Prepare and host a pc imaginative and prescient mannequin for tampering detection on Amazon SageMaker: Half 2

Within the first part of this three-part sequence, we offered an answer that demonstrates how one can automate detecting doc tampering and fraud at scale utilizing AWS AI and machine studying (ML) companies for a mortgage underwriting use case.
On this publish, we current an method to develop a deep learning-based pc imaginative and prescient mannequin to detect and spotlight cast pictures in mortgage underwriting. We offer steerage on constructing, coaching, and deploying deep studying networks on Amazon SageMaker.
In Half 3, we show the way to implement the answer on Amazon Fraud Detector.
Answer overview
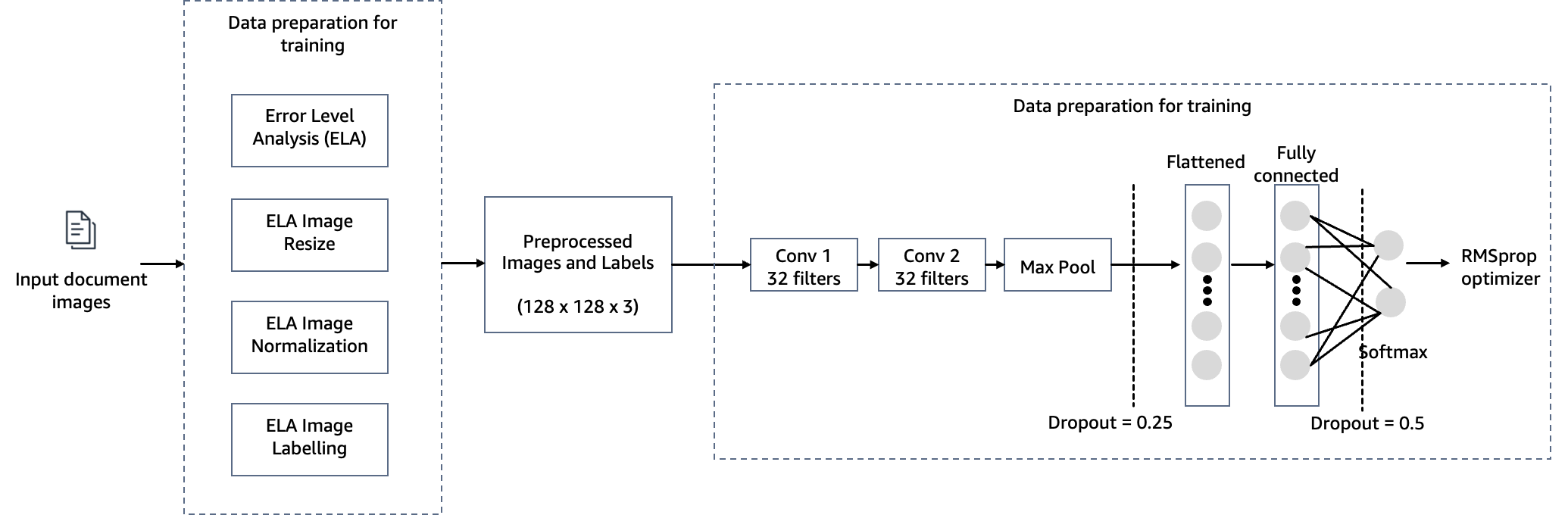
To satisfy the target of detecting doc tampering in mortgage underwriting, we make use of a pc imaginative and prescient mannequin hosted on SageMaker for our picture forgery detection resolution. This mannequin receives a testing picture as enter and generates a chance prediction of forgery as its output. The community structure is as depicted within the following diagram.
Picture forgery primarily includes 4 methods: splicing, copy-move, removing, and enhancement. Relying on the traits of the forgery, completely different clues can be utilized as the muse for detection and localization. These clues embody JPEG compression artifacts, edge inconsistencies, noise patterns, shade consistency, visible similarity, EXIF consistency, and digital camera mannequin.
Given the expansive realm of picture forgery detection, we use the Error Degree Evaluation (ELA) algorithm as an illustrative technique for detecting forgeries. We chosen the ELA method for this publish for the next causes:
- It’s faster to implement and may simply catch tampering of pictures.
- It really works by analyzing the compression ranges of various elements of a picture. This permits it to detect inconsistencies which will point out tampering—for instance, if one space was copied and pasted from one other picture that had been saved at a unique compression stage.
- It’s good at detecting extra refined or seamless tampering that could be onerous to identify with the bare eye. Even small modifications to a picture can introduce detectable compression anomalies.
- It doesn’t depend on having the unique unmodified picture for comparability. ELA can determine tampering indicators inside solely the questioned picture itself. Different methods typically require the unmodified authentic to check in opposition to.
- It’s a light-weight method that solely depends on analyzing compression artifacts within the digital picture knowledge. It doesn’t depend upon specialised {hardware} or forensics experience. This makes ELA accessible as a first-pass evaluation instrument.
- The output ELA picture can clearly spotlight variations in compression ranges, making tampered areas visibly apparent. This permits even a non-expert to acknowledge indicators of doable manipulation.
- It really works on many picture sorts (similar to JPEG, PNG, and GIF) and requires solely the picture itself to research. Different forensic methods could also be extra restricted in codecs or authentic picture necessities.
Nevertheless, in real-world eventualities the place you could have a mix of enter paperwork (JPEG, PNG, GIF, TIFF, PDF), we suggest using ELA along with numerous different strategies, similar to detecting inconsistencies in edges, noise patterns, color uniformity, EXIF data consistency, camera model identification, and font uniformity. We intention to replace the code for this publish with further forgery detection methods.
ELA’s underlying premise assumes that the enter pictures are in JPEG format, recognized for its lossy compression. Nonetheless, the strategy can nonetheless be efficient even when the enter pictures had been initially in a lossless format (similar to PNG, GIF, or BMP) and later transformed to JPEG through the tampering course of. When ELA is utilized to authentic lossless codecs, it usually signifies constant picture high quality with none deterioration, rendering it difficult to pinpoint altered areas. In JPEG pictures, the anticipated norm is for your complete image to exhibit related compression ranges. Nevertheless, if a specific part throughout the picture shows a markedly completely different error stage, it typically suggests a digital alteration has been made.
ELA highlights variations within the JPEG compression charge. Areas with uniform coloring will doubtless have a decrease ELA outcome (for instance, a darker shade in comparison with high-contrast edges). The issues to search for to determine tampering or modification embody the next:
- Comparable edges ought to have related brightness within the ELA outcome. All high-contrast edges ought to look related to one another, and all low-contrast edges ought to look related. With an authentic picture, low-contrast edges must be nearly as vivid as high-contrast edges.
- Comparable textures ought to have related coloring below ELA. Areas with extra floor element, similar to a close-up of a basketball, will doubtless have a better ELA outcome than a clean floor.
- Whatever the precise shade of the floor, all flat surfaces ought to have about the identical coloring below ELA.
JPEG pictures use a lossy compression system. Every re-encoding (resave) of the picture provides extra high quality loss to the picture. Particularly, the JPEG algorithm operates on an 8×8 pixel grid. Every 8×8 sq. is compressed independently. If the picture is totally unmodified, then all 8×8 squares ought to have related error potentials. If the picture is unmodified and resaved, then each sq. ought to degrade at roughly the identical charge.
ELA saves the picture at a specified JPEG high quality stage. This resave introduces a recognized quantity of errors throughout your complete picture. The resaved picture is then in contrast in opposition to the unique picture. If a picture is modified, then each 8×8 sq. that was touched by the modification must be at a better error potential than the remainder of the picture.
The outcomes from ELA are immediately depending on the picture high quality. You could wish to know if one thing was added, but when the image is copied a number of instances, then ELA could solely allow detecting the resaves. Attempt to discover the highest quality model of the image.
With coaching and observe, ELA can even study to determine picture scaling, high quality, cropping, and resave transformations. For instance, if a non-JPEG picture incorporates seen grid strains (1 pixel broad in 8×8 squares), then it means the image began as a JPEG and was transformed to non-JPEG format (similar to PNG). If some areas of the image lack grid strains or the grid strains shift, then it denotes a splice or drawn portion within the non-JPEG picture.
Within the following sections, we show the steps for configuring, coaching, and deploying the pc imaginative and prescient mannequin.
Stipulations
To comply with together with this publish, full the next stipulations:
- Have an AWS account.
- Arrange Amazon SageMaker Studio. You may swiftly provoke SageMaker Studio utilizing default presets, facilitating a fast launch. For extra info, consult with Amazon SageMaker simplifies the Amazon SageMaker Studio setup for individual users.
- Open SageMaker Studio and launch a system terminal.
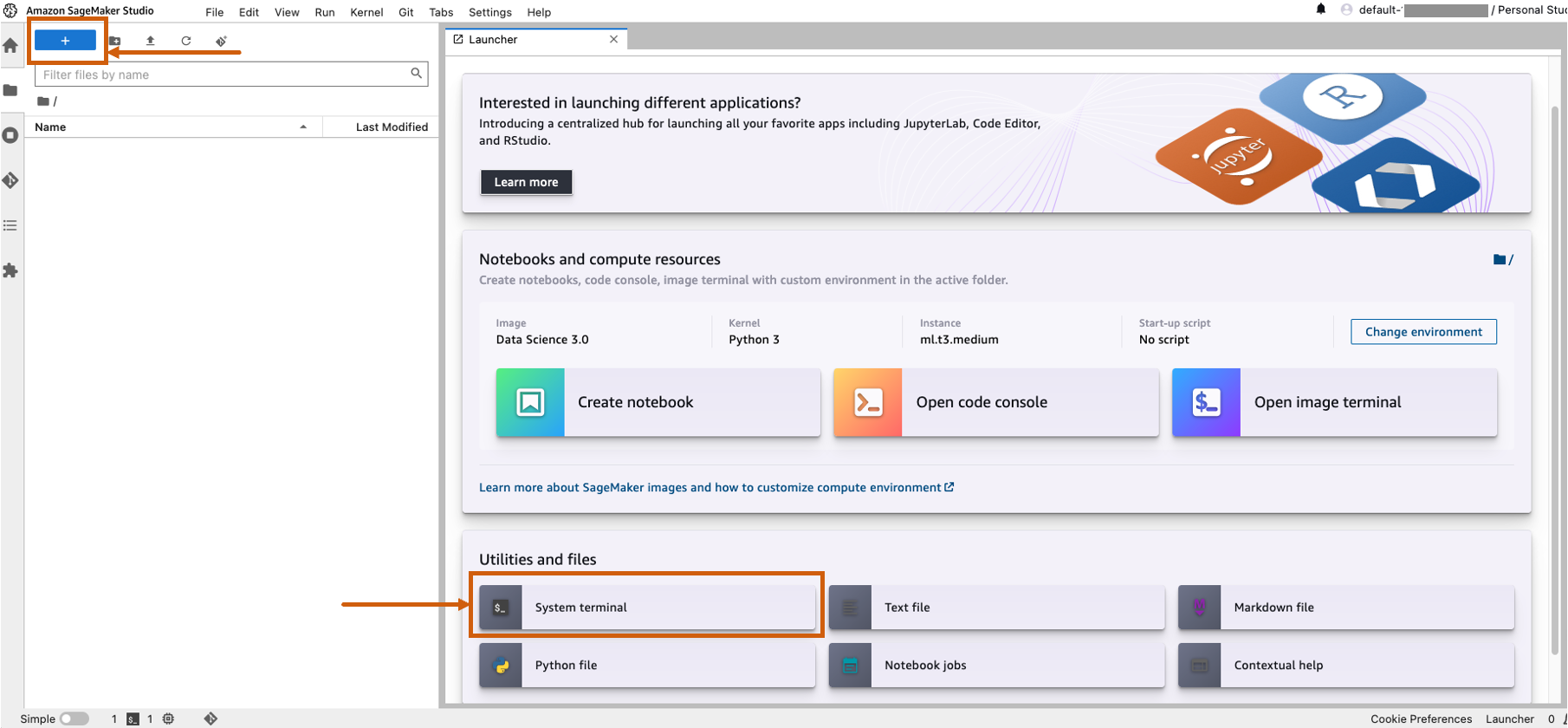
- Run the next command within the terminal:
git clone https://github.com/aws-samples/document-tampering-detection.git - The overall value of working SageMaker Studio for one consumer and the configurations of the pocket book setting is $7.314 USD per hour.
Arrange the mannequin coaching pocket book
Full the next steps to arrange your coaching pocket book:
- Open the
tampering_detection_training.ipynbfile from the document-tampering-detection listing. - Arrange the pocket book setting with the picture TensorFlow 2.6 Python 3.8 CPU or GPU Optimized.
You could run into challenge of inadequate availability or hit the quota restrict for GPU situations inside your AWS account when deciding on GPU optimized situations. To extend the quota, go to the Service Quotas console and enhance the service restrict for the precise occasion kind you want. You may also use a CPU optimized pocket book setting in such circumstances. - For Kernel, select Python3.
- For Occasion kind, select ml.m5d.24xlarge or another massive occasion.
We chosen a bigger occasion kind to scale back the coaching time of the mannequin. With an ml.m5d.24xlarge pocket book setting, the fee per hour is $7.258 USD per hour.
Run the coaching pocket book
Run every cell within the pocket book tampering_detection_training.ipynb so as. We talk about some cells in additional element within the following sections.
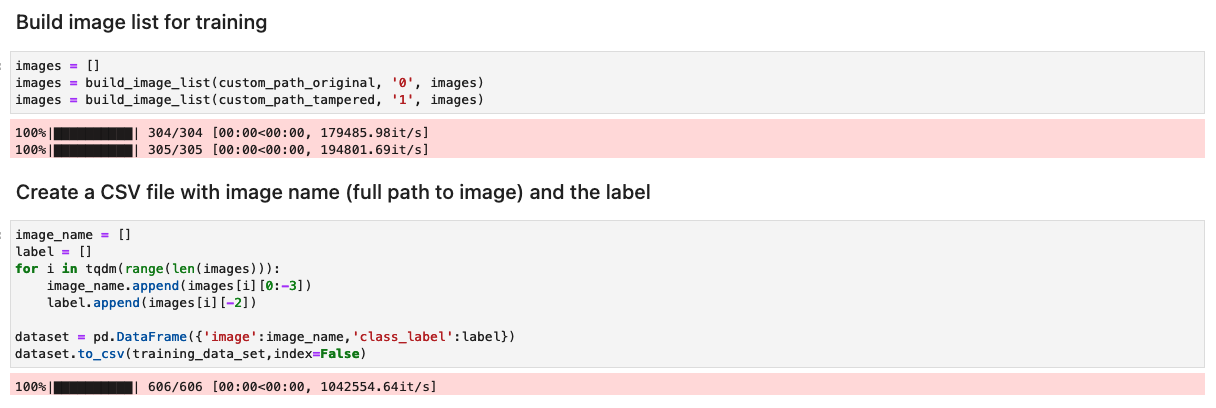
Put together the dataset with an inventory of authentic and tampered pictures
Earlier than you run the next cell within the pocket book, put together a dataset of authentic and tampered paperwork primarily based in your particular enterprise necessities. For this publish, we use a pattern dataset of tampered paystubs, and financial institution statements. The dataset is on the market throughout the pictures listing of the GitHub repository.

The pocket book reads the unique and tampered pictures from the pictures/coaching listing.
The dataset for coaching is created utilizing a CSV file with two columns: the trail to the picture file and the label for the picture (0 for authentic picture and 1 for tampered picture).
Course of the dataset by producing the ELA outcomes of every coaching picture
On this step, we generate the ELA outcome (at 90% high quality) of the enter coaching picture. The operate convert_to_ela_image takes two parameters: path, which is the trail to a picture file, and high quality, representing the standard parameter for JPEG compression. The operate performs the next steps:
- Convert the picture to RGB format and resave the picture as a JPEG file with the required high quality below the identify tempresaved.jpg.
- Compute the distinction between the unique picture and the resaved JPEG picture (ELA) to find out the utmost distinction in pixel values between the unique and resaved pictures.
- Calculate a scale issue primarily based on the utmost distinction to regulate the brightness of the ELA picture.
- Improve the brightness of the ELA picture utilizing the calculated scale issue.
- Resize the ELA outcome to 128x128x3, the place 3 represents the variety of channels to scale back the enter measurement for coaching.
- Return the ELA picture.
In lossy picture codecs similar to JPEG, the preliminary saving course of results in appreciable shade loss. Nevertheless, when the picture is loaded and subsequently re-encoded in the identical lossy format, there’s usually much less added shade degradation. ELA outcomes emphasize the picture areas most inclined to paint degradation upon resaving. Typically, alterations seem prominently in areas exhibiting increased potential for degradation in comparison with the remainder of the picture.
Subsequent, the photographs are processed right into a NumPy array for coaching. We then break up the enter dataset randomly into coaching and check or validation knowledge (80/20). You may ignore any warnings when working these cells.
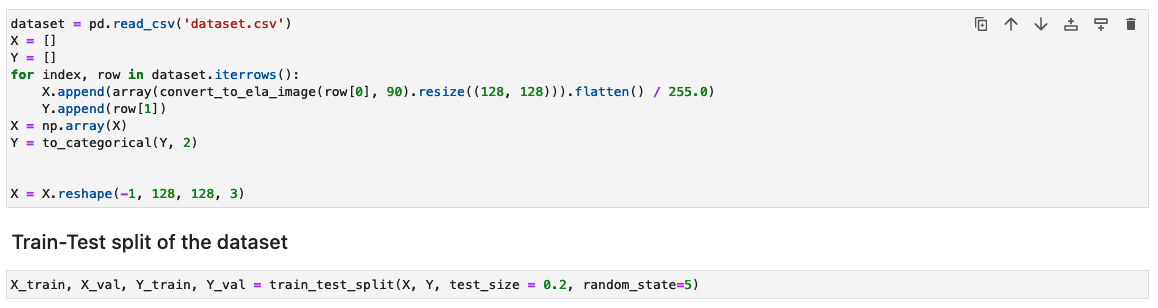
Relying on the dimensions of dataset, working these cells may take time to finish. For the pattern dataset we offered on this repository, it may take 5–10 minutes.
Configure the CNN mannequin
On this step, we assemble a minimal model of the VGG community with small convolutional filters. The VGG-16 consists of 13 convolutional layers and three totally related layers. The next screenshot illustrates the structure of our Convolutional Neural Community (CNN) mannequin.
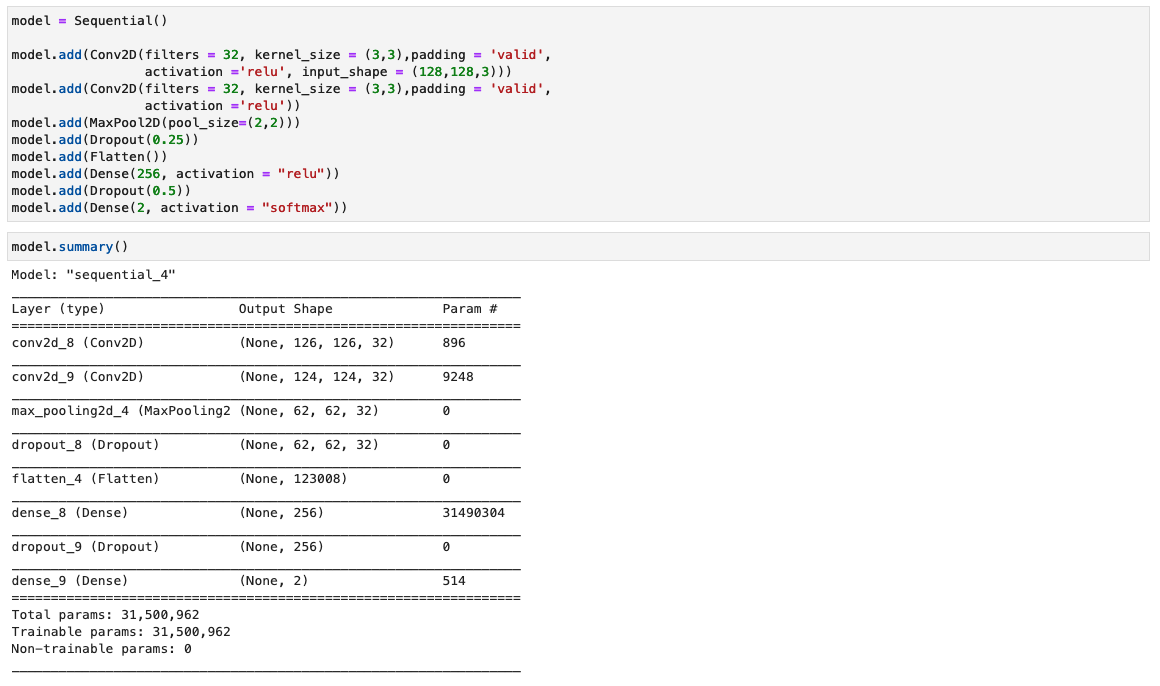
Word the next configurations:
- Enter – The mannequin takes in a picture enter measurement of 128x128x3.
- Convolutional layers – The convolutional layers use a minimal receptive area (3×3), the smallest doable measurement that also captures up/down and left/proper. That is adopted by a rectified linear unit (ReLU) activation operate that reduces coaching time. This can be a linear operate that can output the enter if optimistic; in any other case, the output is zero. The convolution stride is mounted on the default (1 pixel) to maintain the spatial decision preserved after convolution (stride is the variety of pixel shifts over the enter matrix).
- Absolutely related layers – The community has two totally related layers. The primary dense layer makes use of ReLU activation, and the second makes use of softmax to categorise the picture as authentic or tampered.
You may ignore any warnings when working these cells.
Save the mannequin artifacts
Save the skilled mannequin with a novel file identify—for instance, primarily based on the present date and time—right into a listing named mannequin.

The mannequin is saved in Keras format with the extension .keras. We additionally save the mannequin artifacts as a listing named 1 containing serialized signatures and the state wanted to run them, together with variable values and vocabularies to deploy to a SageMaker runtime (which we talk about later on this publish).
Measure mannequin efficiency
The next loss curve exhibits the development of the mannequin’s loss over coaching epochs (iterations).
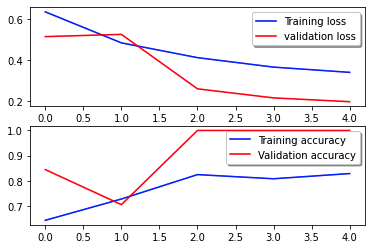
The loss operate measures how effectively the mannequin’s predictions match the precise targets. Decrease values point out higher alignment between predictions and true values. Reducing loss over epochs signifies that the mannequin is enhancing. The accuracy curve illustrates the mannequin’s accuracy over coaching epochs. Accuracy is the ratio of appropriate predictions to the full variety of predictions. Greater accuracy signifies a better-performing mannequin. Sometimes, accuracy will increase throughout coaching because the mannequin learns patterns and improves its predictive skill. These will assist you decide if the mannequin is overfitting (performing effectively on coaching knowledge however poorly on unseen knowledge) or underfitting (not studying sufficient from the coaching knowledge).
The next confusion matrix visually represents how effectively the mannequin precisely distinguishes between the optimistic (cast picture, represented as worth 1) and damaging (untampered picture, represented as worth 0) courses.
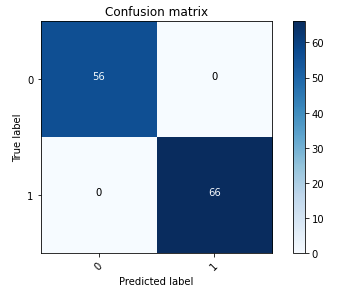
Following the mannequin coaching, our subsequent step includes deploying the pc imaginative and prescient mannequin as an API. This API will probably be built-in into enterprise purposes as a element of the underwriting workflow. To attain this, we use Amazon SageMaker Inference, a completely managed service. This service seamlessly integrates with MLOps instruments, enabling scalable mannequin deployment, cost-efficient inference, enhanced mannequin administration in manufacturing, and decreased operational complexity. On this publish, we deploy the mannequin as a real-time inference endpoint. Nevertheless, it’s necessary to notice that, relying on the workflow of your online business purposes, the mannequin deployment will also be tailor-made as batch processing, asynchronous dealing with, or by means of a serverless deployment structure.
Arrange the mannequin deployment pocket book
Full the next steps to arrange your mannequin deployment pocket book:
- Open the
tampering_detection_model_deploy.ipynbfile from document-tampering-detection listing. - Arrange the pocket book setting with the picture Information Science 3.0.
- For Kernel, select Python3.
- For Occasion kind, select ml.t3.medium.
With an ml.t3.medium pocket book setting, the fee per hour is $0.056 USD.
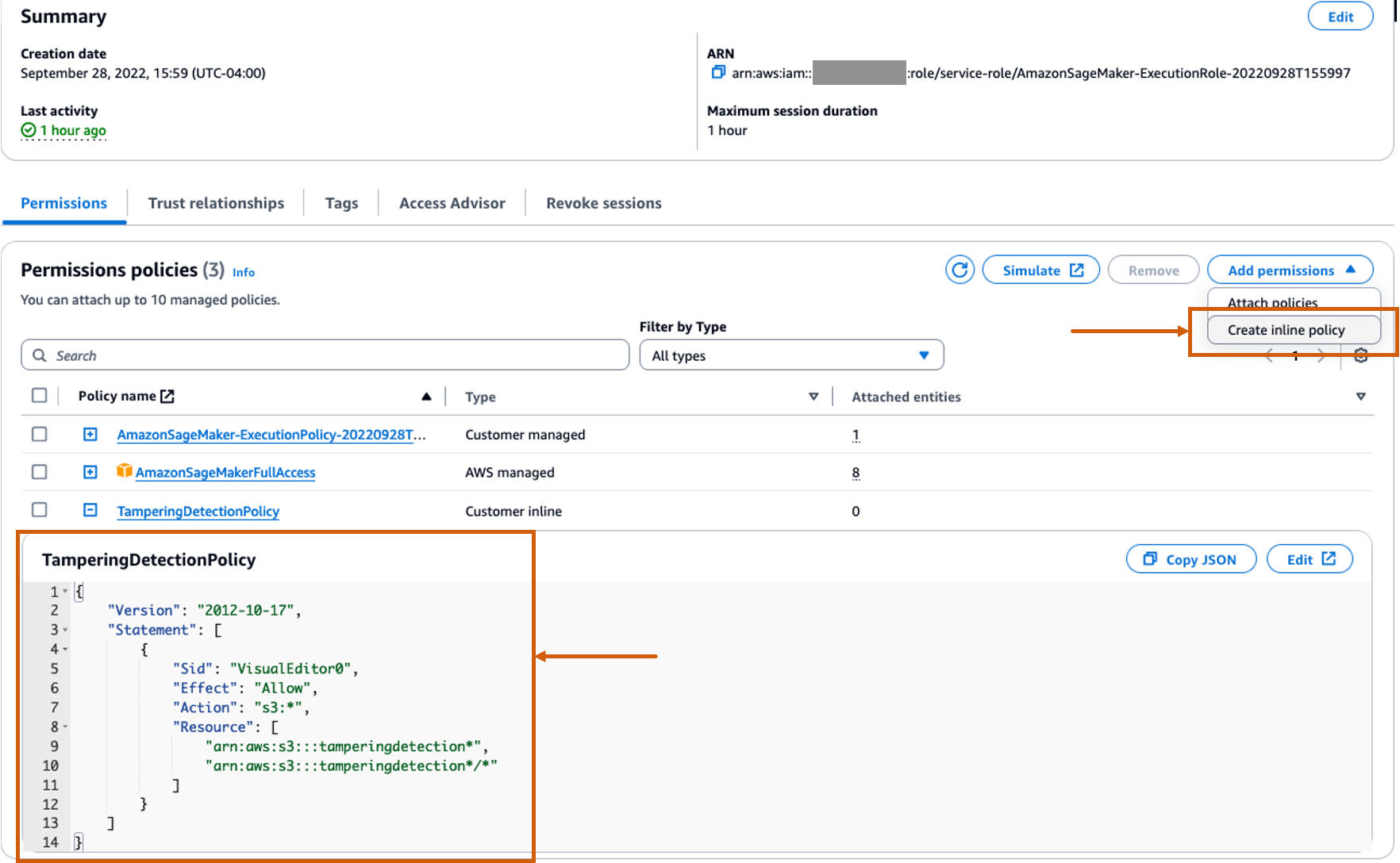
Create a customized inline coverage for the SageMaker function to permit all Amazon S3 actions
The AWS Identity and Access Management (IAM) function for SageMaker will probably be within the format AmazonSageMaker- ExecutionRole-<random numbers>. Be sure to’re utilizing the proper function. The function identify will be discovered below the consumer particulars throughout the SageMaker area configurations.
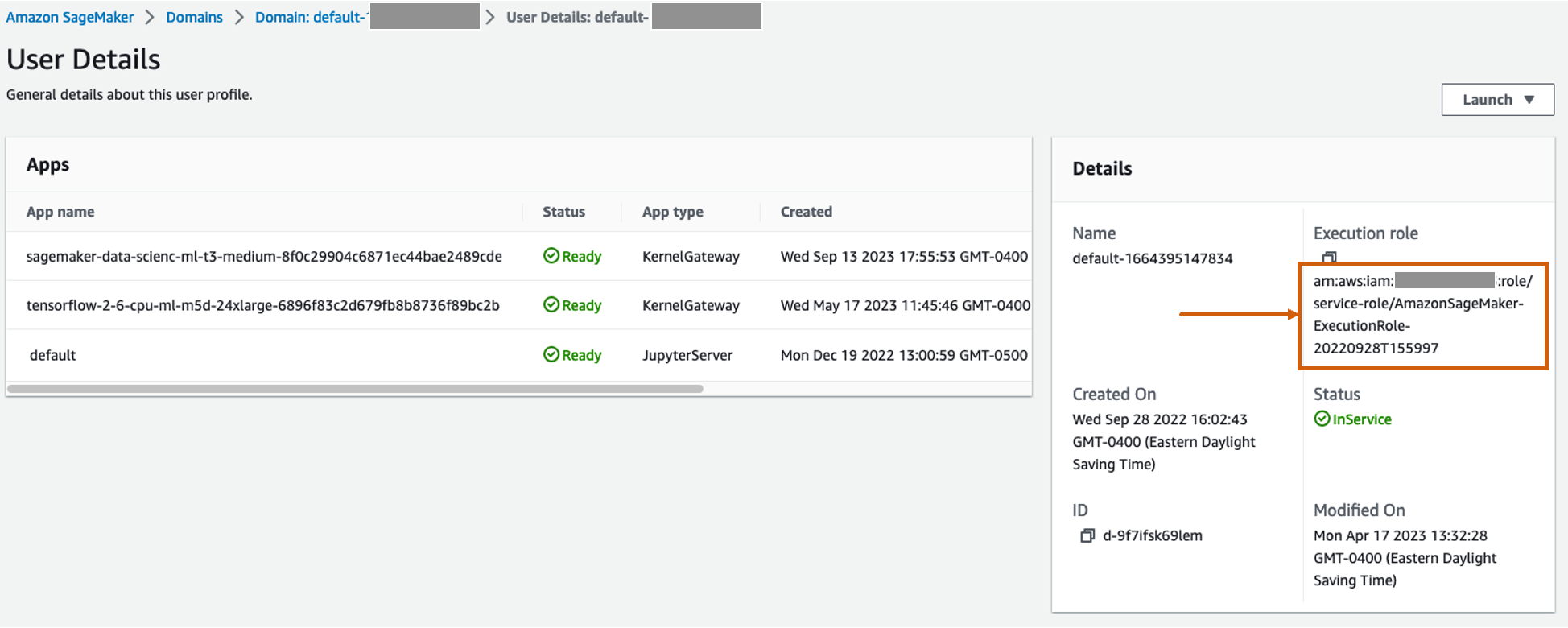
Replace the IAM function to incorporate an inline coverage to permit all Amazon Simple Storage Service (Amazon S3) actions. This will probably be required to automate the creation and deletion of S3 buckets that can retailer the mannequin artifacts. You may restrict the entry to particular S3 buckets. Word that we used a wildcard for the S3 bucket identify within the IAM coverage (tamperingdetection*).
Run the deployment pocket book
Run every cell within the pocket book tampering_detection_model_deploy.ipynb so as. We talk about some cells in additional element within the following sections.
Create an S3 bucket
Run the cell to create an S3 bucket. The bucket will probably be named tamperingdetection<present date time> and in the identical AWS Area as your SageMaker Studio setting.

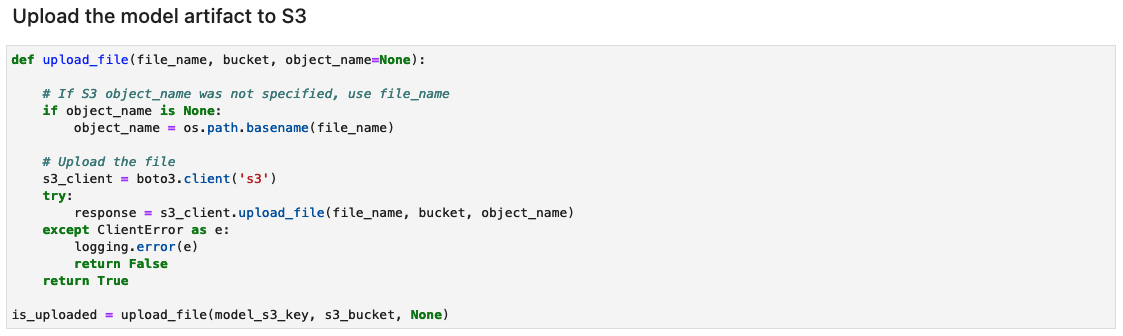
Create the mannequin artifact archive and add to Amazon S3
Create a tar.gz file from the mannequin artifacts. We’ve saved the mannequin artifacts as a listing named 1, containing serialized signatures and the state wanted to run them, together with variable values and vocabularies to deploy to the SageMaker runtime. You may also embody a customized inference file referred to as inference.py throughout the code folder within the mannequin artifact. The customized inference can be utilized for preprocessing and postprocessing of the enter picture.
![]()
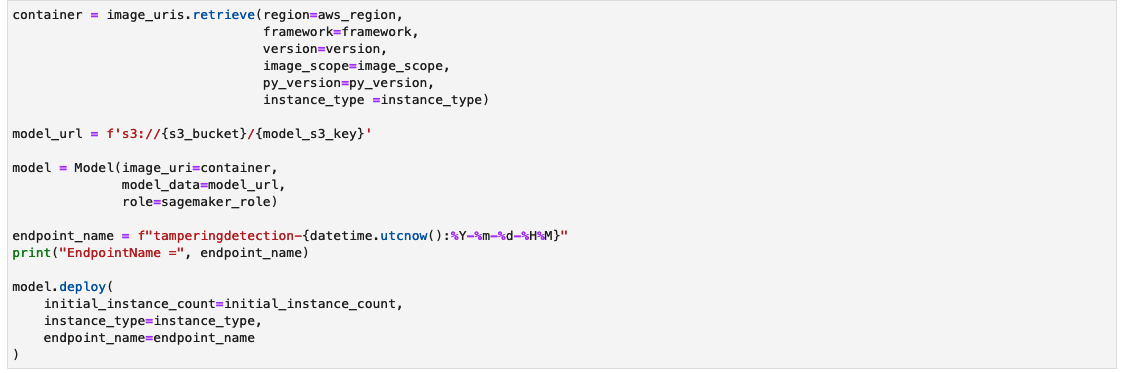
Create a SageMaker inference endpoint
The cell to create a SageMaker inference endpoint could take a couple of minutes to finish.
Take a look at the inference endpoint
The operate check_image preprocesses a picture as an ELA picture, sends it to a SageMaker endpoint for inference, retrieves and processes the mannequin’s predictions, and prints the outcomes. The mannequin takes a NumPy array of the enter picture as an ELA picture to offer predictions. The predictions are output as 0, representing an untampered picture, and 1, representing a cast picture.

Let’s invoke the mannequin with an untampered picture of a paystub and examine the outcome.

The mannequin outputs the classification as 0, representing an untampered picture.
Now let’s invoke the mannequin with a tampered picture of a paystub and examine the outcome.

The mannequin outputs the classification as 1, representing a cast picture.
Limitations
Though ELA is a superb instrument for serving to detect modifications, there are a selection of limitations, similar to the next:
- A single pixel change or minor shade adjustment could not generate a noticeable change within the ELA as a result of JPEG operates on a grid.
- ELA solely identifies what areas have completely different compression ranges. If a lower-quality picture is spliced right into a higher-quality image, then the lower-quality picture could seem as a darker area.
- Scaling, recoloring, or including noise to a picture will modify your complete picture, creating a better error stage potential.
- If a picture is resaved a number of instances, then it might be totally at a minimal error stage, the place extra resaves don’t alter the picture. On this case, the ELA will return a black picture and no modifications will be recognized utilizing this algorithm.
- With Photoshop, the straightforward act of saving the image can auto-sharpen textures and edges, creating a better error stage potential. This artifact doesn’t determine intentional modification; it identifies that an Adobe product was used. Technically, ELA seems as a modification as a result of Adobe robotically carried out a modification, however the modification was not essentially intentional by the consumer.
We suggest utilizing ELA alongside different methods beforehand mentioned within the weblog with a purpose to detect a better vary of picture manipulation circumstances. ELA can even function an unbiased instrument for visually analyzing picture disparities, particularly when coaching a CNN-based mannequin turns into difficult.
Clear up
To take away the assets you created as a part of this resolution, full the next steps:
- Run the pocket book cells below the Cleanup part. This can delete the next:
- SageMaker inference endpoint – The inference endpoint identify will probably be
tamperingdetection-<datetime>. - Objects throughout the S3 bucket and the S3 bucket itself – The bucket identify will probably be
tamperingdetection<datetime>.
- SageMaker inference endpoint – The inference endpoint identify will probably be
- Shut down the SageMaker Studio pocket book assets.
Conclusion
On this publish, we offered an end-to-end resolution for detecting doc tampering and fraud utilizing deep studying and SageMaker. We used ELA to preprocess pictures and determine discrepancies in compression ranges which will point out manipulation. Then we skilled a CNN mannequin on this processed dataset to categorise pictures as authentic or tampered.
The mannequin can obtain sturdy efficiency, with an accuracy over 95% with a dataset (cast and authentic) suited to your online business necessities. This means that it could possibly reliably detect cast paperwork like paystubs and financial institution statements. The skilled mannequin is deployed to a SageMaker endpoint to allow low-latency inference at scale. By integrating this resolution into mortgage workflows, establishments can robotically flag suspicious paperwork for additional fraud investigation.
Though highly effective, ELA has some limitations in figuring out sure sorts of extra refined manipulation. As subsequent steps, the mannequin might be enhanced by incorporating further forensic methods into coaching and utilizing bigger, extra various datasets. General, this resolution demonstrates how you should utilize deep studying and AWS companies to construct impactful options that enhance effectivity, scale back threat, and forestall fraud.
In Half 3, we show the way to implement the answer on Amazon Fraud Detector.
In regards to the authors
 Anup Ravindranath is a Senior Options Architect at Amazon Internet Companies (AWS) primarily based in Toronto, Canada working with Monetary Companies organizations. He helps prospects to remodel their companies and innovate on cloud.
Anup Ravindranath is a Senior Options Architect at Amazon Internet Companies (AWS) primarily based in Toronto, Canada working with Monetary Companies organizations. He helps prospects to remodel their companies and innovate on cloud.
 Vinnie Saini is a Senior Options Architect at Amazon Internet Companies (AWS) primarily based in Toronto, Canada. She has been serving to Monetary Companies prospects rework on cloud, with AI and ML pushed options laid on sturdy foundational pillars of Architectural Excellence.
Vinnie Saini is a Senior Options Architect at Amazon Internet Companies (AWS) primarily based in Toronto, Canada. She has been serving to Monetary Companies prospects rework on cloud, with AI and ML pushed options laid on sturdy foundational pillars of Architectural Excellence.




