Automate the insurance coverage declare lifecycle utilizing Brokers and Information Bases for Amazon Bedrock
Generative AI brokers are a flexible and highly effective instrument for big enterprises. They will improve operational effectivity, customer support, and decision-making whereas decreasing prices and enabling innovation. These brokers excel at automating a variety of routine and repetitive duties, comparable to information entry, buyer assist inquiries, and content material technology. Furthermore, they will orchestrate complicated, multi-step workflows by breaking down duties into smaller, manageable steps, coordinating varied actions, and making certain the environment friendly execution of processes inside a company. This considerably reduces the burden on human assets and permits workers to give attention to extra strategic and inventive duties.
As AI expertise continues to evolve, the capabilities of generative AI brokers are anticipated to increase, providing much more alternatives for purchasers to achieve a aggressive edge. On the forefront of this evolution sits Amazon Bedrock, a completely managed service that makes high-performing basis fashions (FMs) from Amazon and different main AI corporations obtainable by an API. With Amazon Bedrock, you may construct and scale generative AI purposes with safety, privateness, and accountable AI. Now you can use Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock to configure specialised brokers that seamlessly run actions based mostly on pure language enter and your group’s information. These managed brokers play conductor, orchestrating interactions between FMs, API integrations, consumer conversations, and information sources loaded together with your information.
This publish highlights how you need to use Brokers and Information Bases for Amazon Bedrock to construct on present enterprise assets to automate the duties related to the insurance coverage declare lifecycle, effectively scale and enhance customer support, and improve determination assist by improved information administration. Your Amazon Bedrock-powered insurance coverage agent can help human brokers by creating new claims, sending pending doc reminders for open claims, gathering claims proof, and trying to find info throughout present claims and buyer information repositories.
Answer overview
The target of this resolution is to behave as a basis for purchasers, empowering you to create your individual specialised brokers for varied wants comparable to digital assistants and automation duties. The code and assets required for deployment can be found within the amazon-bedrock-examples repository.
The next demo recording highlights Brokers and Information Bases for Amazon Bedrock performance and technical implementation particulars.
Brokers and Information Bases for Amazon Bedrock work collectively to offer the next capabilities:
- Job orchestration – Brokers use FMs to know pure language inquiries and dissect multi-step duties into smaller, executable steps.
- Interactive information assortment – Brokers interact in pure conversations to collect supplementary info from customers.
- Job success – Brokers full buyer requests by collection of reasoning steps and corresponding actions based mostly on ReAct prompting.
- System integration – Brokers make API calls to built-in firm methods to run particular actions.
- Knowledge querying – Information bases improve accuracy and efficiency by absolutely managed Retrieval Augmented Generation (RAG) utilizing customer-specific information sources.
- Supply attribution – Brokers conduct supply attribution, figuring out and tracing the origin of knowledge or actions by chain-of-thought reasoning.
The next diagram illustrates the answer structure.

The workflow consists of the next steps:
- Customers present pure language inputs to the agent. The next are some instance prompts:
- Create a brand new declare.
- Ship a pending paperwork reminder to the coverage holder of declare 2s34w-8x.
- Collect proof for declare 5t16u-7v.
- What’s the whole declare quantity for declare 3b45c-9d?
- What’s the restore estimate whole for that very same declare?
- What elements decide my automobile insurance coverage premium?
- How can I decrease my automobile insurance coverage charges?
- Which claims have open standing?
- Ship reminders to all coverage holders with open claims.
- Throughout preprocessing, the agent validates, contextualizes, and categorizes consumer enter. The consumer enter (or process) is interpreted by the agent utilizing chat historical past and the directions and underlying FM that have been specified throughout agent creation. The agent’s directions are descriptive pointers outlining the agent’s supposed actions. Additionally, you may optionally configure advanced prompts, which let you increase your agent’s precision by using extra detailed configurations and providing manually chosen examples for few-shot prompting. This technique lets you improve the mannequin’s efficiency by offering labeled examples related to a specific process.
- Action groups are a set of APIs and corresponding enterprise logic, whose OpenAPI schema is outlined as JSON recordsdata saved in Amazon Simple Storage Service (Amazon S3). The schema permits the agent to cause across the perform of every API. Every motion group can specify a number of API paths, whose enterprise logic is run by the AWS Lambda perform related to the motion group.
- Information Bases for Amazon Bedrock gives absolutely managed RAG to produce the agent with entry to your information. You first configure the information base by specifying an outline that instructs the agent when to make use of your information base. You then level the information base to your Amazon S3 information supply. Lastly, you specify an embedding mannequin and select to make use of your present vector retailer or enable Amazon Bedrock to create the vector retailer in your behalf. After it’s configured, every data source sync creates vector embeddings of your information that the agent can use to return info to the consumer or increase subsequent FM prompts.
- Throughout orchestration, the agent develops a rationale with the logical steps of which motion group API invocations and information base queries are wanted to generate an remark that can be utilized to reinforce the bottom immediate for the underlying FM. This ReAct model prompting serves because the enter for activating the FM, which then anticipates probably the most optimum sequence of actions to finish the consumer’s process.
- Throughout postprocessing, in spite of everything orchestration iterations are full, the agent curates a remaining response. Postprocessing is disabled by default.
Within the following sections, we talk about the important thing steps to deploy the answer, together with pre-implementation steps and testing and validation.
Create resolution assets with AWS CloudFormation
Previous to creating your agent and information base, it’s important to determine a simulated surroundings that intently mirrors the present assets utilized by clients. Brokers and Information Bases for Amazon Bedrock are designed to construct upon these assets, utilizing Lambda-delivered enterprise logic and buyer information repositories saved in Amazon S3. This foundational alignment gives a seamless integration of your agent and information base options together with your established infrastructure.
To emulate the present buyer assets utilized by the agent, this resolution makes use of the create-customer-resources.sh shell script to automate provisioning of the parameterized AWS CloudFormation template, bedrock-customer-resources.yml, to deploy the next assets:
- An Amazon DynamoDB desk populated with artificial claims data.
- Three Lambda features that signify the client enterprise logic for creating claims, sending pending doc reminders for open standing claims, and gathering proof on new and present claims.
- An S3 bucket containing API documentation in OpenAPI schema format for the previous Lambda features and the restore estimates, declare quantities, firm FAQs, and required declare doc descriptions for use as our knowledge base data source assets.
- An Amazon Simple Notification Service (Amazon SNS) matter to which coverage holders’ emails are subscribed for e-mail alerting of declare standing and pending actions.
- AWS Identity and Access Management (IAM) permissions for the previous assets.
AWS CloudFormation prepopulates the stack parameters with the default values offered within the template. To offer different enter values, you may specify parameters as surroundings variables which are referenced within the ParameterKey=<ParameterKey>,ParameterValue=<Worth> pairs within the following shell script’s aws cloudformation create-stack command.
Full the next steps to provision your assets:
- Create an area copy of the
amazon-bedrock-samplesrepository utilizinggit clone: - Earlier than you run the shell script, navigate to the listing the place you cloned the
amazon-bedrock-samplesrepository and modify the shell script permissions to executable: - Set your CloudFormation stack identify, SNS e-mail, and proof add URL surroundings variables. The SNS e-mail will likely be used for coverage holder notifications, and the proof add URL will likely be shared with coverage holders to add their claims proof. The insurance claims processing sample gives an instance front-end for the proof add URL.
- Run the
create-customer-resources.shshell script to deploy the emulated buyer assets outlined within thebedrock-insurance-agent.ymlCloudFormation template. These are the assets on which the agent and information base will likely be constructed.
The previous supply ./create-customer-resources.sh shell command runs the next AWS Command Line Interface (AWS CLI) instructions to deploy the emulated buyer assets stack:
Create a information base
Information Bases for Amazon Bedrock makes use of RAG, a method that harnesses buyer information shops to reinforce responses generated by FMs. Information bases enable brokers to entry present buyer information repositories with out in depth administrator overhead. To attach a information base to your information, you specify an S3 bucket because the data source. With information bases, purposes acquire enriched contextual info, streamlining growth by a completely managed RAG resolution. This degree of abstraction accelerates time-to-market by minimizing the hassle of incorporating your information into agent performance, and it optimizes price by negating the need for steady mannequin retraining to make use of non-public information.
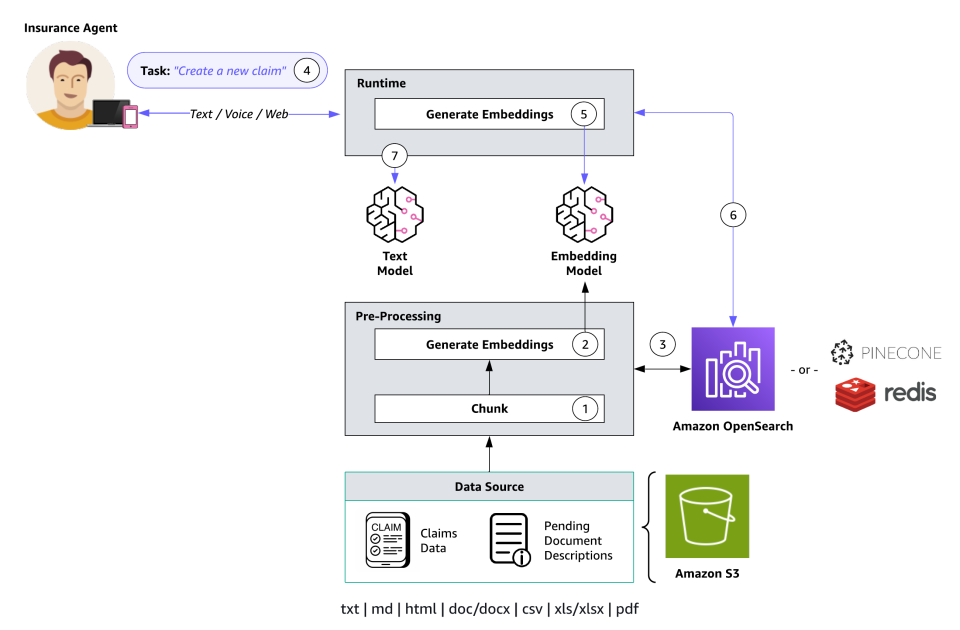
The next diagram illustrates the structure for a information base with an embeddings mannequin.

Information base performance is delineated by two key processes: preprocessing (Steps 1-3) and runtime (Steps 4-7):
- Paperwork endure segmentation (chunking) into manageable sections.
- These chunks are transformed into embeddings utilizing an Amazon Bedrock embedding mannequin.
- The embeddings are used to create a vector index, enabling semantic similarity comparisons between consumer queries and information supply textual content.
- Throughout runtime, customers present their textual content enter as a immediate.
- The enter textual content is reworked into vectors utilizing an Amazon Bedrock embedding mannequin.
- The vector index is queried for chunks associated to the consumer’s question, augmenting the consumer immediate with further context retrieved from the vector index.
- The augmented immediate, coupled with the extra context, is used to generate a response for the consumer.
To create a information base, full the next steps:
- On the Amazon Bedrock console, select Information base within the navigation pane.
- Select Create information base.
- Below Present information base particulars, enter a reputation and non-obligatory description, leaving all default settings. For this publish, we enter the outline:
Use to retrieve declare quantity and restore estimate info for declare ID, or reply common insurance coverage questions on issues like protection, premium, coverage, charge, deductible, accident, and paperwork. - Below Arrange information supply, enter a reputation.
- Select Browse S3 and choose the
knowledge-base-assetsfolder of the info supply S3 bucket you deployed earlier (<YOUR-STACK-NAME>-customer-resources/agent/knowledge-base-assets/).
- Below Choose embeddings mannequin and configure vector retailer, select Titan Embeddings G1 – Textual content and go away the opposite default settings. An Amazon OpenSearch Serverless collection will likely be created for you. This vector retailer is the place the information base preprocessing embeddings are saved and later used for semantic similarity search between queries and information supply textual content.
- Below Evaluate and create, verify your configuration settings, then select Create information base.

- After your information base is created, a inexperienced “created efficiently” banner will show with the choice to sync your information supply. Select Sync to provoke the info supply sync.

- On the Amazon Bedrock console, navigate to the information base you simply created, then notice the information base ID underneath Information base overview.

- Together with your information base nonetheless chosen, select your information base information supply listed underneath Knowledge supply, then notice the info supply ID underneath Knowledge supply overview.

The information base ID and information supply ID are used as surroundings variables in a later step while you deploy the Streamlit net UI to your agent.
Create an agent
Brokers function by a build-time run course of, comprising a number of key elements:
- Basis mannequin – Customers choose an FM that guides the agent in decoding consumer inputs, producing responses, and directing subsequent actions throughout its orchestration course of.
- Directions – Customers craft detailed directions that define the agent’s supposed performance. Optionally available superior prompts enable customization at every orchestration step, incorporating Lambda features to parse outputs.
- (Optionally available) Motion teams – Customers outline actions for the agent, utilizing an OpenAPI schema to outline APIs for process runs and Lambda features to course of API inputs and outputs.
- (Optionally available) Information bases – Customers can affiliate brokers with information bases, granting entry to further context for response technology and orchestration steps.
The agent on this pattern resolution makes use of an Anthropic Claude V2.1 FM on Amazon Bedrock, a set of directions, three motion teams, and one information base.
To create an agent, full the next steps:
- On the Amazon Bedrock console, select Brokers within the navigation pane.
- Select Create agent.
- Below Present Agent particulars, enter an agent identify and non-obligatory description, leaving all different default settings.
- Below Choose mannequin, select Anthropic Claude V2.1 and specify the next directions for the agent:
You're an insurance coverage agent that has entry to domain-specific insurance coverage information. You may create new insurance coverage claims, ship pending doc reminders to coverage holders with open claims, and collect declare proof. You too can retrieve declare quantity and restore estimate info for a selected declare ID or reply common insurance coverage questions on issues like protection, premium, coverage, charge, deductible, accident, paperwork, decision, and situation. You may reply inside questions on issues like which steps an agent ought to observe and the corporate's inside processes. You may reply to questions on a number of declare IDs inside a single dialog - Select Subsequent.
- Below Add Motion teams, add your first motion group:
- For Enter Motion group identify, enter
create-claim. - For Description, enter
Use this motion group to create an insurance coverage declare - For Choose Lambda perform, select
<YOUR-STACK-NAME>-CreateClaimFunction. - For Choose API schema, select Browse S3, select the bucket created earlier (
<YOUR-STACK-NAME>-customer-resources), then selectagent/api-schema/create_claim.json.
- For Enter Motion group identify, enter
- Create a second motion group:
- For Enter Motion group identify, enter
gather-evidence. - For Description, enter
Use this motion group to ship the consumer a URL for proof add on open standing claims with pending paperwork. Return the documentUploadUrl to the consumer - For Choose Lambda perform, select
<YOUR-STACK-NAME>-GatherEvidenceFunction. - For Choose API schema, select Browse S3, select the bucket created earlier, then select
agent/api-schema/gather_evidence.json.
- For Enter Motion group identify, enter
- Create a 3rd motion group:
- For Enter Motion group identify, enter
send-reminder. - For Description, enter
Use this motion group to verify declare standing, establish lacking or pending paperwork, and ship reminders to coverage holders - For Choose Lambda perform, select
<YOUR-STACK-NAME>-SendReminderFunction. - For Choose API schema, select Browse S3, select the bucket created earlier, then select
agent/api-schema/send_reminder.json.
- For Enter Motion group identify, enter
- Select Subsequent.
- For Choose information base, select the information base you created earlier (
claims-knowledge-base). - For Information base directions for Agent, enter the next:
Use to retrieve declare quantity and restore estimate info for declare ID, or reply common insurance coverage questions on issues like protection, premium, coverage, charge, deductible, accident, and paperwork - Select Subsequent.

- Below Evaluate and create, verify your configuration settings, then select Create agent.

After your agent is created, you will note a inexperienced “efficiently created” banner.

Testing and validation
The next testing process goals to confirm that the agent accurately identifies and understands consumer intents for creating new claims, sending pending doc reminders for open claims, gathering claims proof, and trying to find info throughout present claims and buyer information repositories. Response accuracy is decided by evaluating the relevancy, coherency, and human-like nature of the solutions generated by Brokers and Information Bases for Amazon Bedrock.
Evaluation measures and analysis approach
Person enter and agent instruction validation consists of the next:
- Preprocessing – Use pattern prompts to evaluate the agent’s interpretation, understanding, and responsiveness to numerous consumer inputs. Validate the agent’s adherence to configured directions for validating, contextualizing, and categorizing consumer enter precisely.
- Orchestration – Consider the logical steps the agent follows (for instance, “Hint”) for motion group API invocations and information base queries to reinforce the bottom immediate for the FM.
- Postprocessing – Evaluate the ultimate responses generated by the agent after orchestration iterations to make sure accuracy and relevance. Postprocessing is inactive by default and due to this fact not included in our agent’s tracing.
Motion group analysis consists of the next:
- API schema validation – Validate that the OpenAPI schema (outlined as JSON recordsdata saved in Amazon S3) successfully guides the agent’s reasoning round every API’s goal.
- Enterprise logic Implementation – Take a look at the implementation of enterprise logic related to API paths by Lambda features linked with the motion group.
Information base analysis consists of the next:
- Configuration verification – Affirm that the information base directions accurately direct the agent on when to entry the info.
- S3 information supply integration – Validate the agent’s skill to entry and use information saved within the specified S3 information supply.
The top-to-end testing consists of the next:
- Built-in workflow – Carry out complete assessments involving each motion teams and information bases to simulate real-world eventualities.
- Response high quality evaluation – Consider the general accuracy, relevancy, and coherence of the agent’s responses in numerous contexts and eventualities.
Take a look at the information base
After establishing your information base in Amazon Bedrock, you may take a look at its conduct on to assess its responses earlier than integrating it with an agent. This testing course of lets you consider the information base’s efficiency, examine responses, and troubleshoot by exploring the supply chunks from which info is retrieved. Full the next steps:
- On the Amazon Bedrock console, select Information base within the navigation pane.

- Choose the information base you need to take a look at, then select Take a look at to increase a chat window.

- Within the take a look at window, choose your basis mannequin for response technology.

- Take a look at your information base utilizing the next pattern queries and different inputs:
- What’s the prognosis on the restore estimate for declare ID 2s34w-8x?
- What’s the decision and restore estimate for that very same declare?
- What ought to the motive force do after an accident?
- What’s beneficial for the accident report and pictures?
- What’s a deductible and the way does it work?

You may toggle between producing responses and returning direct quotations within the chat window, and you’ve got the choice to clear the chat window or copy all output utilizing the offered icons.
To examine information base responses and supply chunks, you may choose the corresponding footnote or select Present outcome particulars. A supply chunks window will seem, permitting you to look, copy chunk textual content, and navigate to the S3 information supply.
Take a look at the agent
Following the profitable testing of your information base, the subsequent growth part entails the preparation and testing of your agent’s performance. Making ready the agent entails packaging the newest modifications, whereas testing gives a crucial alternative to work together with and consider the agent’s conduct. Via this course of, you may refine agent capabilities, improve its effectivity, and deal with any potential points or enhancements crucial for optimum efficiency. Full the next steps:
- On the Amazon Bedrock console, select Brokers within the navigation pane.

- Select your agent and notice the agent ID.

You employ the agent ID as an surroundings variable in a later step while you deploy the Streamlit net UI to your agent. - Navigate to your Working draft. Initially, you’ve gotten a working draft and a default
TestAliaspointing to this draft. The working draft permits for iterative growth. - Select Put together to package deal the agent with the newest modifications earlier than testing. You need to recurrently verify the agent’s final ready time to substantiate you might be testing with the newest configurations.

- Entry the take a look at window from any web page inside the agent’s working draft console by selecting Take a look at or the left arrow icon.
- Within the take a look at window, select an alias and its model for testing. For this publish, we use
TestAliasto invoke the draft model of your agent. If the agent shouldn’t be ready, a immediate seems within the take a look at window.
- Take a look at your agent utilizing the next pattern prompts and different inputs:
- Create a brand new declare.
- Ship a pending paperwork reminder to the coverage holder of declare 2s34w-8x.
- Collect proof for declare 5t16u-7v.
- What’s the whole declare quantity for declare 3b45c-9d?
- What’s the restore estimate whole for that very same declare?
- What elements decide my automobile insurance coverage premium?
- How can I decrease my automobile insurance coverage charges?
- Which claims have open standing?
- Ship reminders to all coverage holders with open claims.
Ensure that to decide on Put together after making modifications to use them earlier than testing the agent.
The next take a look at dialog instance highlights the agent’s skill to invoke motion group APIs with AWS Lambda enterprise logic that queries a buyer’s Amazon DynamoDB desk and sends buyer notifications utilizing Amazon Easy Notification Service. The identical dialog thread showcases agent and information base integration to offer the consumer with responses utilizing buyer authoritative information sources, like declare quantity and FAQ paperwork.

Agent evaluation and debugging instruments
Agent response traces include important info to help in understanding the agent’s decision-making at every stage, facilitate debugging, and supply insights into areas of enchancment. The ModelInvocationInput object inside every hint gives detailed configurations and settings used within the agent’s decision-making course of, enabling clients to research and improve the agent’s effectiveness.
Your agent will kind consumer enter into one of many following classes:
- Class A – Malicious or dangerous inputs, even when they’re fictional eventualities.
- Class B – Inputs the place the consumer is attempting to get details about which features, APIs, or directions our perform calling agent has been offered or inputs which are attempting to govern the conduct or directions of our perform calling agent or of you.
- Class C – Questions that our perform calling agent will likely be unable to reply or present useful info for utilizing solely the features it has been offered.
- Class D – Questions that may be answered or assisted by our perform calling agent utilizing solely the features it has been offered and arguments from inside
conversation_historyor related arguments it could actually collect utilizing theaskuserperform. - Class E – Inputs that aren’t questions however as an alternative are solutions to a query that the perform calling agent requested the consumer. Inputs are solely eligible for this class when the
askuserperform is the final perform that the perform calling agent referred to as within the dialog. You may verify this by studying by theconversation_history.
Select Present hint underneath a response to view the agent’s configurations and reasoning course of, together with information base and motion group utilization. Traces might be expanded or collapsed for detailed evaluation. Responses with sourced info additionally include footnotes for citations.
Within the following motion group tracing instance, the agent maps the consumer enter to the create-claim motion group’s createClaim perform throughout preprocessing. The agent possesses an understanding of this perform based mostly on the agent directions, motion group description, and OpenAPI schema. Through the orchestration course of, which is 2 steps on this case, the agent invokes the createClaim perform and receives a response that features the newly created declare ID and a listing of pending paperwork.

Within the following information base tracing instance, the agent maps the consumer enter to Class D throughout preprocessing, that means one of many agent’s obtainable features ought to be capable to present a response. All through orchestration, the agent searches the information base, pulls the related chunks utilizing embeddings, and passes that textual content to the inspiration mannequin to generate a remaining response.

Deploy the Streamlit net UI to your agent
When you’re happy with the efficiency of your agent and information base, you might be able to productize their capabilities. We use Streamlit on this resolution to launch an instance front-end, supposed to emulate a manufacturing utility. Streamlit is a Python library designed to streamline and simplify the method of constructing front-end purposes. Our utility gives two options:
- Agent immediate enter – Permits customers to invoke the agent utilizing their very own process enter.
- Information base file add – Allows the consumer to add their native recordsdata to the S3 bucket that’s getting used as the info supply for the information base. After the file is uploaded, the appliance starts an ingestion job to sync the information base information supply.
To isolate our Streamlit utility dependencies and for ease of deployment, we use the setup-streamlit-env.sh shell script to create a digital Python surroundings with the necessities put in. Full the next steps:
- Earlier than you run the shell script, navigate to the listing the place you cloned the
amazon-bedrock-samplesrepository and modify the Streamlit shell script permissions to executable:
- Run the shell script to activate the digital Python surroundings with the required dependencies:
- Set your Amazon Bedrock agent ID, agent alias ID, information base ID, information supply ID, information base bucket identify, and AWS Area surroundings variables:
- Run your Streamlit utility and start testing in your native net browser:

Clear up
To keep away from fees in your AWS account, clear up the answer’s provisioned assets
The delete-customer-resources.sh shell script empties and deletes the answer’s S3 bucket and deletes the assets that have been initially provisioned from the bedrock-customer-resources.yml CloudFormation stack. The next instructions use the default stack identify. In the event you custom-made the stack identify, alter the instructions accordingly.
The previous ./delete-customer-resources.sh shell command runs the next AWS CLI instructions to delete the emulated buyer assets stack and S3 bucket:
To delete your agent and information base, observe the directions for deleting an agent and deleting a knowledge base, respectively.
Issues
Though the demonstrated resolution showcases the capabilities of Brokers and Information Bases for Amazon Bedrock, it’s vital to know that this resolution shouldn’t be production-ready. Slightly, it serves as a conceptual information for purchasers aiming to create customized brokers for their very own particular duties and automatic workflows. Clients aiming for manufacturing deployment ought to refine and adapt this preliminary mannequin, maintaining in thoughts the next safety elements:
- Safe entry to APIs and information:
- Limit entry to APIs, databases, and different agent-integrated methods.
- Make the most of entry management, secrets and techniques administration, and encryption to stop unauthorized entry.
- Enter validation and sanitization:
- Validate and sanitize consumer inputs to stop injection assaults or makes an attempt to govern the agent’s conduct.
- Set up enter guidelines and information validation mechanisms.
- Entry controls for agent administration and testing:
- Implement correct entry controls for consoles and instruments used to edit, take a look at, or configure the agent.
- Restrict entry to approved builders and testers.
- Infrastructure safety:
- Adhere to AWS safety finest practices concerning VPCs, subnets, safety teams, logging, and monitoring for securing the underlying infrastructure.
- Agent directions validation:
- Set up a meticulous course of to overview and validate the agent’s directions to stop unintended behaviors.
- Testing and auditing:
- Completely take a look at the agent and built-in elements.
- Implement auditing, logging, and regression testing of agent conversations to detect and deal with points.
- Information base safety:
- If customers can increase the information base, validate uploads to stop poisoning assaults.
For different key concerns, seek advice from Build generative AI agents with Amazon Bedrock, Amazon DynamoDB, Amazon Kendra, Amazon Lex, and LangChain.
Conclusion
The implementation of generative AI brokers utilizing Brokers and Information Bases for Amazon Bedrock represents a big development within the operational and automation capabilities of organizations. These instruments not solely streamline the insurance coverage declare lifecycle, but additionally set a precedent for the appliance of AI in varied different enterprise domains. By automating duties, enhancing customer support, and bettering decision-making processes, these AI brokers empower organizations to give attention to progress and innovation, whereas dealing with routine and complicated duties effectively.
As we proceed to witness the fast evolution of AI, the potential of instruments like Brokers and Information Bases for Amazon Bedrock in reworking enterprise operations is immense. Enterprises that use these applied sciences stand to achieve a big aggressive benefit, marked by improved effectivity, buyer satisfaction, and decision-making. The way forward for enterprise information administration and operations is undeniably leaning in the direction of higher AI integration, and Amazon Bedrock is on the forefront of this transformation.
To be taught extra, go to Agents for Amazon Bedrock, seek the advice of the Amazon Bedrock documentation, discover the generative AI space at community.aws, and get hands-on with the Amazon Bedrock workshop.
Concerning the Writer
 Kyle T. Blocksom is a Sr. Options Architect with AWS based mostly in Southern California. Kyle’s ardour is to deliver individuals collectively and leverage expertise to ship options that clients love. Outdoors of labor, he enjoys browsing, consuming, wrestling together with his canine, and spoiling his niece and nephew.
Kyle T. Blocksom is a Sr. Options Architect with AWS based mostly in Southern California. Kyle’s ardour is to deliver individuals collectively and leverage expertise to ship options that clients love. Outdoors of labor, he enjoys browsing, consuming, wrestling together with his canine, and spoiling his niece and nephew.




