Construct a contextual chatbot utility utilizing Data Bases for Amazon Bedrock
Trendy chatbots can function digital brokers, offering a brand new avenue for delivering 24/7 customer support and assist throughout many industries. Their reputation stems from the power to reply to buyer inquiries in actual time and deal with a number of queries concurrently in numerous languages. Chatbots additionally provide beneficial data-driven insights into buyer habits whereas scaling effortlessly because the person base grows; due to this fact, they current an economical answer for participating clients. Chatbots use the superior pure language capabilities of enormous language fashions (LLMs) to reply to buyer questions. They will perceive conversational language and reply naturally. Nonetheless, chatbots that merely reply primary questions have restricted utility. To turn out to be trusted advisors, chatbots want to offer considerate, tailor-made responses.
One option to allow extra contextual conversations is by linking the chatbot to inner data bases and data methods. Integrating proprietary enterprise knowledge from inner data bases allows chatbots to contextualize their responses to every person’s particular person wants and pursuits. For instance, a chatbot may counsel merchandise that match a client’s preferences and previous purchases, clarify particulars in language tailored to the person’s stage of experience, or present account assist by accessing the client’s particular information. The flexibility to intelligently incorporate data, perceive pure language, and supply personalized replies in a conversational circulate permits chatbots to ship actual enterprise worth throughout various use circumstances.
The favored structure sample of Retrieval Augmented Generation (RAG) is commonly used to reinforce person question context and responses. RAG combines the capabilities of LLMs with the grounding in info and real-world data that comes from retrieving related texts and passages from corpus of knowledge. These retrieved texts are then used to tell and floor the output, decreasing hallucination and bettering relevance.
On this publish, we illustrate contextually enhancing a chatbot by utilizing Knowledge Bases for Amazon Bedrock, a totally managed serverless service. The Data Bases for Amazon Bedrock integration permits our chatbot to offer extra related, personalised responses by linking person queries to associated data knowledge factors. Internally, Amazon Bedrock makes use of embeddings saved in a vector database to reinforce person question context at runtime and allow a managed RAG structure answer. We use the Amazon letters to shareholders dataset to develop this answer.
Retrieval Augmented Era
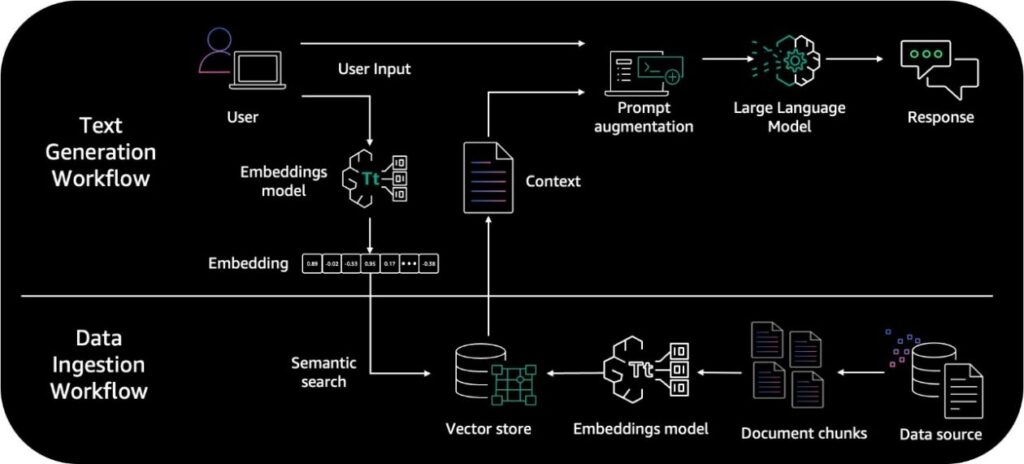
RAG is an strategy to pure language era that includes data retrieval into the era course of. RAG structure entails two key workflows: knowledge preprocessing via ingestion, and textual content era utilizing enhanced context.
The info ingestion workflow makes use of LLMs to create embedding vectors that signify semantic which means of texts. Embeddings are created for paperwork and person questions. The doc embeddings are break up into chunks and saved as indexes in a vector database. The textual content era workflow then takes a query’s embedding vector and makes use of it to retrieve essentially the most related doc chunks primarily based on vector similarity. It augments prompts with these related chunks to generate a solution utilizing the LLM. For extra particulars, consult with the Primer on Retrieval Augmented Era, Embeddings, and Vector Databases part in Preview – Connect Foundation Models to Your Company Data Sources with Agents for Amazon Bedrock.
The next diagram illustrates the high-level RAG structure.

Though the RAG structure has many benefits, it entails a number of parts, together with a database, retrieval mechanism, immediate, and generative mannequin. Managing these interdependent elements can introduce complexities in system improvement and deployment. The mixing of retrieval and era additionally requires further engineering effort and computational assets. Some open supply libraries present wrappers to scale back this overhead; nonetheless, adjustments to libraries can introduce errors and add further overhead of versioning. Even with open supply libraries, vital effort is required to put in writing code, decide optimum chunk measurement, generate embeddings, and extra. This setup work alone can take weeks relying on knowledge quantity.
Subsequently, a managed answer that handles these undifferentiated duties may streamline and speed up the method of implementing and managing RAG purposes.
Data Bases for Amazon Bedrock
Data Bases for Amazon Bedrock is a serverless choice to construct highly effective conversational AI methods utilizing RAG. It gives totally managed knowledge ingestion and textual content era workflows.
For knowledge ingestion, it handles creating, storing, managing, and updating textual content embeddings of doc knowledge within the vector database routinely. It splits the paperwork into manageable chunks for environment friendly retrieval. The chunks are then transformed to embeddings and written to a vector index, whereas permitting you to see the supply paperwork when answering a query.
For textual content era, Amazon Bedrock supplies the RetrieveAndGenerate API to create embeddings of person queries, and retrieves related chunks from the vector database to generate correct responses. It additionally helps supply attribution and short-term reminiscence wanted for RAG purposes.
This lets you focus in your core enterprise purposes and removes the undifferentiated heavy lifting.
Resolution overview
The answer offered on this publish makes use of a chatbot created utilizing a Streamlit utility and consists of the next AWS providers:
The next diagram is a typical answer structure sample you should use to combine any chatbot utility to Data Bases for Amazon Bedrock.

This structure consists of the next steps:
- A person interacts with the Streamlit chatbot interface and submits a question in pure language
- This triggers a Lambda perform, which invokes the Data Bases
RetrieveAndGenerateAPI. Internally, Data Bases makes use of an Amazon Titan embedding mannequin and converts the person question to a vector and finds chunks which might be semantically much like the person question. The person immediate is than augmented with the chunks which might be retrieved from the data base. The immediate alongside the extra context is then despatched to a LLM for response era. On this answer, we use Anthropic Claude Instant as our LLM to generate person responses utilizing further context. Observe that this answer is supported in Areas the place Anthropic Claude on Amazon Bedrock is available. - A contextually related response is shipped again to the chatbot utility and person.
Conditions
Amazon Bedrock customers must request entry to basis fashions earlier than they’re obtainable to be used. It is a one-time motion and takes lower than a minute. For this answer, you’ll must allow entry to the Titan Embeddings G1 – Textual content and Claude Prompt – v1.2 mannequin in Amazon Bedrock. For extra data, consult with Model access.
Clone the GitHub repo
The answer offered on this publish is out there within the following GitHub repo. That you must clone the GitHub repository to your native machine. Open a terminal window and run the next command. Observe that is one single git clone command.
Add your data dataset to Amazon S3
We obtain the dataset for our data base and add it right into a S3 bucket. This dataset will feed and energy data base. Full the next steps:
- Navigate to the Annual reports, proxies and shareholder letters knowledge repository and obtain the previous couple of years of Amazon shareholder letters.

- On the Amazon S3 console, select Buckets within the navigation pane.
- Select Create bucket.
- Identify the bucket
knowledgebase-<your-awsaccount-number>. - Depart all different bucket settings as default and select Create.
- Navigate to the
knowledgebase-<your-awsaccount-number>bucket. - Select Create folder and title it dataset.
- Depart all different folder settings as default and select Create.
- Navigate again to the bucket residence and select Create folder to create a brand new folder and title it
lambdalayer. - Depart all different settings as default and select Create.

- Navigate to the
datasetfolder. - Add the annual reviews, proxies and shareholder letters dataset recordsdata you downloaded earlier to this bucket and select Add.
- Navigate to the
lambdalayerfolder. - Add the
knowledgebase-lambdalayer.zipfile obtainable below the/lambda/layerfolder within the GitHub repo you cloned earlier and select Add. You’ll use this Lambda layer code later to create the Lambda perform.

Create a data base
On this step, we create a data base utilizing the Amazon shareholder letters dataset we uploaded to our S3 bucket within the earlier step.
- On the Amazon Bedrock console, below Orchestration within the navigation pane, select Data base.

- Select Create data base.

- Within the Data base particulars part, enter a reputation and non-compulsory description.
- Within the IAM permissions part, choose Create and use a brand new service position and enter a reputation for the position.
- Add tags as wanted.
- Select Subsequent.

- Depart Information supply title because the default title.
- For S3 URI, select Browse S3 to decide on the S3 bucket
knowledgebase-<your-account-number>/dataset/.That you must level to the bucket and dataset folder you created within the earlier steps. - Within the Superior settings part, depart the default values (if you need, you may change the default chunking technique and specify the chunk measurement and overlay in proportion).
- Select Subsequent.

- For Embeddings mannequin, choose Titan Embedding G1 – Textual content.
- For Vector database, you may both choose Fast create a brand new vector retailer or Select a vector retailer you have got created. Observe that, to make use of the vector retailer of your alternative, you want have a vector retailer preconfigured to make use of. We at present assist 4 vector engine sorts: the vector engine for Amazon OpenSearch Serverless, Amazon Aurora, Pinecone, and Redis Enterprise Cloud. For this publish, we choose Fast create a brand new vector retailer, which by default creates a brand new OpenSearch Serverless vector retailer in your account.
- Select Subsequent.

- On the Overview and create web page, overview all the data, or select Earlier to change any choices.
- Select Create data base.
 Observe the data base creation course of begins and the standing is In progress. It would take a couple of minutes to create the vector retailer and data base. Don’t navigate away from the web page, in any other case creation will fail.
Observe the data base creation course of begins and the standing is In progress. It would take a couple of minutes to create the vector retailer and data base. Don’t navigate away from the web page, in any other case creation will fail. - When the data base standing is within the
Preparedstate, notice down the data base ID. You’ll use it within the subsequent steps to configure the Lambda perform.
- Now that data base is prepared, we have to sync our Amazon shareholders letter knowledge to it. Within the Information Supply part of the data base particulars web page, select Sync to set off the information ingestion course of from the S3 bucket to the data base.

This sync course of splits the doc recordsdata into smaller chunks of the chunk measurement specified earlier, generates vector embeddings utilizing the chosen textual content embedding mannequin, and shops them within the vector retailer managed by Data Bases for Amazon Bedrock.

When the dataset sync is full, the standing of the information supply will change to the Prepared state. Observe that, should you add any further paperwork within the S3 knowledge folder, it’s essential re-sync the data base.

Congratulations, your data base is prepared.
Observe you could additionally use Data Bases for Amazon Bedrock service APIs and the AWS Command Line Interface (AWS CLI) to programmatically create a data base. You will have to run varied sections of the Jupyter pocket book offered below the /pocket book folder within the GitHub repo.
Create a Lambda perform
This Lambda perform is deployed utilizing an AWS CloudFormation template obtainable within the GitHub repo below the /cfn folder. The template requires two parameters: the S3 bucket title and the data base ID.
- On the AWS CloudFormation service residence web page, select Create stack to create a brand new stack.

- Choose Template is prepared for Put together template.
- Choose Add the template file for Template supply.
- Select Select file, navigate to the GitHub repo you cloned earlier, and select the .yaml file below the
/cfnfolder. - Select Subsequent.

- For Stack title, enter a reputation.
- Within the Parameters part, enter the data base ID and S3 bucket title you famous down earlier.
- Select Subsequent.

- Depart all default choices as is, select Subsequent, and select Submit.
- Confirm that the CloudFormation template ran efficiently, and there are not any errors.
Congratulations, you have got created a Lambda perform, associated roles, and insurance policies efficiently.
Take a look at the contextual chatbot utility
To check your chatbot utility, full the next steps:
- Open a brand new terminal or a command line window in your machine.
- Run the next command to put in the AWS SDK for Python (Boto3). Boto3 makes it simple to combine a Python utility, library, or script with AWS providers.
- Run the next command to put in and arrange an area Python improvement surroundings to run the Streamlit utility:
- Navigate to the
/streamlitfolder within the GitHub repository folder you cloned earlier. - Run the next command to instantiate the chatbot utility:
This could open a web-based chat utility powered by Streamlit in your default internet browser.
- Use this Streamlit chatbot utility to publish pure language questions to start out the conversations powered by Data Bases for Amazon Bedrock.

While you submit a immediate, the Streamlit app triggers the Lambda perform, which invokes the Data Bases RetrieveAndGenerate API to look and generate responses.
The next desk consists of some pattern questions and associated data base responses. Check out a few of these questions by utilizing prompts.
| Questions | Solutions |
| What’s Amazon doing within the discipline of generative AI? | Amazon has been engaged on their very own massive language fashions (LLMs) for generative AI and believes it’ll remodel and enhance each buyer expertise. They plan to proceed investing considerably in these fashions throughout all their client, vendor, model, and creator experiences. |
| What’s AWS year-over-year income in 2022? | AWS income grew 29% year-over-year in 2022 on a $62 billion income base. |
| What number of days has Amazon requested staff to come back to work in workplace? | Amazon has requested company staff to come back again to workplace not less than three days every week starting Could 2022. |
| By what proportion did AWS income develop year-over-year in 2022? | AWS had a 29% year-over-year (‘YoY’) income in 2022. |
| In comparison with Graviton2 processors, what efficiency enchancment did Graviton3 chips ship in keeping with the passage? | In 2022, AWS delivered their Graviton3 chips, offering 25% higher efficiency than the Graviton2 processors. |
| Which was the primary inference chip launched by AWS in keeping with the passage? | AWS launched their first inference chips (“Inferentia”) in 2019, they usually have saved corporations like Amazon over 100 million {dollars} in capital expense. |
| In accordance with the context, in what 12 months did Amazon’s annual income enhance from $245B to $434B? | Amazon’s annual income elevated from $245B in 2019 to $434B in 2022. |
| Inform me once more what was the income in 2019? | Amazon’s income in 2019 was $245 billion. |
| and, 2021? | Amazon’s income in 2021 was $469.8 billion, a rise of twenty-two% over 2020. |
| And, remind me once more when was the primary inference chip was launched? | Amazon’s first inference chip was Inferentia, which launched in 2019. |
Through the first name to the Lambda perform, the RetrieveAndGenerate API returns a sessionId, which is then handed by the Streamlit app together with the following person immediate as an enter to the RetrieveAndGenerate API to proceed the dialog in the identical session. The RetrieveAndGenerate API manages the short-term reminiscence and makes use of the chat historical past so long as the identical sessionId is handed as an enter within the successive calls.
Congratulations, you have got efficiently created and examined a chatbot utility utilizing Data Bases for Amazon Bedrock.
Clear up
Failing to delete assets such because the S3 bucket, OpenSearch Serverless assortment, and data base will incur fees. To scrub up these assets, delete the CloudFormation stack, delete the S3 bucket (together with any doc folders and recordsdata saved in that bucket), delete the OpenSearch Serverless assortment, delete the data base, and delete any roles, insurance policies, and permissions that you just created earlier.
Conclusion
On this publish, we offered an outline of contextual chatbots and defined why they’re vital. We described the complexities concerned in knowledge ingestion and textual content era workflows for a RAG structure. We then launched how Data Bases for Amazon Bedrock creates a totally managed serverless RAG system, together with a vector retailer. Lastly, we offered an answer structure and pattern code in a GitHub repo to retrieve and generate contextual responses for a chatbot utility utilizing a data base.
By explaining the worth of contextual chatbots, the challenges of RAG methods, and the way Data Bases for Amazon Bedrock addresses these challenges, this publish aimed to showcase how Amazon Bedrock lets you construct subtle conversational AI purposes with minimal effort.
For extra data, see the Amazon Bedrock Developer Guide and Knowledge Base APIs.
Concerning the Authors
 Manish Chugh is a Principal Options Architect at AWS primarily based in San Francisco, CA. He makes a speciality of machine studying and generative AI. He works with organizations starting from massive enterprises to early-stage startups on issues associated to machine studying. His position entails serving to these organizations architect scalable, safe, and cost-effective workloads on AWS. He repeatedly presents at AWS conferences and different companion occasions. Outdoors of labor, he enjoys climbing on East Bay trails, street biking, and watching (and enjoying) cricket.
Manish Chugh is a Principal Options Architect at AWS primarily based in San Francisco, CA. He makes a speciality of machine studying and generative AI. He works with organizations starting from massive enterprises to early-stage startups on issues associated to machine studying. His position entails serving to these organizations architect scalable, safe, and cost-effective workloads on AWS. He repeatedly presents at AWS conferences and different companion occasions. Outdoors of labor, he enjoys climbing on East Bay trails, street biking, and watching (and enjoying) cricket.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the guide Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Training Basis Board. She leads machine studying initiatives in varied domains similar to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Ladies in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
Mani Khanuja is a Tech Lead – Generative AI Specialists, creator of the guide Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Training Basis Board. She leads machine studying initiatives in varied domains similar to laptop imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Ladies in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
 Pallavi Nargund is a Principal Options Architect at AWS. In her position as a cloud know-how enabler, she works with clients to know their objectives and challenges, and provides prescriptive steering to realize their goal with AWS choices. She is keen about girls in know-how and is a core member of Ladies in AI/ML at Amazon. She speaks at inner and exterior conferences similar to AWS re:Invent, AWS Summits, and webinars. Outdoors of labor she enjoys volunteering, gardening, biking and climbing.
Pallavi Nargund is a Principal Options Architect at AWS. In her position as a cloud know-how enabler, she works with clients to know their objectives and challenges, and provides prescriptive steering to realize their goal with AWS choices. She is keen about girls in know-how and is a core member of Ladies in AI/ML at Amazon. She speaks at inner and exterior conferences similar to AWS re:Invent, AWS Summits, and webinars. Outdoors of labor she enjoys volunteering, gardening, biking and climbing.




