Extending PAC Studying to a Strategic Classification Setting | by Jonathan Yahav | Apr, 2024
Why Strategic Classification Is Helpful: Motivation
Binary classification is a cornerstone of machine studying. It was the primary subject I used to be taught after I took an introductory course on the topic; the real-world instance we examined again then was the issue of classifying emails as both spam or not spam. Different widespread examples embrace diagnosing a illness and screening resumes for a job posting.
The fundamental binary classification setup is intuitive and simply relevant to our day-to-day lives, and it might probably function a useful demonstration of the methods we are able to leverage machine studying to resolve human issues. However how usually will we cease to think about the truth that folks normally have a vested curiosity within the classification end result of such issues? Spammers need their emails to make it by spam filters, not everybody needs their COVID check to come back again optimistic, and job seekers could also be prepared to stretch the reality to attain an interview. The info factors aren’t simply knowledge factors — they’re lively individuals within the classification course of, usually aiming to recreation the system to their very own profit.
In gentle of this, the canonical binary classification setup appears a bit simplistic. Nevertheless, the complexity of reexamining binary classification whereas tossing out the implicit assumption that the objects we want to classify are uninfluenced by exterior stakes sounds unmanageable. The preferences that would have an effect on the classification course of are available so many various varieties — how may we presumably take all of them under consideration?
It seems that, beneath sure assumptions, we are able to. By way of a intelligent generalization of the canonical binary classification mannequin, the paper’s authors exhibit the feasibility of designing computationally-tractable, gaming-resistant classification algorithms.
From Knowledge Factors to Rational Brokers: Choice Lessons
First, if we need to be as life like as attainable, we have now to correctly think about the extensive breadth of varieties that real-world preferences can take amongst rational brokers. The paper mentions 5 more and more basic classes of preferences (which I’ll name desire lessons). The names I’ll use for them are my very own, however are primarily based on the terminology used within the paper.
- Neutral: No preferences, identical to in canonical binary classification.
- Homogeneous: An identical preferences throughout all of the brokers concerned. For instance, inside the set of people who find themselves prepared to fill out the paperwork obligatory to use for a tax refund, we are able to fairly count on that everybody is equally motivated to get their a reimbursement (i.e., to be labeled positively).
- Adversarial: Equally-motivated brokers goal to induce the alternative of their true labels. Consider bluffing in poker — a participant with a weak hand (negatively labeled) needs their opponents to suppose they’ve a robust hand (positively labeled), and vice versa. For the “equally-motivated” half, think about all gamers wager the identical quantity.
- Generalized Adversarial: Unequally-motivated brokers goal to induce the alternative of their true labels. This isn’t too totally different from the plain Adversarial case. Nonetheless, it must be straightforward to know how a participant with $100 {dollars} on the road can be prepared to go to larger lengths to deceive their opponents than a participant betting $1.
- Common Strategic: “Something goes.” This desire class goals to embody any set of preferences conceivable. All 4 of the beforehand talked about desire lessons are strict subsets of this one. Naturally, this class is the primary focus of the paper, and many of the outcomes demonstrated within the paper apply to it. The authors give the great instance of faculty purposes, the place “college students [who] have heterogeneous preferences over universities […] might manipulate their utility supplies in the course of the admission course of.”
How can the canonical classification setup be modified to account for such wealthy agent preferences? The reply is astoundingly easy. As an alternative of limiting our scope to (x, y) ∈ X × { -1, 1 }, we think about knowledge factors of the shape (x, y, r) ∈ X × { -1, 1 } × R. A degree’s r worth represents its desire, which we are able to break down into two equally vital parts:
- The signal of r signifies whether or not the info level needs to be positively or negatively labeled (r > 0 or r < 0, respectively).
- The absolute worth of r specifies how robust the info level’s desire is. For instance, a knowledge level with r = 10 can be far more strongly motivated to control its function vector x to make sure it finally ends up being positively labeled than a knowledge level with r = 1.
What determines the desire class we function inside is the set R. We will formally outline every of the aforementioned desire lessons by way of R and see how the formal definitions align with their intuitive descriptions and examples:
- Neutral: R = { 0 }. (This makes it abundantly clear that the strategic setup is only a generalization of the canonical setup.)
- Homogeneous: R = { 1 }.
- Adversarial: R = { -1, 1 }, with the added requirement that every one knowledge factors favor to be labeled as the alternative of their true labels.
- Generalized Adversarial: R ⊆ ℝ (and all knowledge factors favor to be labeled as the alternative of their true labels.)
- Common Strategic: R ⊆ ℝ.
Giving Choice Magnitude That means: Price Features
Clearly, although, R by itself isn’t sufficient to assemble a whole basic strategic framework. The very concept of a knowledge level’s desire having a sure magnitude is meaningless with out tying it to the fee the info level incurs in manipulating its function vector. In any other case, any knowledge level with a optimistic r, regardless of how small, would don’t have any purpose to not manipulate its function vector advert infinitum. That is the place the idea of value capabilities comes into play.
Let c: X × X → ℝ⁺. For simplicity, we are going to assume (because the paper’s authors do) that c is induced by seminorms. We are saying {that a} check knowledge level (x, y, r) might rework its function vector x into z ∈ X with value c(z; x). It’s vital to notice on this context that the paper assumes that the coaching knowledge is unmanipulated.
We will divide value capabilities into two classes, with the previous being a subset of the latter. An instance-invariant value perform is similar throughout all knowledge factors. To place it extra formally:
∃ℓ: X × X → ℝ⁺ . ∀(x, y, r) ∈ X × { -1, 1 } × R . ∀z ∈ X . c(z; x) = ℓ(z – x)
I.e., there exists a perform ℓ such that for all knowledge factors and all potential manipulated function vectors, c(z ; x) merely takes the worth of ℓ(z – x).
An instance-wise value perform might fluctuate between knowledge factors. Formally:
∀(x, y, r) ∈ X × { -1, 1 } × R . ∃ℓₓ: X × X → ℝ⁺ .∀z ∈ X . c(z; x) = ℓₓ(z – x)
I.e., every knowledge level can have its personal perform, ℓₓ, and c(z; x) takes the worth of ℓₓ(z – x) for every particular person knowledge level.
As we are going to see within the closing article on this sequence, whereas the distinction between the 2 forms of value capabilities could appear refined, instance-wise value capabilities are considerably extra expressive and more durable to study.
Choice Lessons and Price Features in Motion: An Instance
Let’s check out an instance given within the paper to assist hammer dwelling the points of the setup we’ve coated thus far.

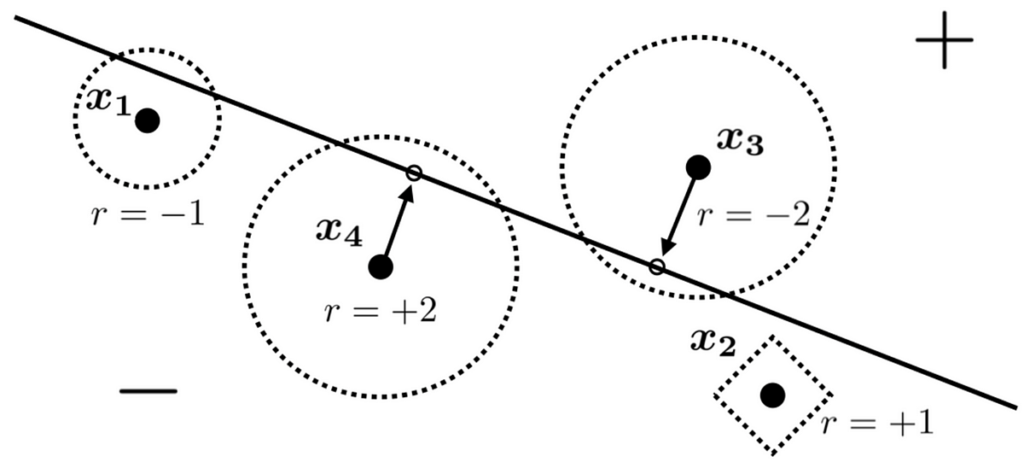
On this instance, we have now a choice boundary induced by a linear binary classifier and 4 knowledge factors with particular person preferences. Common strategic is the one relevant desire class on this case.
The dotted perimeter round every xᵢ reveals the manipulated function vectors z to which it could value the purpose precisely 1 to maneuver. Since we assume the fee perform is induced by seminorms, every thing inside a fringe has a price of lower than 1 for the corresponding knowledge level to maneuver to. We will simply inform that the fee perform on this instance varies from knowledge level to knowledge level, which implies it’s instance-wise.
As we are able to see, the leftmost knowledge level (x₁, -1, -1) has no incentive to cross the choice boundary since it’s on the adverse aspect of the choice boundary whereas additionally having a adverse desire. (x₄, -1, 2), nonetheless, needs to be positively labeled, and for the reason that reward for manipulating x₄ to cross the boundary (which is 2) outweighs the fee of doing so (which is lower than 1), it is smart to undergo with the manipulation. (x₃, 1, -2) is symmetric to (x₄, -1, 2), additionally deciding to control its function to realize its desired classification end result. Lastly, (x₂, -1, 1), the fee perform of which we are able to see relies on taxicab distance, opts to remain put no matter its desire to be positively labeled. It is because the price of manipulating x₂ to cross the choice boundary can be larger than 1, surpassing the reward the info level would stand to realize by doing so.
Assuming the brokers our knowledge factors signify are rational, we are able to very simply inform when a knowledge level ought to manipulate its function vector (advantages outweigh prices) and when it shouldn’t (prices outweigh advantages). The following step is to show our intuitive understanding into one thing extra formal.
Balancing Prices & Advantages: Defining Knowledge Level Finest Response
This leads us to outline the knowledge level greatest response:

So we’re searching for the function vector(s) z ∈ X that maximize… what precisely? Let’s break down the expression we’re aiming to maximise into extra manageable elements.
- h: A given binary classifier (h: X → { -1, 1 }).
- c(z; x): As acknowledged above, this expresses the value of modifying the function vector x to be z.
- (h(z) = 1): Right here, (p) is the indicator perform, returning 1 if the predicate p is upheld or 0 if it isn’t. The predicate h(z) = 1 is true if the vector z into account is positively labeled by h. Placing that collectively, we discover that (h(z) = 1) evaluates to 1 for any z that’s positively labeled. If r is optimistic, that’s good. If it’s adverse, that’s dangerous.
The underside-line is that we need to discover vector(s) z for which (h(z) = 1) ⋅ r, which we are able to name the realized reward, outweighs the price of manipulating the unique x into z by as a lot as attainable. To place it in recreation theoretic phrases, the info level greatest response maximizes the utility of its corresponding agent within the context of the binary classification into account.
Placing It All Collectively: A Formal Definition of the Strategic Classification Downside
Lastly, we’ve laid all the required groundwork to formally outline the strategic classification drawback.

Given a speculation class H, a desire class R, a price perform c, and a set of n knowledge factors drawn from a distribution D, we need to discover a binary classifier h’ that minimizes the loss as outlined within the diagram above. Be aware that the loss is just a modification of the canonical zero-one loss, plugging within the knowledge level greatest response as a substitute of h(x).
Conclusion
Ranging from the canonical binary classification setup, we launched the notion of desire lessons. Subsequent, we noticed how one can formalize that notion utilizing an r worth for every knowledge level. We then noticed how value capabilities complement knowledge level preferences. After that, we broke down an instance earlier than defining the important thing idea of knowledge level greatest response primarily based on the concepts we explored beforehand. Lastly, we used the info level greatest response to outline the modified zero-one loss used within the definition of the strategic classification drawback.
Be part of me subsequent time as I outline and clarify the strategic VC dimension, which is the pure subsequent step from the place we left off this time.
References
[1] R. Sundaram, A. Vullikanti, H. Xu, F. Yao. PAC-Learning for Strategic Classification (2021), Worldwide Convention on Machine Studying.




