: EC2NodeClass
metadata:
identify: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
function: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueWe outline a default Karpenter NodePool with the next necessities:
- Karpenter can launch cases from each
spotandon-demandcapability swimming pools - Cases have to be from the “
c” (compute optimized), “m” (common function), “r” (reminiscence optimized), or “g” and “p” (GPU accelerated) computing households - Occasion technology have to be larger than 2; for instance,
g3is suitable, howeverg2isn’t
The default NodePool additionally defines disruption insurance policies. Underutilized nodes will likely be eliminated so pods will be consolidated to run on fewer or smaller nodes. Alternatively, we will configure empty nodes to be eliminated after the required time interval. The expireAfter setting specifies the utmost lifetime of any node, earlier than it’s stopped and changed if obligatory. This helps scale back safety vulnerabilities in addition to keep away from points which can be typical for nodes with lengthy uptimes, similar to file fragmentation or reminiscence leaks.
By default, Karpenter provisions nodes with a small root quantity, which will be inadequate for operating AI or machine studying (ML) workloads. A number of the deep studying container photos will be tens of GB in dimension, and we want to verify there’s sufficient cupboard space on the nodes to run pods utilizing these photos. To try this, we outline EC2NodeClass with blockDeviceMappings, as proven within the previous code.
Karpenter is answerable for auto scaling on the cluster stage. To configure auto scaling on the pod stage, we use KEDA to outline a customized useful resource referred to as ScaledObject, as proven within the following code:
apiVersion: keda.sh/v1alpha1
variety: ScaledObject
metadata:
identify: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
identify: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- sort: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.native:80
metricName: http_requests_total
threshold: '1'
question: price(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])The previous manifest defines a ScaledObject named keda-prometheus-hpa, which is answerable for scaling the php-apache deployment and at all times retains no less than one duplicate operating. It scales the pods of this deployment primarily based on the metric http_requests_total accessible in Prometheus obtained by the required question, and targets to scale up the pods so that every pod serves no multiple request per second. It scales down the replicas after the request load has been beneath the edge for longer than 30 seconds.
The deployment spec for our instance service accommodates the next resource requests and limits:
assets:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1With this configuration, every of the service pods will use precisely one NVIDIA GPU. When new pods are created, they are going to be in Pending state till a GPU is on the market. Karpenter provides GPU nodes to the cluster as wanted to accommodate the pending pods.
A load-generating pod sends HTTP requests to the service with a pre-set frequency. We improve the variety of requests by growing the variety of replicas within the load-generator deployment.
A full scaling cycle with utilization-based node consolidation is visualized in a Grafana dashboard. The next dashboard reveals the variety of nodes within the cluster by occasion sort (prime), the variety of requests per second (backside left), and the variety of pods (backside proper).

We begin with simply the 2 c5.xlarge CPU cases that the cluster was created with. Then we deploy one service occasion, which requires a single GPU. Karpenter provides a g4dn.xlarge occasion to accommodate this want. We then deploy the load generator, which causes KEDA so as to add extra service pods and Karpenter provides extra GPU cases. After optimization, the state settles on one p3.8xlarge occasion with 8 GPUs and one g5.12xlarge occasion with 4 GPUs.
Once we scale the load-generating deployment to 40 replicas, KEDA creates further service pods to keep up the required request load per pod. Karpenter provides g4dn.metallic and g4dn.12xlarge nodes to the cluster to supply the wanted GPUs for the extra pods. Within the scaled state, the cluster accommodates 16 GPU nodes and serves about 300 requests per second. Once we scale down the load generator to 1 duplicate, the reverse course of takes place. After the cooldown interval, KEDA reduces the variety of service pods. Then as fewer pods run, Karpenter removes the underutilized nodes from the cluster and the service pods get consolidated to run on fewer nodes. When the load generator pod is eliminated, a single service pod on a single g4dn.xlarge occasion with 1 GPU stays operating. Once we take away the service pod as nicely, the cluster is left within the preliminary state with solely two CPU nodes.
We are able to observe this habits when the NodePool has the setting consolidationPolicy: WhenUnderutilized.
With this setting, Karpenter dynamically configures the cluster with as few nodes as potential, whereas offering adequate assets for all pods to run and in addition minimizing price.
The scaling habits proven within the following dashboard is noticed when the NodePool consolidation coverage is ready to WhenEmpty, together with consolidateAfter: 30s.

On this state of affairs, nodes are stopped solely when there are not any pods operating on them after the cool-off interval. The scaling curve seems clean, in comparison with the utilization-based consolidation coverage; nevertheless, it may be seen that extra nodes are used within the scaled state (22 vs. 16).
General, combining pod and cluster auto scaling makes certain that the cluster scales dynamically with the workload, allocating assets when wanted and eradicating them when not in use, thereby maximizing utilization and minimizing price.
Outcomes
Iambic used this structure to allow environment friendly use of GPUs on AWS and migrate workloads from CPU to GPU. Through the use of EC2 GPU powered cases, Amazon EKS, and Karpenter, we had been in a position to allow quicker inference for our physics-based fashions and quick experiment iteration occasions for utilized scientists who depend on coaching as a service.
The next desk summarizes a number of the time metrics of this migration.
| Activity | CPUs | GPUs |
| Inference utilizing diffusion fashions for physics-based ML fashions | 3,600 seconds |
100 seconds (because of inherent batching of GPUs) |
| ML mannequin coaching as a service | 180 minutes | 4 minutes |
The next desk summarizes a few of our time and value metrics.
| Activity | Efficiency/Value | |
| CPUs | GPUs | |
| ML mannequin coaching |
240 minutes common $0.70 per coaching process |
20 minutes common $0.38 per coaching process |
Abstract
On this submit, we showcased how Iambic used Karpenter and KEDA to scale our Amazon EKS infrastructure to satisfy the latency necessities of our AI inference and coaching workloads. Karpenter and KEDA are highly effective open supply instruments that assist auto scale EKS clusters and workloads operating on them. This helps optimize compute prices whereas assembly efficiency necessities. You’ll be able to try the code and deploy the identical structure in your personal surroundings by following the whole walkthrough on this GitHub repo.
Concerning the Authors
 Matthew Welborn is the director of Machine Studying at Iambic Therapeutics. He and his staff leverage AI to speed up the identification and improvement of novel therapeutics, bringing life-saving medicines to sufferers quicker.
Matthew Welborn is the director of Machine Studying at Iambic Therapeutics. He and his staff leverage AI to speed up the identification and improvement of novel therapeutics, bringing life-saving medicines to sufferers quicker.
 Paul Whittemore is a Principal Engineer at Iambic Therapeutics. He helps supply of the infrastructure for the Iambic AI-driven drug discovery platform.
Paul Whittemore is a Principal Engineer at Iambic Therapeutics. He helps supply of the infrastructure for the Iambic AI-driven drug discovery platform.
 Alex Iankoulski is a Principal Options Architect, ML/AI Frameworks, who focuses on serving to prospects orchestrate their AI workloads utilizing containers and accelerated computing infrastructure on AWS.
Alex Iankoulski is a Principal Options Architect, ML/AI Frameworks, who focuses on serving to prospects orchestrate their AI workloads utilizing containers and accelerated computing infrastructure on AWS.