Allow information sharing by federated studying: A coverage strategy for chief digital officers
This can be a visitor weblog submit written by Nitin Kumar, a Lead Knowledge Scientist at T and T Consulting Companies, Inc.
On this submit, we talk about the worth and potential affect of federated studying within the healthcare area. This strategy may also help coronary heart stroke sufferers, docs, and researchers with quicker analysis, enriched decision-making, and extra knowledgeable, inclusive analysis work on stroke-related well being points, utilizing a cloud-native strategy with AWS companies for light-weight carry and easy adoption.
Prognosis challenges with coronary heart strokes
Statistics from the Centers for Disease Control and Prevention (CDC) present that every 12 months within the US, greater than 795,000 individuals undergo from their first stroke, and about 25% of them expertise recurrent assaults. It’s the quantity 5 reason for loss of life in accordance with the American Stroke Association and a number one reason for incapacity within the US. Subsequently, it’s essential to have immediate analysis and remedy to scale back mind harm and different problems in acute stroke sufferers.
CTs and MRIs are the gold commonplace in imaging applied sciences for classifying completely different sub-types of strokes and are essential throughout preliminary evaluation of sufferers, figuring out the basis trigger, and remedy. One important problem right here, particularly within the case of acute stroke, is the time of imaging analysis, which on common ranges from 30 minutes up to an hour and may be for much longer relying on emergency division crowding.
Medical doctors and medical workers want fast and correct picture analysis to guage a affected person’s situation and suggest remedy choices. In Dr. Werner Vogels’s personal phrases at AWS re:Invent 2023, “each second that an individual has a stroke counts.” Stroke victims can lose round 1.9 billion neurons each second they don’t seem to be being handled.
Medical information restrictions
You should use machine studying (ML) to help docs and researchers in analysis duties, thereby rushing up the method. Nonetheless, the datasets wanted to construct the ML fashions and provides dependable outcomes are sitting in silos throughout completely different healthcare programs and organizations. This remoted legacy information has the potential for enormous affect if cumulated. So why hasn’t it been used but?
There are a number of challenges when working with medical area datasets and constructing ML options, together with affected person privateness, safety of non-public information, and sure bureaucratic and coverage restrictions. Moreover, analysis establishments have been tightening their information sharing practices. These obstacles additionally forestall worldwide analysis groups from working collectively on various and wealthy datasets, which may save lives and stop disabilities that may consequence from coronary heart strokes, amongst different advantages.
Insurance policies and laws like General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPPA), and California Consumer Privacy Act (CCPA) put guardrails on sharing information from the medical area, particularly affected person information. Moreover, the datasets at particular person institutes, organizations, and hospitals are sometimes too small, are unbalanced, or have biased distribution, resulting in mannequin generalization constraints.
Federated studying: An introduction
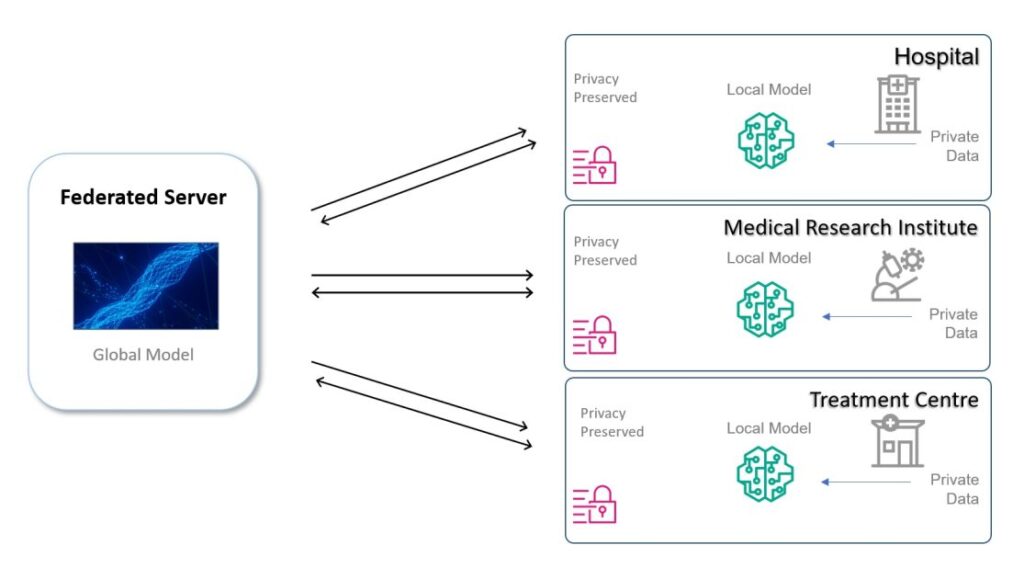
Federated studying (FL) is a decentralized type of ML—a dynamic engineering strategy. On this decentralized ML strategy, the ML mannequin is shared between organizations for coaching on proprietary information subsets, in contrast to conventional centralized ML coaching, the place the mannequin typically trains on aggregated datasets. The information stays protected behind the group’s firewalls or VPC, whereas the mannequin with its metadata is shared.
Within the coaching part, a worldwide FL mannequin is disseminated and synchronized between unit organizations for coaching on particular person datasets, and a neighborhood skilled mannequin is returned. The ultimate world mannequin is out there to make use of to make predictions for everybody among the many individuals, and can be used as a base for additional coaching to construct native customized fashions for taking part organizations. It could possibly additional be prolonged to profit different institutes. This strategy can considerably cut back the cybersecurity necessities for information in transit by eradicating the necessity for information to transit exterior of the group’s boundaries in any respect.
The next diagram illustrates an instance structure.

Within the following sections, we talk about how federated studying may also help.
Federation studying to save lots of the day (and save lives)
For good synthetic intelligence (AI), you want good information.
Legacy programs, that are steadily discovered within the federal area, pose important information processing challenges earlier than you may derive any intelligence or merge them with newer datasets. That is an impediment in offering useful intelligence to leaders. It could possibly result in inaccurate decision-making as a result of the proportion of legacy information is typically rather more useful in comparison with the newer small dataset. You need to resolve this bottleneck successfully and with out workloads of handbook consolidation and integration efforts (together with cumbersome mapping processes) for legacy and newer datasets sitting throughout hospitals and institutes, which might take many months—if not years, in lots of instances. The legacy information is sort of useful as a result of it holds necessary contextual info wanted for correct decision-making and well-informed mannequin coaching, resulting in dependable AI in the actual world. Period of knowledge informs on long-term variations and patterns within the dataset that may in any other case go undetected and result in biased and ill-informed predictions.
Breaking down these information silos to unite the untapped potential of the scattered information can save and remodel many lives. It could possibly additionally speed up the analysis associated to secondary well being points arising from coronary heart strokes. This answer may also help you share insights from information remoted between institutes as a result of coverage and different causes, whether or not you’re a hospital, a analysis institute, or different well being data-focused organizations. It could possibly allow knowledgeable choices on analysis course and analysis. Moreover, it leads to a centralized repository of intelligence through a safe, non-public, and world information base.

Federated studying has many advantages normally and particularly for medical information settings.
Safety and Privateness options:
- Retains delicate information away from the web and nonetheless makes use of it for ML, and harnesses its intelligence with differential privateness
- Allows you to construct, prepare, and deploy unbiased and sturdy fashions throughout not simply machines but in addition networks, with none information safety hazards
- Overcomes the hurdles with a number of distributors managing the information
- Eliminates the necessity for cross-site information sharing and world governance
- Preserves privateness with differential privateness and provides safe multi-party computation with native coaching
Efficiency Enhancements:
- Addresses the small pattern dimension drawback within the medical imaging house and dear labeling processes
- Balances the distribution of the information
- Allows you to incorporate most conventional ML and deep studying (DL) strategies
- Makes use of pooled picture units to assist enhance statistical energy, overcoming the pattern dimension limitation of particular person establishments
Resilience Advantages:
- If anyone get together decides to depart, it gained’t hinder the coaching
- A brand new hospital or institute can be a part of at any time; it’s not reliant on any particular dataset with any node group
- There isn’t a want for intensive information engineering pipelines for the legacy information scattered throughout widespread geographical places
These options may also help convey the partitions down between establishments internet hosting remoted datasets on related domains. The answer can grow to be a pressure multiplier by harnessing the unified powers of distributed datasets and enhancing effectivity by radically remodeling the scalability side with out the heavy infrastructure carry. This strategy helps ML attain its full potential, turning into proficient on the scientific degree and never simply analysis.
Federated studying has comparable efficiency to common ML, as proven within the following experiment by NVidia Clara (on Medical Modal ARchive (MMAR) utilizing the BRATS2018 dataset). Right here, FL achieved a comparable segmentation efficiency in comparison with coaching with centralized information: over 80% with roughly 600 epochs whereas coaching a multi-modal, multi-class mind tumor segmentation activity.
Federated studying has been examined not too long ago in a couple of medical sub-fields to be used instances together with affected person similarity studying, affected person illustration studying, phenotyping, and predictive modeling.
Utility blueprint: Federated studying makes it attainable and easy
To get began with FL, you may select from many high-quality datasets. For instance, datasets with mind photographs embrace ABIDE (Autism Mind Imaging Knowledge Alternate initiative), ADNI (Alzheimer’s Illness Neuroimaging Initiative), RSNA (Radiological Society of North America) Mind CT, BraTS (Multimodal Mind Tumor Picture Segmentation Benchmark) up to date repeatedly for the Mind Tumor Segmentation Problem beneath UPenn (College of Pennsylvania), UK BioBank (lined within the following NIH paper), and IXI. Equally for coronary heart photographs, you may select from a number of publicly out there choices, together with ACDC (Computerized Cardiac Prognosis Problem), which is a cardiac MRI evaluation dataset with full annotation talked about by the Nationwide Library of Drugs within the following paper, and M&M (Multi-Heart, Multi-Vendor, and Multi-Illness) Cardiac Segmentation Problem talked about within the following IEEE paper.
The next photographs present a probabilistic lesion overlap map for the primary lesions from the ATLAS R1.1 dataset. (Strokes are some of the widespread causes of mind lesions in accordance with Cleveland Clinic.)

For Digital Well being Data (EHR) information, a couple of datasets can be found that comply with the Fast Healthcare Interoperability Resources (FHIR) commonplace. This commonplace helps you construct easy pilots by eradicating sure challenges with heterogenous, non-normalized datasets, permitting for seamless and safe alternate, sharing, and integration of datasets. The FHIR permits most interoperability. Dataset examples embrace MIMIC-IV (Medical Data Mart for Intensive Care). Different good-quality datasets that aren’t presently FHIR however may be simply transformed embrace Centers for Medicare & Medicaid Services (CMS) Public Use Recordsdata (PUF) and eICU Collaborative Research Database from MIT (Massachusetts Institute of Expertise). There are additionally different sources turning into out there that supply FHIR-based datasets.
The lifecycle for implementing FL can embrace the next steps: activity initialization, choice, configuration, mannequin coaching, consumer/server communication, scheduling and optimization, versioning, testing, deployment, and termination. There are a lot of time-intensive steps that go into getting ready medical imaging information for conventional ML, as described within the following paper. Area information is likely to be wanted in some eventualities to preprocess uncooked affected person information, particularly as a result of its delicate and personal nature. These may be consolidated and typically eradicated for FL, saving essential time for coaching and offering quicker outcomes.
Implementation
FL instruments and libraries have grown with widespread help, making it easy to make use of FL with out a heavy overhead carry. There are lots of good sources and framework choices out there to get began. You possibly can consult with the next extensive list of the preferred frameworks and instruments within the FL area, together with PySyft, FedML, Flower, OpenFL, FATE, TensorFlow Federated, and NVFlare. It offers a newbie’s checklist of tasks to get began shortly and construct upon.
You possibly can implement a cloud-native strategy with Amazon SageMaker that seamlessly works with AWS VPC peering, holding every node’s coaching in a non-public subnet of their respective VPC and enabling communication through non-public IPv4 addresses. Moreover, mannequin internet hosting on Amazon SageMaker JumpStart may also help by exposing the endpoint API with out sharing mannequin weights.
It additionally takes away potential high-level compute challenges with on-premises {hardware} with Amazon Elastic Compute Cloud (Amazon EC2) sources. You possibly can implement the FL consumer and servers on AWS with SageMaker notebooks and Amazon Simple Storage Service (Amazon S3), preserve regulated entry to the information and mannequin with AWS Identity and Access Management (IAM) roles, and use AWS Security Token Service (AWS STS) for client-side safety. You too can construct your individual customized system for FL utilizing Amazon EC2.
For an in depth overview of implementing FL with the Flower framework on SageMaker, and a dialogue of its distinction from distributed coaching, consult with Machine learning with decentralized training data using federated learning on Amazon SageMaker.
The next figures illustrate the structure of switch studying in FL.
![]()
Addressing FL information challenges
Federated studying comes with its personal information challenges, together with privateness and safety, however they’re easy to handle. First, you’ll want to tackle the information heterogeneity drawback with medical imaging information arising from information being saved throughout completely different websites and taking part organizations, referred to as a area shift drawback (additionally known as consumer shift in an FL system), as highlighted by Guan and Liu within the following paper. This could result in a distinction in convergence of the worldwide mannequin.
Different parts for consideration embrace guaranteeing information high quality and uniformity on the supply, incorporating knowledgeable information into the educational course of to encourage confidence within the system amongst medical professionals, and reaching mannequin precision. For extra details about a few of the potential challenges chances are you’ll face throughout implementation, consult with the next paper.
AWS helps you resolve these challenges with options just like the versatile compute of Amazon EC2 and pre-built Docker images in SageMaker for easy deployment. You possibly can resolve client-side issues like unbalanced information and computation sources for every node group. You possibly can tackle server-side studying issues like poisoning assaults from malicious events with Amazon Virtual Private Cloud (Amazon VPC), security groups, and different safety requirements, stopping consumer corruption and implementing AWS anomaly detection companies.
AWS additionally helps in addressing real-world implementation challenges, which might embrace integration challenges, compatibility points with present or legacy hospital programs, and consumer adoption hurdles, by providing versatile, easy-to-use, and easy carry tech options.
With AWS companies, you may allow large-scale FL-based analysis and scientific implementation and deployment, which might consist of assorted websites the world over.
Current insurance policies on interoperability spotlight the necessity for federated studying
Many legal guidelines not too long ago handed by the federal government embrace a concentrate on information interoperability, bolstering the necessity for cross-organizational interoperability of knowledge for intelligence. This may be fulfilled by utilizing FL, together with frameworks just like the TEFCA (Trusted Alternate Framework and Widespread Settlement) and the expanded USCDI (United States Core Knowledge for Interoperability).
The proposed concept additionally contributes in direction of the CDC’s seize and distribution initiative CDC Moving Forward. The next quote from the GovCIO article Data Sharing and AI Top Federal Health Agency Priorities in 2024 additionally echoes an analogous theme: “These capabilities also can help the general public in an equitable approach, assembly sufferers the place they’re and unlocking important entry to those companies. A lot of this work comes all the way down to the information.”
This may also help medical institutes and companies across the nation (and throughout the globe) with information silos. They’ll profit from seamless and safe integration and information interoperability, making medical information usable for impactful ML-based predictions and sample recognition. You can begin with photographs, however the strategy is relevant to all EHR as nicely. The objective is to search out the very best strategy for information stakeholders, with a cloud-native pipeline to normalize and standardize the information or immediately use it for FL.
Let’s discover an instance use case. Coronary heart stroke imaging information and scans are scattered across the nation and the world, sitting in remoted silos in institutes, universities, and hospitals, and separated by bureaucratic, geographical, and political boundaries. There isn’t a single aggregated supply and no straightforward approach for medical professionals (non-programmers) to extract insights from it. On the similar time, it’s not possible to coach ML and DL fashions on this information, which may assist medical professionals make quicker, extra correct choices in important instances when coronary heart scans can take hours to return in whereas the affected person’s life might be hanging within the stability.
Different recognized use instances embrace POTS (Buying On-line Monitoring System) at NIH (Nationwide Institutes of Well being) and cybersecurity for scattered and tiered intelligence answer wants at COMCOMs/MAJCOMs places across the globe.
Conclusion
Federated studying holds nice promise for legacy healthcare information analytics and intelligence. It’s easy to implement a cloud-native answer with AWS companies, and FL is particularly useful for medical organizations with legacy information and technical challenges. FL can have a possible affect on your entire remedy cycle, and now much more so with the concentrate on information interoperability from giant federal organizations and authorities leaders.
This answer may also help you keep away from reinventing the wheel and use the most recent know-how to take a leap from legacy programs and be on the forefront on this ever-evolving world of AI. You too can grow to be a pacesetter for greatest practices and an environment friendly strategy to information interoperability inside and throughout companies and institutes within the well being area and past. In case you are an institute or company with information silos scattered across the nation, you may profit from this seamless and safe integration.
The content material and opinions on this submit are these of the third-party writer and AWS shouldn’t be answerable for the content material or accuracy of this submit. It’s every clients’ duty to find out whether or not they’re topic to HIPAA, and in that case, how greatest to adjust to HIPAA and its implementing laws. Earlier than utilizing AWS in reference to protected well being info, clients should enter an AWS Enterprise Affiliate Addendum (BAA) and comply with its configuration necessities.
In regards to the Creator

Nitin Kumar (MS, CMU) is a Lead Knowledge Scientist at T and T Consulting Companies, Inc. He has intensive expertise with R&D prototyping, well being informatics, public sector information, and information interoperability. He applies his information of cutting-edge analysis strategies to the federal sector to ship revolutionary technical papers, POCs, and MVPs. He has labored with a number of federal companies to advance their information and AI targets. Nitin’s different focus areas embrace pure language processing (NLP), information pipelines, and generative AI.