Foundational knowledge safety for enterprise LLM acceleration with Protopia AI
This put up is written in collaboration with Balaji Chandrasekaran, Jennifer Cwagenberg and Andrew Sansom and Eiman Ebrahimi from Protopia AI.
New and highly effective massive language fashions (LLMs) are altering companies quickly, enhancing effectivity and effectiveness for quite a lot of enterprise use instances. Pace is of the essence, and adoption of LLM applied sciences could make or break a enterprise’s aggressive benefit. AWS is particularly properly suited to offer enterprises the instruments crucial for deploying LLMs at scale to allow crucial decision-making.
Of their implementation of generative AI expertise, enterprises have actual considerations about knowledge publicity and possession of confidential data which may be despatched to LLMs. These considerations of privateness and knowledge safety can decelerate or restrict the utilization of LLMs in organizations. Enterprises want a accountable and safer solution to ship delicate data to the fashions with no need to tackle the usually prohibitively excessive overheads of on-premises DevOps.
The put up describes how one can overcome the challenges of retaining knowledge possession and preserving knowledge privateness whereas utilizing LLMs by deploying Protopia AI’s Stained Glass Rework to guard your knowledge. Protopia AI has partnered with AWS to ship the crucial part of information safety and possession for safe and environment friendly enterprise adoption of generative AI. This put up outlines the answer and demonstrates how it may be utilized in AWS for standard enterprise use instances like Retrieval Augmented Generation (RAG) and with state-of-the-art LLMs like Llama 2.
Stained Glass Rework overview
Organizations search to retain full possession and management of their delicate enterprise knowledge. This can be a pillar of accountable AI and an rising knowledge safety and privateness requirement above and past primary safety and authorized ensures of LLM suppliers.
Though enterprise enterprise items wish to make the most of LLMs for varied duties, they’re additionally involved about commerce secrets and techniques, mental property, and different proprietary data leaking by way of knowledge despatched to those fashions. On the identical time, enterprise safety, compliance, knowledge administration, and knowledge workplaces are apprehensive of exposing or leaking plain textual content buyer data or different regulated knowledge exterior of the enterprise. AWS and Protopia AI are partnering to ship the crucial part that solves this widespread enterprise buyer want.
Protopia AI’s Stained Glass Rework (SGT) solves these challenges by changing unprotected enterprise knowledge to a randomized re-representation, known as RmoRed knowledge, as proven within the following determine. This illustration is a stochastic embedding of the unique knowledge, preserving the data the goal LLM must perform with out exposing delicate prompts or queries, context, or fine-tuning knowledge. This re-representation is a one-way transformation that may’t be reversed, guaranteeing holistic privateness of enterprise knowledge and safety towards leaking plain textual content delicate data to LLMs. SGT’s applicability just isn’t restricted to language fashions. Randomized re-representations may also be generated for visible and structured knowledge. The identify Stained Glass Rework is rooted within the visible look of randomized re-representations of visible knowledge that may resemble viewing the info by way of stained glass, as demonstrated on this US Navy use case.

SGT works with state-of-the-art LLMs resembling Llama 2. The next determine reveals an instance of making use of SGT to a Llama 2 mannequin for instruction following whereas including a layer of safety to the instruction and context. The left aspect of the determine reveals an instance of a monetary doc as context, with the instruction asking the mannequin to summarize the doc. On the underside left, the response generated by Llama 2 when working on the uncooked immediate is proven. When utilizing SGT, the embeddings related to this immediate are remodeled on the shopper aspect into stochastic embeddings, as described in additional element later on this put up. The underside proper reveals Llama 2 can nonetheless generate an accurate response if the RmoRed knowledge (post-transformation embeddings) are despatched as a substitute of the unprotected embeddings. The highest proper reveals that if the RmoRed knowledge leaked, a reconstruction of the unique immediate would lead to unintelligible textual content.

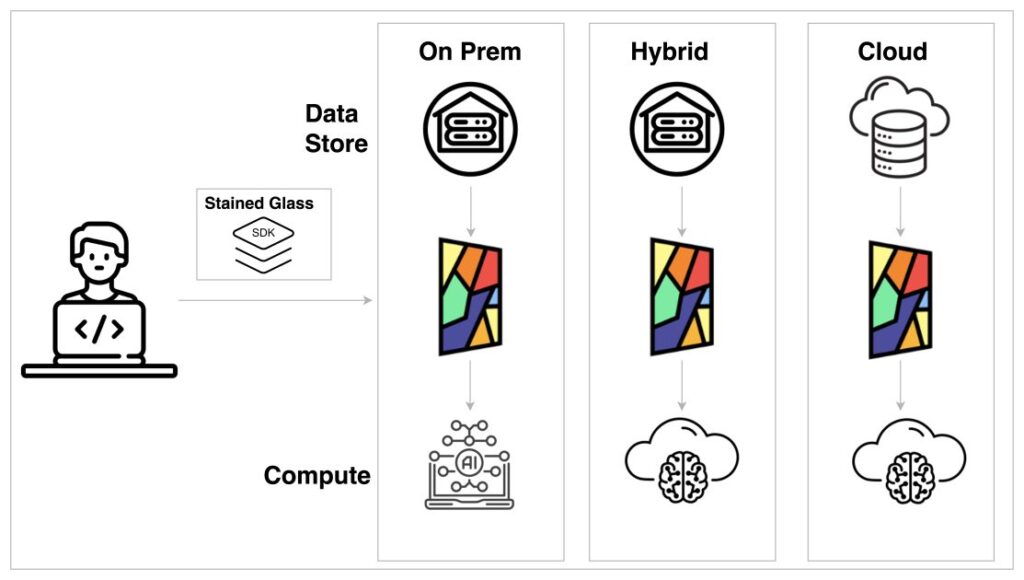
To create an SGT for a given mannequin resembling Llama 2, Protopia AI gives a light-weight library known as the Stained Glass SDK, which is an extension of PyTorch. As proven within the following determine, after an SGT is created, it may be built-in into deployment pipelines in a number of methods. The remodel that’s created from the SDK will be deployed regionally, in a hybrid setup, or fully on the cloud. That is potential as a result of SGT is designed to be a light-weight course of requiring little or no compute sources and as such has minimal affect on the inference crucial path. One other key analysis is retention of mannequin accuracy utilizing re-represented knowledge. We observe that throughout totally different knowledge varieties and mannequin variations, accuracy is retained inside fascinating tolerance limits when utilizing re-represented knowledge.

These choices for deployment and sustaining the accuracy permits for assured adoption of SGT by all of the stakeholders inside an enterprise group. To additional defend the output of the LLM, Protopia AI can encode question outputs to a illustration whose decoder is just accessible to the enterprise knowledge proprietor.
Resolution overview
The earlier part described how you need to use Stained Glass Rework in quite a lot of architectures. The next determine particulars the steps concerned in creating, deploying, and utilizing SGT for LLMs:
- SGT creation – The crew that trains the baseline LLM basis mannequin (suppliers of proprietary LLMs, cloud service supplier, or enterprise ML groups creating their very own LLMs) runs Protopia AI’s Stained Glass SDK software program with out altering their present practices for coaching and deploying the LLM. After the inspiration mannequin coaching is full, the SDK runs as an optimization go over the language mannequin to compute the SGT. This optimization go is delivered by way of an extension to PyTorch. The SDK wraps the inspiration mannequin and mathematically discovers a novel Stained Glass Rework for that LLM. Additional particulars of the underlying math will be discovered within the accompanying whitepaper. Observe that as a result of the crew coaching the LLM itself can also be working the Stained Glass SDK, there isn’t any publicity or sending of mannequin weights that’s crucial for this step to be accomplished.
- SGT launch and deployment – The SGT that’s output from the sooner optimization step is deployed as a part of the info pipeline that feeds the educated LLM. As described within the earlier part, the SGT sits on the enterprise shopper aspect.
- SGT use – The SGT runs on the prompts created by the enterprise and generates protected prompts, that are despatched to the deployed LLM. This permits the enterprise to retain possession of their delicate queries and context. Utilizing Protopia AI Stained Glass, the unprotected delicate knowledge doesn’t depart the enterprise’s website or belief zone.

You should use the Stained Glass SDK to create an SGT in a number of methods. For instance, you need to use the Stained Glass SDK in self-managed machine studying (ML) environments with Amazon Elastic Kubernetes Service (Amazon EKS) for coaching and inferencing or inside Amazon Elastic Compute Cloud (Amazon EC2) instantly. An alternative choice is it may well run inside Amazon SageMaker to create an SGT for a given educated mannequin. Reworking the enter for deployment throughout inference from the shopper is unbiased of the chosen deployment implementation.
The next determine illustrates a potential implementation in a self-managed ML surroundings the place coaching a Stained Glass Rework is carried out on Amazon EKS.

On this workflow, a container is created utilizing the Stained Glass SDK and deployed to Amazon Elastic Container Registry (Amazon ECR). This container is then deployed on Amazon EKS to coach an SGT that’s saved to Amazon Simple Storage Service (Amazon S3). In case you’re utilizing Amazon EC2, you’ll be able to practice a change instantly in your occasion as a part of your ML setup. The Stained Glass SDK can run on quite a lot of occasion varieties, together with Amazon P5, P4, or G5 occasion households, primarily based in your base LLM necessities. After the LLM is deployed for use for inference, the shopper utility makes use of the created SGT, which is a light-weight operation, to rework prompts and context earlier than sending them to the LLM. By doing so, solely remodeled knowledge is uncovered to the LLM, and possession of the unique enter is retained on the shopper aspect.
The next determine demonstrates how one can practice a remodel and run inferencing on SageMaker.

The creation of the SGT follows an analogous path because the Amazon EKS setup by ingesting the coaching knowledge from Amazon S3, coaching an SGT on a container, and saving it to Amazon S3. You should use the Stained Glass SDK in your present SageMaker setup with Amazon SageMaker Studio, SageMaker notebooks, and a SageMaker training job. The LLM is hosted as a SageMaker endpoint that’s accessible by the shopper utility. The inferencing for the shopper utility can also be an identical to the Amazon EKS setup, aside from what’s serving the mannequin.
Randomized re-representations to guard LLM prompts and fine-tuning knowledge
This part covers quite a lot of use instances demonstrating how randomized re-representation protects LLM prompts. The examples illustrate main implications for enterprise generative AI efforts: opening new doorways to AI use instances, accelerating pace to market whereas correctly defending enterprise knowledge, and retaining possession of the delicate knowledge required to be used in LLM prompts.
RAG use case
A well-liked enterprise use case for LLMs is Retrieval Augmented Era (RAG). The next determine reveals an illustrative instance the place the prompts and sources are protected utilizing Stained Glass. The left aspect of the determine reveals the unprotected prompts and supply data. In an enterprise implementation of RAG, the sources may embrace delicate data resembling enterprise commerce secrets and techniques, mental property, or monetary data. The suitable aspect reveals the very best reconstruction in human readable textual content from the RmoRed prompts created by the SGT.

We will observe that even in the very best reconstruction, the data is totally obfuscated. Nevertheless, the response from the mannequin with and with out the transformation is identical, with tips to the unique supply paperwork, thereby preserving the accuracy of each the query and supply paperwork whereas performing this standard enterprise use case.
Broad applicability throughout LLMs and languages
One of many highlights of the Stained Glass SDK is that it’s extremely resilient to mannequin developments and adaptable to state-of-the-art fashions resembling Llama 2. The next determine reveals an SGT that was created on a Llama 2 LLM that was beforehand fine-tuned for working with Japanese textual content. This instance additional illustrates that SGTs will be created and utilized for any language and that even inputs for fine-tuned fashions will be remodeled. The final applicability of SGT is pushed by the sturdy basis of the Stained Glass SDK being model- and data-agnostic.

Defending fine-tuning knowledge in addition to prompts
Stained Glass Rework just isn’t restricted solely to defending knowledge at inference time; it may well additionally defend knowledge used to fine-tune a basis mannequin. The method for creating the transformation for fine-tuning datasets is identical as that defined within the resolution structure part earlier on this put up. The transformation is created for the inspiration mannequin to be fine-tuned with out accessing the fine-tuning knowledge. After the SGT has been created and educated for the inspiration mannequin, the fine-tuning dataset is remodeled to randomized re-representations that may then be used to fine-tune the inspiration mannequin. This course of is defined in additional element within the accompanying whitepaper.
Within the following instance, an enterprise buyer wanted to fine-tune an present mannequin for community log anomaly detection. They used Stained Glass to rework the delicate fine-tuning dataset to randomized embeddings, which had been used to fine-tune their basis mannequin. They discovered that the detection mannequin that was fine-tuned on the remodeled representations carried out with virtually an identical accuracy in comparison with the hypothetical situation of fine-tuning the inspiration mannequin on the unprotected fine-tuning dataset. The next desk reveals two examples of plain textual content knowledge data from the fine-tuning dataset and a reconstruction to textual content of those self same knowledge data from the fine-tuning dataset.

Below the hood of Stained Glass Rework for LLMs
When utilized to laptop imaginative and prescient, SGT operates on enter pixel options, and for LLMs, it operates on the embedding degree. To spotlight how Stained Glass Rework works, think about the immediate embeddings as a matrix, as illustrated on the left of the next determine. In every entry, there’s a deterministic worth. This worth will be mapped to the unique knowledge, exposing the unprotected immediate. Stained Glass Rework converts this matrix of deterministic values to a matrix whose components are a cloud of prospects.

The remodeled immediate is rendered by sampling noise from likelihood distributions outlined by the SGT and including the sampled noise to the deterministic embeddings, which randomizes the unique immediate values irreversibly. The mannequin nonetheless understands the randomized re-represented immediate on the mathematical degree and may perform its activity precisely.
Conclusion
This put up mentioned how Protopia AI’s Stained Glass Rework decouples uncooked knowledge possession and safety from the ML operations course of, enabling enterprises to retain possession and preserve privateness of delicate data in LLM prompts and fine-tuning knowledge. By utilizing this state-of-the-art knowledge safety for LLM utilization, enterprises can speed up adoption of basis fashions and LLMs by worrying much less about publicity of delicate data. By safely unlocking the worth in actual enterprise knowledge, organizations can allow the promised efficiencies and enterprise outcomes of LLMs extra effectively and shortly. To be taught extra about this expertise, yow will discover additional studying within the accompanying whitepaper and connect with Protopia AI to get entry and check out it in your enterprise knowledge.
About Protopia AI
Protopia AI is a frontrunner in knowledge safety and privacy-preserving AI/ML applied sciences primarily based in Austin, Texas, and makes a speciality of enabling AI algorithms and software program platforms to function with out the necessity to entry plain textual content data. Over the previous 2 years, Protopia AI has efficiently demonstrated its flagship Stained Glass Rework product throughout quite a lot of ML use instances and knowledge varieties with the US Navy, main monetary providers, and world expertise suppliers.
Protopia AI works with enterprises, generative AI and LLM suppliers, and Cloud Service Suppliers (CSPs) to allow sustaining possession and confidentiality of enterprise knowledge whereas utilizing AI/ML options. Protopia AI has partnered with AWS to ship a crucial part of information safety and possession for enterprise adoption of generative AI, and was considered one of 21 startups chosen for the inaugural AWS Generative AI Accelerator in 2023.
In regards to the authors
 Balaji Chandrasekaran is the VP for Go-to-Market & Buyer Enablement at Protopia AI, works carefully with purchasers to leverage AI of their enterprise whereas prioritizing knowledge safety and privateness. Previous to Protopia AI, Balaji was the Product Lead for AI Options at Infor, creating value-centric merchandise whereas performing as a trusted associate for enterprise clients throughout various industries. Exterior work, he enjoys music, mountaineering, and touring with household.
Balaji Chandrasekaran is the VP for Go-to-Market & Buyer Enablement at Protopia AI, works carefully with purchasers to leverage AI of their enterprise whereas prioritizing knowledge safety and privateness. Previous to Protopia AI, Balaji was the Product Lead for AI Options at Infor, creating value-centric merchandise whereas performing as a trusted associate for enterprise clients throughout various industries. Exterior work, he enjoys music, mountaineering, and touring with household.
 Jennifer Cwagenberg leads the engineering crew at Protopia AI and works to make sure that the Stained Glass expertise meets the wants of their clients to guard their knowledge. Jennifer has prior expertise with safety working at Toyota of their Product Cybersecurity Group, managing Cloud workloads at N-able, and liable for knowledge at Match.com.
Jennifer Cwagenberg leads the engineering crew at Protopia AI and works to make sure that the Stained Glass expertise meets the wants of their clients to guard their knowledge. Jennifer has prior expertise with safety working at Toyota of their Product Cybersecurity Group, managing Cloud workloads at N-able, and liable for knowledge at Match.com.
 Andrew Sansom is an AI Options Engineer at Protopia AI the place he helps enterprises use AI whereas preserving non-public and delicate data of their knowledge. Previous to Protopia AI, he labored as a Technical Guide targeted on enabling AI options for purchasers throughout many industries together with Finance, Manufacturing, Healthcare, and Training. He additionally taught Laptop Science and Math to Excessive Faculty, College, and Skilled college students.
Andrew Sansom is an AI Options Engineer at Protopia AI the place he helps enterprises use AI whereas preserving non-public and delicate data of their knowledge. Previous to Protopia AI, he labored as a Technical Guide targeted on enabling AI options for purchasers throughout many industries together with Finance, Manufacturing, Healthcare, and Training. He additionally taught Laptop Science and Math to Excessive Faculty, College, and Skilled college students.
 Eiman Ebrahimi, PhD, is a co-founder and the Chief Government Officer of Protopia AI. Dr. Ebrahimi is enthusiastic about enabling AI to complement the human expertise throughout totally different societal and business verticals. Protopia AI is a imaginative and prescient for enhancing the lens by way of which AI observes the mandatory and high quality knowledge it wants whereas creating novel capabilities for safeguarding delicate data. Previous to Protopia AI, he was a Senior Analysis Scientist at NVIDIA for 9 years. His work at NVIDIA analysis aimed to resolve issues of accessing large datasets in ML/AI. He additionally co-authored peer-reviewed publications on the way to make the most of the ability of hundreds of GPUs to make coaching massive language fashions possible.
Eiman Ebrahimi, PhD, is a co-founder and the Chief Government Officer of Protopia AI. Dr. Ebrahimi is enthusiastic about enabling AI to complement the human expertise throughout totally different societal and business verticals. Protopia AI is a imaginative and prescient for enhancing the lens by way of which AI observes the mandatory and high quality knowledge it wants whereas creating novel capabilities for safeguarding delicate data. Previous to Protopia AI, he was a Senior Analysis Scientist at NVIDIA for 9 years. His work at NVIDIA analysis aimed to resolve issues of accessing large datasets in ML/AI. He additionally co-authored peer-reviewed publications on the way to make the most of the ability of hundreds of GPUs to make coaching massive language fashions possible.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Net Providers (AWS). He’s partnering with high generative AI mannequin builders, strategic clients, key AI/ML companions, and AWS Service Groups to allow the following era of synthetic intelligence, machine studying, and accelerated computing on AWS. He was beforehand an Enterprise Options Architect, and the World Options Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Net Providers (AWS). He’s partnering with high generative AI mannequin builders, strategic clients, key AI/ML companions, and AWS Service Groups to allow the following era of synthetic intelligence, machine studying, and accelerated computing on AWS. He was beforehand an Enterprise Options Architect, and the World Options Lead for AWS Mergers & Acquisitions Advisory.





