LLM2LLM: UC Berkeley, ICSI and LBNL Researchers’ Progressive Strategy to Boosting Massive Language Mannequin Efficiency in Low-Information Regimes with Artificial Information
Massive language fashions (LLMs) are on the forefront of technological developments in pure language processing, marking a major leap within the potential of machines to grasp, interpret, and generate human-like textual content. Nonetheless, the complete potential of LLMs usually stays untapped as a result of limitations imposed by the shortage of specialised, task-specific coaching knowledge. This bottleneck restricts the applicability of LLMs throughout varied domains, notably these which are data-constrained.
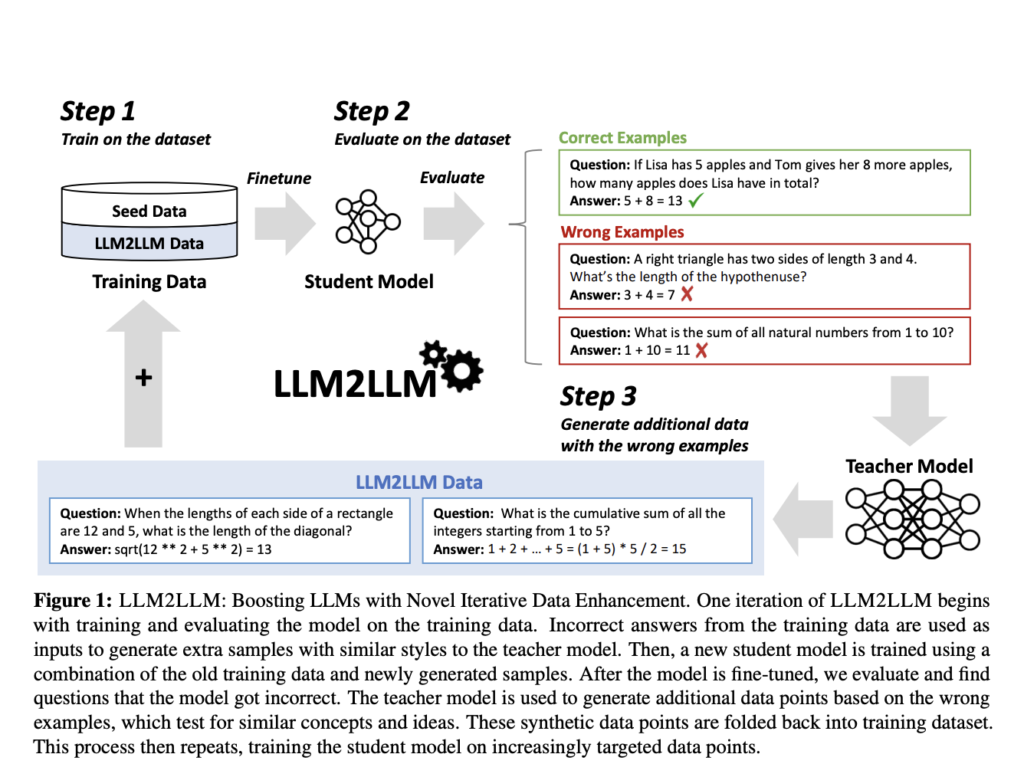
LLM2LLM is proposed by a analysis workforce at UC Berkeley, ICSI, and LBNL as a groundbreaking technique to amplify the capabilities of LLMs within the low-data regime. This strategy diverges from conventional knowledge augmentation methods, which usually contain easy manipulations corresponding to synonym substitute or textual content rephrasing. Whereas these strategies might increase the dataset, they seldom improve the mannequin’s understanding of advanced, specialised duties. As an alternative, LLM2LLM makes use of a extra subtle, iterative course of that instantly targets the weaknesses of a mannequin, making a suggestions loop that progressively refines its efficiency.
The LLM2LLM methodology is an interactive dynamic between two LLMs: a trainer mannequin and a scholar mannequin. Initially, the coed mannequin is fine-tuned on a restricted dataset. It’s then evaluated to determine cases the place it fails to foretell precisely. These cases are essential as they spotlight the mannequin’s particular areas of weak point. The trainer mannequin steps in at this juncture, producing new, artificial knowledge factors that mimic these difficult cases. This newly created knowledge is then used to retrain the coed mannequin, successfully focusing the coaching course of on overcoming its beforehand recognized shortcomings.
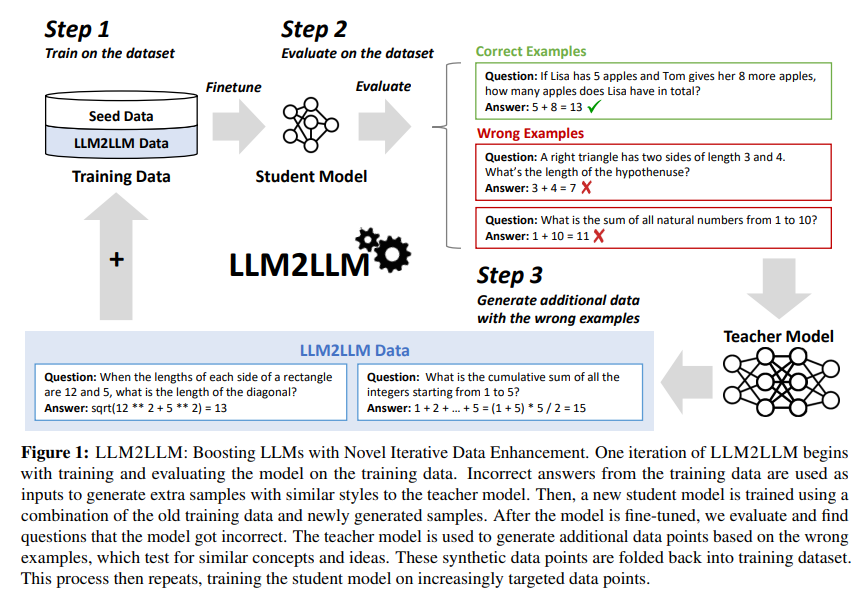
What units LLM2LLM aside is its focused, iterative strategy to knowledge augmentation. As an alternative of indiscriminately enlarging the dataset, it well generates new knowledge designed to enhance the mannequin’s efficiency on duties it beforehand struggled with. In testing with the GSM8K dataset, the LLM2LLM technique achieved as much as 24.2% enchancment in mannequin efficiency. Equally, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0% enhance was noticed.

In conclusion, the LLM2LLM framework affords a sturdy answer to the crucial problem of knowledge shortage. By harnessing the facility of 1 LLM to enhance one other, it demonstrates a novel, environment friendly pathway to fine-tune fashions for particular duties with restricted preliminary knowledge. The iterative, focused nature of LLM2LLM considerably outperforms conventional knowledge augmentation and fine-tuning strategies, showcasing its potential to revolutionize how LLMs are skilled and utilized.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 39k+ ML SubReddit
Whats up, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with know-how and need to create new merchandise that make a distinction.




