The Solely Free Course You Want To Change into a Skilled Knowledge Engineer
Picture by Writer
There are a lot of programs and assets out there on machine studying and information science, however only a few on information engineering. This raises some questions. Is it a troublesome area? Is it providing low pay? Is it not thought of as thrilling as different tech roles? Nevertheless, the truth is that many corporations are actively in search of information engineering expertise and providing substantial salaries, generally exceeding $200,000 USD. Knowledge engineers play a vital function because the architects of information platforms, designing and constructing the foundational methods that allow information scientists and machine studying specialists to perform successfully.
Addressing this trade hole, DataTalkClub has launched a transformative and free bootcamp, “Data Engineering Zoomcamp“. This course is designed to empower novices or professionals trying to swap careers, with important abilities and sensible expertise in information engineering.
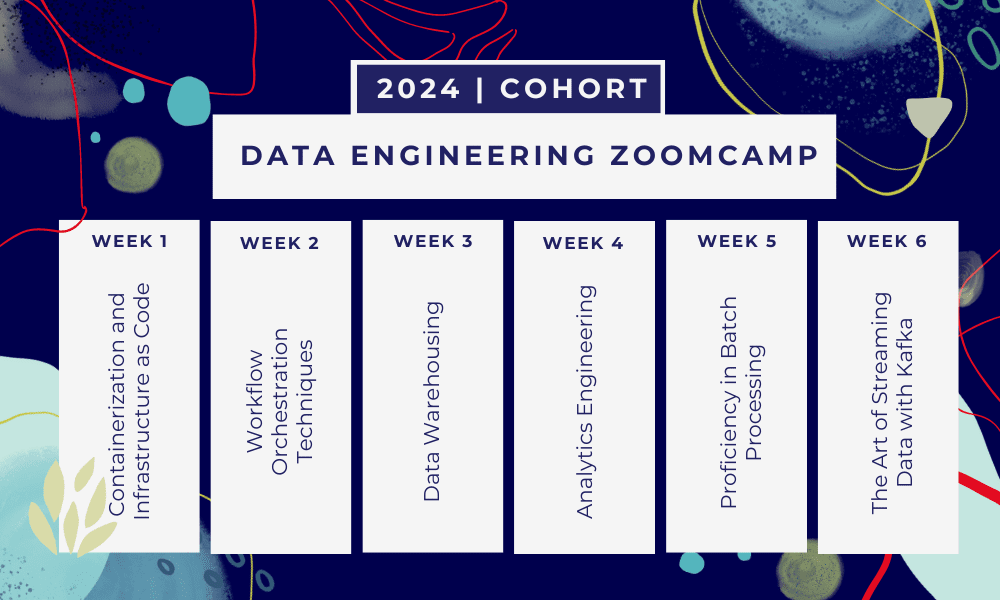
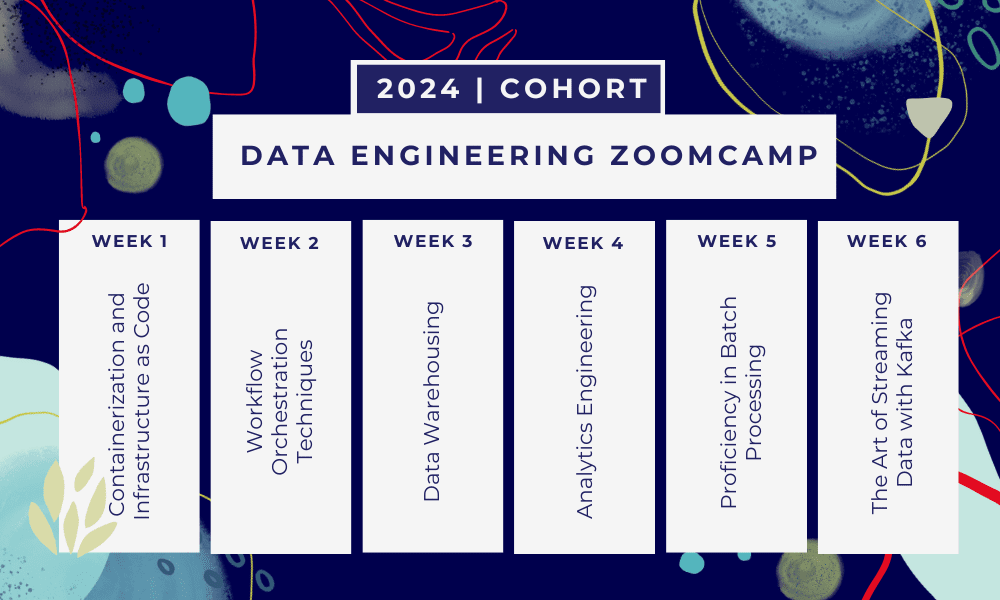
This can be a 6-week bootcamp the place you’ll be taught by way of a number of programs, studying supplies, workshops, and initiatives. On the finish of every module, you may be given homework to apply what you have discovered.
- Week 1: Introduction to GCP, Docker, Postgres, Terraform, and surroundings setup.
- Week 2: Workflow orchestration with Mage.
- Week 3: Knowledge warehousing with BigQuery and machine studying with BigQuery.
- Week 4: Analytical engineer with dbt, Google Knowledge Studio, and Metabase.
- Week 5: Batch processing with Spark.
- Week 6: Streaming with Kafka.
Picture from DataTalksClub/data-engineering-zoomcamp
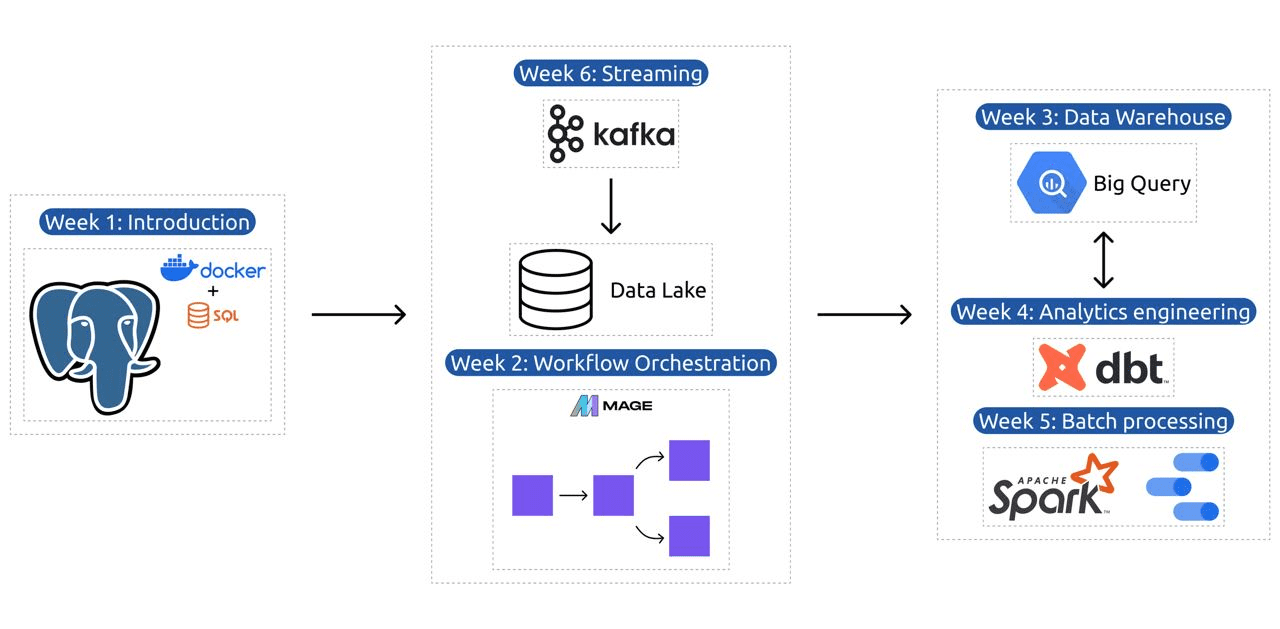
The syllabus comprises 6 modules, 2 workshops, and a challenge that covers all the pieces wanted for changing into knowledgeable information engineer.
Module 1: Mastering Containerization and Infrastructure as Code
On this module, you’ll be taught in regards to the Docker and Postgres, beginning with the fundamentals and advancing by way of detailed tutorials on creating information pipelines, working Postgres with Docker, and extra.
The module additionally covers important instruments like pgAdmin, Docker-compose, and SQL refresher subjects, with optionally available content material on Docker networking and a particular walk-through for Home windows subsystem Linux customers. Ultimately, the course introduces you to GCP and Terraform, offering a holistic understanding of containerization and infrastructure as a code, important for contemporary cloud-based environments.
Module 2: Workflow Orchestration Methods
The module affords an in-depth exploration of Mage, an progressive open-source hybrid framework for information transformation and integration. This module begins with the fundamentals of workflow orchestration, progressing to hands-on workout routines with Mage, together with setting it up by way of Docker and constructing ETL pipelines from API to Postgres and Google Cloud Storage (GCS), after which into BigQuery.
The module’s mix of movies, assets, and sensible duties ensures a complete studying expertise, equipping learners with the talents to handle refined information workflows utilizing Mage.
Workshop 1: Knowledge Ingestion Methods
Within the first workshop you’ll grasp constructing environment friendly information ingestion pipelines. The workshop focuses on important abilities like extracting information from APIs and information, normalizing and loading information, and incremental loading methods. After finishing this workshop, it is possible for you to to create environment friendly information pipelines like a senior information engineer.
Module 3: Knowledge Warehousing
The module is an in-depth exploration of information storage and evaluation, specializing in Knowledge Warehousing utilizing BigQuery. It covers key ideas similar to partitioning and clustering, and dives into BigQuery’s finest practices. The module progresses into superior subjects, notably the combination of Machine Studying (ML) with BigQuery, highlighting using SQL for ML, and offering assets on hyperparameter tuning, characteristic preprocessing, and mannequin deployment.
Module 4: Analytics Engineering
The analytics engineering module focuses on constructing a challenge utilizing dbt (Knowledge Construct Device) with an present information warehouse, both BigQuery or PostgreSQL.
The module covers establishing dbt in each cloud and native environments, introducing analytics engineering ideas, ETL vs ELT, and information modeling. It additionally covers superior dbt options similar to incremental fashions, tags, hooks, and snapshots.
Ultimately, the module introduces methods for visualizing reworked information utilizing instruments like Google Knowledge Studio and Metabase, and it supplies assets for troubleshooting and environment friendly information loading.
Module 5: Proficiency in Batch Processing
This module covers batch processing utilizing Apache Spark, beginning with introductions to batch processing and Spark, together with set up directions for Home windows, Linux, and MacOS.
It contains exploring Spark SQL and DataFrames, getting ready information, performing SQL operations, and understanding Spark internals. Lastly, it concludes with working Spark within the cloud and integrating Spark with BigQuery.
Module 6: The Artwork of Streaming Knowledge with Kafka
The module begins with an introduction to stream processing ideas, adopted by in-depth exploration of Kafka, together with its fundamentals, integration with Confluent Cloud, and sensible functions involving producers and shoppers.
The module additionally covers Kafka configuration and streams, addressing subjects like stream joins, testing, windowing, and using Kafka ksqldb & Join. Moreover, it extends its focus to Python and JVM environments, that includes Faust for Python stream processing, Pyspark – Structured Streaming, and Scala examples for Kafka Streams.
Workshop 2: Stream Processing with SQL
You’ll be taught to course of and handle streaming information with RisingWave, which supplies a cost-efficient resolution with a PostgreSQL-style expertise to empower your stream processing functions.
Challenge: Actual-World Knowledge Engineering Software
The target of this challenge is to implement all of the ideas we now have discovered on this course to assemble an end-to-end information pipeline. You may be creating to create a dashboard consisting of two tiles by choosing a dataset, constructing a pipeline for processing the information and storing it in a knowledge lake, constructing a pipeline for transferring the processed information from the information lake to a knowledge warehouse, remodeling the information within the information warehouse and getting ready it for the dashboard, and eventually constructing a dashboard to current the information visually.
2024 Cohort Particulars
- Registration: Enroll Now
- Begin date: January 15, 2024, at 17:00 CET
- Self-paced studying with guided assist
- Cohort folder with homeworks and deadlines
- Interactive Slack Community for peer studying
Stipulations
- Primary coding and command line abilities
- Basis in SQL
- Python: helpful however not obligatory
Skilled Instructors Main Your Journey
- Ankush Khanna
- Victoria Perez Mola
- Alexey Grigorev
- Matt Palmer
- Luis Oliveira
- Michael Shoemaker
Be part of our 2024 cohort and begin studying with an incredible information engineering group. With expert-led coaching, hands-on expertise, and a curriculum tailor-made to the wants of the trade, this bootcamp not solely equips you with the required abilities but additionally positions you on the forefront of a profitable and in-demand profession path. Enroll right this moment and rework your aspirations into actuality!
Abid Ali Awan (@1abidaliawan) is a licensed information scientist skilled who loves constructing machine studying fashions. At the moment, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in Expertise Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.





