How This fall Inc. used Amazon Bedrock, RAG, and SQLDatabaseChain to handle numerical and structured dataset challenges constructing their Q&A chatbot
This submit is co-written with Stanislav Yeshchenko from This fall Inc.
Enterprises flip to Retrieval Augmented Technology (RAG) as a mainstream strategy to constructing Q&A chatbots. We proceed to see rising challenges stemming from the character of the assortment of datasets out there. These datasets are sometimes a mixture of numerical and textual content information, at instances structured, unstructured, or semi-structured.
Q4 Inc. wanted to handle a few of these challenges in one in all their many AI use circumstances constructed on AWS. On this submit, we talk about a Q&A bot use case that This fall has carried out, the challenges that numerical and structured datasets offered, and the way This fall concluded that utilizing SQL could also be a viable resolution. Lastly, we take a more in-depth take a look at how the This fall staff used Amazon Bedrock and SQLDatabaseChain to implement a RAG-based resolution with SQL era.
Use case overview
This fall Inc., headquartered in Toronto, with workplaces in New York and London, is a number one capital markets entry platform that’s remodeling how issuers, buyers, and sellers effectively join, talk, and interact with one another. The This fall Platform facilitates interactions throughout the capital markets by IR web site merchandise, digital occasions options, engagement analytics, investor relations Buyer Relationship Administration (CRM), shareholder and market evaluation, surveillance, and ESG instruments.
In as we speak’s fast-paced and data-driven monetary panorama, Investor Relations Officers (IROs) play a crucial position in fostering communication between an organization and its shareholders, analysts, and buyers. As a part of their every day duties, IROs analyze various datasets, together with CRM, possession information, and inventory market information. The combination of this information is used to generate monetary studies, set investor relations targets, and handle communication with present and potential buyers.
To fulfill the rising demand for environment friendly and dynamic information retrieval, This fall aimed to create a chatbot Q&A device that would supply an intuitive and simple methodology for IROs to entry the required info they want in a user-friendly format.
The top purpose was to create a chatbot that might seamlessly combine publicly out there information, together with proprietary customer-specific This fall information, whereas sustaining the very best degree of safety and information privateness. As for efficiency, the purpose was to keep up a question response time of seconds to make sure a constructive expertise for end-users.
Monetary markets is a regulated business with excessive stakes concerned. Offering incorrect or outdated info can impression buyers’ and shareholders’ belief, along with different attainable information privateness dangers. Understanding the business and the necessities, This fall units information privateness and response accuracy as its guiding rules in evaluating any resolution earlier than it may be taken to market.
For the proof of idea, This fall determined to make use of a monetary possession dataset. The dataset consists of time collection information factors representing the variety of belongings owned; the transaction historical past between funding establishments, people, and public firms; and lots of extra parts.
As a result of This fall wished to make sure it might fulfill all of the practical and non-functional necessities we’ve mentioned, the undertaking additionally wanted to remain commercially possible. This was revered all through the method of deciding on the strategy, structure, alternative of know-how, and solution-specific parts.
Experimentation and challenges
It was clear from the start that to know a human language query and generate correct solutions, This fall would wish to make use of giant language fashions (LLMs).
The next are among the experiments that had been performed by the staff, together with the challenges recognized and classes realized:
- Pre-training – This fall understood the complexity and challenges that include pre-training an LLM utilizing its personal dataset. It shortly grew to become apparent that this strategy is useful resource intensive with many non-trivial steps, comparable to information preprocessing, coaching, and analysis. Along with the hassle concerned, it might be value prohibitive. Contemplating the character of the time collection dataset, This fall additionally realized that it must constantly carry out incremental pre-training as new information got here in. This is able to have required a devoted cross-disciplinary staff with experience in information science, machine studying, and area data.
- Fantastic-tuning – Fantastic-tuning a pre-trained basis mannequin (FM) concerned utilizing a number of labeled examples. This strategy confirmed some preliminary success, however in lots of circumstances, mannequin hallucination was a problem. The mannequin struggled to know nuanced contextual cues and returned incorrect outcomes.
- RAG with semantic search – Standard RAG with semantic search was the final step earlier than shifting to SQL era. The staff experimented with utilizing search, semantic search, and embeddings to extract context. Throughout the embeddings experiment, the dataset was transformed into embeddings, saved in a vector database, after which matched with the embeddings of the query to extract context. The retrieved context in any of the three experiments was then used to reinforce the unique immediate as an enter to the LLM. This strategy labored nicely for text-based content material, the place the info consists of pure language with phrases, sentences, and paragraphs. Contemplating the character of This fall’s dataset, which is generally monetary information consisting of numbers, monetary transactions, inventory quotes, and dates, the ends in all three circumstances had been suboptimal. Even when utilizing embeddings, the embeddings generated from numbers struggled with similarity rating, and in lots of circumstances led to retrieving incorrect info.
This fall’s conclusion: Producing SQL is the trail ahead
Contemplating the challenges confronted utilizing standard RAG methodology, the staff began to think about SQL era. The concept was to make use of the LLM to first generate a SQL assertion from the consumer query, offered to the LLM in pure language. The generated question is then run in opposition to the database to fetch the related context. The context is lastly used to reinforce the enter immediate for a summarization step.
This fall’s speculation was that with a purpose to get greater recall for the retrieval step, particularly for the numerical dataset, they wanted to first generate SQL from the consumer query. This was believed to not solely enhance accuracy, but additionally maintain the context throughout the enterprise area for a given query. For the question era, and to generate correct SQL, This fall wanted to make the LLM totally context conscious of their dataset construction. This meant the immediate wanted to incorporate the database schema, a number of pattern information rows, and human-readable discipline explanations for the fields that aren’t straightforward to understand.
Primarily based on the preliminary assessments, this methodology confirmed nice outcomes. The LLM outfitted with all the required info was capable of generate the proper SQL, which was then run in opposition to the database to retrieve the proper context. After experimenting with the thought, This fall determined that SQL era was the best way ahead to handle context extraction challenges for their very own particular dataset.
Let’s begin with describing the general resolution strategy, break it right down to its parts, after which put the items collectively.
Resolution overview
LLMs are giant fashions with billions of parameters which are pre-trained utilizing very giant quantities of information from quite a lot of sources. As a result of breadth of the coaching datasets, LLMs are anticipated to have normal data in quite a lot of domains. LLMs are additionally recognized for his or her reasoning skills, which fluctuate from one mannequin to a different. This normal habits could be optimized to a selected area or business by additional optimizing a basis mannequin utilizing further domain-specific pre-training information or by fine-tuning utilizing labeled information. Given the precise context, metadata, and directions, a well-selected normal goal LLM can produce good-quality SQL so long as it has entry to the precise domain-specific context.
In This fall’s use case, we begin with translating the client query into SQL. We do that by combining the consumer query, database schema, some pattern database rows, and detailed directions as a immediate to the LLM to generate SQL. After now we have the SQL, we will run a validation step if deemed vital. Once we’re proud of the standard of the SQL, we run the question in opposition to the database to retrieve the related context that we want for the next step. Now that now we have the related context, we will ship the consumer’s unique query, the context retrieved, and a set of directions again to the LLM to provide a ultimate summarized response. The purpose of the final step is to have the LLM summarize the outcomes and supply a contextual and correct reply that may be then handed alongside to the consumer.
The selection of LLM used at each stage of the method extremely impacts the accuracy, value, and efficiency. Selecting a platform or know-how that may enable you the flexibleness to change between LLMs throughout the identical use case (a number of LLM journeys for various duties), or throughout totally different use circumstances, could be useful in optimizing the standard of the output, latency, and value. We deal with the selection of LLM later on this submit.
Resolution constructing blocks
Now that now we have highlighted the strategy at a excessive degree, let’s dive into the main points, beginning with the answer constructing blocks.
Amazon Bedrock
Amazon Bedrock is a totally managed service that gives a alternative of high-performing FMs from main firms, together with AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. Amazon Bedrock additionally provides a broad set of instruments which are wanted to construct generative AI purposes, simplify the event course of, and keep privateness and safety. As well as, with Amazon Bedrock you possibly can select from numerous FM choices, and you may additional fine-tune the fashions privately utilizing your personal information to align fashions’ responses along with your use case necessities. Amazon Bedrock is totally serverless with no underlying infrastructure to handle extending entry to out there fashions by a single API. Lastly, Amazon Bedrock helps a number of safety and privateness necessities, together with HIPAA eligibility and GDPR compliance.
In This fall’s resolution, we use Amazon Bedrock as a serverless, API-based, multi-foundation mannequin constructing block. As a result of we intend to make a number of journeys to the LLM throughout the identical use case, based mostly on the duty sort, we will select the mannequin that’s most optimum for a selected activity, be it SQL era, validation, or summarization.
LangChain
LangChain is an open supply integration and orchestration framework with a set of pre-built modules (I/O, retrieval, chains, and brokers) that you should use to combine and orchestrate duties between FMs, information sources, and instruments. The framework facilitates constructing generative AI purposes that require orchestrating a number of steps to provide the specified output, with out having to jot down code from scratch. LangChain helps Amazon Bedrock as a multi-foundation mannequin API.
Particular to This fall’s use case, we use LangChain for coordinating and orchestrating duties in our workflow, together with connecting to information sources and LLMs. This strategy has simplified our code as a result of we will use the present LangChain modules.
SQLDatabaseChain
SQLDatabaseChain is a LangChain chain that may be imported from langchain_experimental. SLDatabaseChain makes it simple to create, implement, and run SQL queries, utilizing its efficient text-to-SQL conversions and implementations.
In our use case, we use SQLDatabaseChain within the SQL era, simplifying and orchestrating interactions between the database and the LLM.
The dataset
Our structured dataset can reside in a SQL database, information lake, or information warehouse so long as now we have assist for SQL. In our resolution, we will use any dataset sort with SQL assist; this ought to be abstracted from the answer and shouldn’t change the answer in any approach.
Implementation particulars
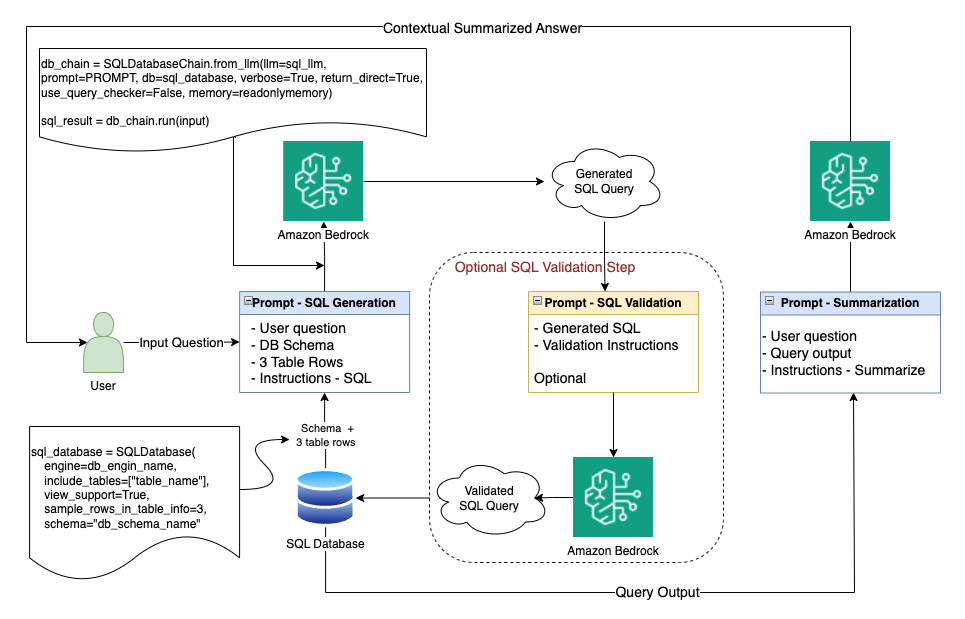
Now that now we have explored the answer strategy, resolution parts, the selection of know-how, and instruments, we will put the items collectively. The next diagram highlights the end-to-end resolution.

Let’s stroll by the implementation particulars and the method stream.
Generate the SQL question
To simplify coding, we use present frameworks. We use LangChain as an orchestration framework. We begin with the enter stage, the place we obtain the consumer query in pure language.
On this first stage, we take this enter and generate an equal SQL that we will run in opposition to the database for context extraction. To generate SQL, we use SQLDatabaseChain, which depends on Amazon Bedrock for entry to our desired LLM. With Amazon Bedrock, utilizing a single API, we get entry to a lot of underlying LLMs and might decide the precise one for every LLM journey we make. We first set up a connection to the database and retrieve the required desk schema together with some pattern rows from the tables we intend to make use of.
In our testing, we discovered 2–5 rows of desk information to be adequate to present sufficient info to the mannequin with out including an excessive amount of pointless overhead. Three rows had been simply sufficient to supply context, with out overwhelming the mannequin with an excessive amount of enter. In our use case, we began with Anthropic Claude V2. The mannequin is understood for its superior reasoning and articulate contextual responses when supplied with the precise context and directions. As a part of the directions, we will embody extra clarifying particulars to the LLM. For instance, we will describe that column Comp_NAME stands for the corporate title. We now can assemble the immediate by combining the consumer query as is, the database schema, three pattern rows from the desk we intend to make use of, and a set of directions to generate the required SQL in clear SQL format with out feedback or additions.
All of the enter parts mixed are thought-about because the mannequin enter immediate. A well-engineered enter immediate that’s tailor-made to the mannequin’s most well-liked syntax extremely impacts each the standard and efficiency of the output. The selection of mannequin to make use of for a selected activity can also be vital, not solely as a result of it impacts the output high quality, but additionally as a result of it has value and efficiency implications.
We talk about mannequin choice and immediate engineering and optimization later on this submit, but it surely’s value noting that for the question era stage, we seen that Claude Prompt was capable of produce comparable outcomes, particularly when the consumer query is nicely phrased and never as refined. Nevertheless, Claude V2 produced higher outcomes even with extra advanced and oblique consumer enter. We realized that though in some circumstances Claude Instant might present adequate accuracy at a greater latency and worth level, our case for question era was higher fitted to Claude V2.
Confirm the SQL question
Our subsequent step is to confirm that the LLM has efficiently generated the precise question syntax and that the question makes contextual sense contemplating the database schemas and the instance rows offered. For this verification step, we will revert to native question validation inside SQLDatabaseChain, or we will run a second journey to the LLM together with the question generated together with validation instruction.
If we use an LLM for the validation step, we will use the identical LLM as earlier than (Claude V2) or a smaller, extra performant LLM for a less complicated activity, comparable to Claude Prompt. As a result of we’re utilizing Amazon Bedrock, this ought to be a quite simple adjustment. Utilizing the identical API, we will change the mannequin title in our API name, which takes care of the change. It’s vital to notice that generally, a smaller LLM can present higher effectivity in each value and latency and ought to be thought-about—so long as you’re getting the accuracy desired. In our case, testing proved the question generated to be persistently correct and with the precise syntax. Figuring out that, we had been capable of skip this validation step and save on latency and value.
Run the SQL question
Now that now we have the verified SQL question, we will run the SQL question in opposition to the database and retrieve the related context. This ought to be an easy step.
We take the generated context, present it to the LLM of our alternative with the preliminary consumer query and a few instruction, and ask the mannequin to generate a contextual and articulate abstract. We then current the generated abstract to the consumer as a solution to the preliminary query, all aligned with the context extracted from our dataset.
For the LLM concerned within the summarization step, we will use both Titan Textual content Categorical or Claude Prompt. They’d each current good choices for the summarization activity.
Utility integration
The Q&A chatbot functionality is one in all This fall’s AI providers. To make sure modularity and scalability, This fall builds AI providers as microservices which are accessible to This fall purposes by APIs. This API-based strategy allows seamless integration with the This fall Platform ecosystem and facilitates exposing the AI providers’ capabilities to the complete suite of platform purposes.
The primary goal of the AI providers is to supply simple capabilities for retrieving information from any public or proprietary information supply utilizing pure language as enter. As well as, the AI providers present further layers of abstraction to make sure that practical and non-functional necessities, comparable to information privateness and safety are met. The next diagram demonstrates the combination idea.

Implementation challenges
Along with the challenges offered by the character of the structured, numerical dataset that we mentioned earlier, This fall was confronted with a lot of different implementation challenges that wanted to be addressed.
LLM choice and efficiency
Choosing the precise LLM for the duty is essential as a result of it instantly impacts the standard of output in addition to the efficiency (spherical journey latency). Listed below are some elements that play into the LLM choice course of:
- Sort of LLM – The best way the FMs are architected and the preliminary information the mannequin has been pre-trained on determines the sorts of duties the LLM could be good at and the way good will probably be. For instance, a textual content LLM could be good at textual content era and summarization, whereas a text-to-image or image-to-text mannequin could be extra geared in the direction of picture analytics and era duties.
- LLM dimension – FM sizes are measured by the variety of mannequin parameters a selected mannequin has, sometimes in billions for contemporary LLMs. Usually, the bigger the mannequin, the costlier to initially prepare or subsequently fine-tune. However, basically, for a similar mannequin structure, the bigger the mannequin is, the smarter we count on it to be in performing the kind of activity it’s geared in the direction of.
- LLM efficiency – Usually, the bigger the mannequin, the extra time it takes to generate output, assuming you’re utilizing the identical compute and I/O parameters (immediate and output dimension). As well as, for a similar mannequin dimension, efficiency is extremely impacted by how optimized your immediate is, the dimensions of the I/O tokens, and the readability and syntax of the immediate. A well-engineered immediate, together with an optimized I/O token dimension, can enhance the mannequin response time.
Due to this fact, when optimizing your activity, think about the next finest practices:
- Select a mannequin that’s appropriate for the duty at hand
- Choose the smallest mannequin dimension that may produce the accuracy you’re searching for
- Optimize your immediate construction and be as particular as attainable with the directions in a approach that’s straightforward for the mannequin to know
- Use the smallest enter immediate that may present sufficient instruction and context to provide the accuracy degree you’re searching for
- Restrict the output dimension to the smallest dimension that may be significant for you and fulfill your output necessities
Taking the mannequin choice and efficiency optimization elements into consideration, we went to work to optimize our SQL era use case. After some testing, we seen that, offered now we have the precise context and directions, Claude Prompt, with the identical immediate information, would produce comparable high quality of SQL as Claude V2 at a significantly better efficiency and worth level. This stands true when the consumer enter is extra direct and less complicated in nature. For extra refined enter, Claude V2 was vital to provide the specified accuracy.
Making use of the identical logic on the summarization activity led us to conclude that utilizing Claude Prompt or Titan Textual content Categorical would produce the accuracy required at a significantly better efficiency level than if we use a bigger mannequin comparable to Claude V2. Titan Textual content Expressed additionally provided higher price-performance, as we mentioned earlier.
The orchestration problem
We realized that there’s a lot to orchestrate earlier than we will get a significant output response for the consumer query. As proven within the resolution overview, the method concerned a number of database journeys and a number of LLM journeys which are intertwined. If we had been to construct from scratch, we’d have needed to make a big funding within the undifferentiated heavy lifting simply to get the essential code prepared. We shortly pivoted to utilizing LangChain as an orchestration framework, profiting from the ability of the open supply neighborhood, and reusing present modules with out reinventing the wheel.
The SQL problem
We additionally realized that producing SQL isn’t so simple as context extraction mechanisms like semantic search or utilizing embeddings. We have to first get the database schema and some pattern rows to incorporate in our immediate to the LLM. There may be additionally the SQL validation stage, the place we wanted to work together with each the database and the LLM. SQLDatabaseChain was the apparent alternative of device. As a result of it’s a part of LangChain, it was simple to adapt, and now we will handle the SQL era and verification assisted with the chain, minimizing the quantity of labor we wanted to do.
Efficiency challenges
With the usage of Claude V2, and after correct immediate engineering (which we talk about within the subsequent part), we had been capable of produce high-quality SQL. Contemplating the standard of the SQL generated, we began to take a look at how a lot worth the validation stage is definitely including. After additional analyzing the outcomes, it grew to become clear that the standard of the SQL generated was persistently correct in a approach that made the price/good thing about including an SQL validation stage unfavorable. We ended up eliminating the SQL validation stage with out negatively impacting the standard of our output and shaved off the SQL validation spherical journey time.
Along with optimizing for a extra cost- and performance-efficient LLM for the summarization step, we had been in a position to make use of Titan Textual content Categorical to get higher efficiency and cost-efficiency.
Additional efficiency optimization concerned fine-tuning the question era course of utilizing environment friendly immediate engineering strategies. Quite than offering an abundance of tokens, the main focus was on offering the least quantity of enter tokens, in the precise syntax that the mannequin is educated to know, and with the minimal but optimum set of directions. We talk about this extra within the subsequent part—it’s an vital subject that’s relevant not solely right here but additionally in different use circumstances.
Immediate engineering and optimization
You possibly can modify Claude on Amazon Bedrock for numerous enterprise use circumstances if the precise immediate engineering strategies are employed. Claude primarily acts as a conversational assistant that makes use of a human/assistant format. Claude is educated to fill in textual content for the assistant position. Given the directions and immediate completions desired, we will optimize our prompts for Claude utilizing a number of strategies.
We begin with a correct formatted immediate template that provides a legitimate completion, then we will additional optimize the responses experimenting with prompting with numerous units of inputs which are consultant of real-world information. It’s beneficial to get many inputs whereas creating a immediate template. You can even use separate units of immediate growth information and take a look at information.
One other approach to optimize the Claude response is to experiment and iterate by including guidelines, directions, and useful optimizations. From these optimizations, you possibly can view various kinds of completions by, for instance, telling Claude to say “I don’t know” to stop hallucinations, pondering step-by-step, utilizing immediate chaining, giving room to “suppose” because it generates responses, and double-checking for comprehension and accuracy.
Let’s use our question era activity and talk about among the strategies we used to optimize our immediate. There have been a number of core parts that benefited our question era efforts:
- Utilizing the correct human/assistant syntax
- Using XML tags (Claude respects and understands XML tags)
- Including clear directions for the mannequin to stop hallucination
The next generic instance reveals how we used the human/assistant syntax, utilized XML tags, and added directions to limit the output to SQL and instruct the mannequin to say “sorry, I’m unable to assist” if it could possibly’t produce related SQL. The XML tags had been used to border the directions, further hints, database schema, further desk explanations, and instance rows.
The ultimate working resolution
After we had addressed all of the challenges recognized in the course of the proof of idea, we had fulfilled all the answer necessities. This fall was happy with the standard of the SQL generated by the LLM. This stands true for easy duties that required solely a WHERE clause to filter the info, and in addition with extra advanced duties that required context-based aggregations with GROUP BY and mathematical features. The top-to-end latency of the general resolution got here inside what was outlined as acceptable for the use case—single-digit seconds. This was all due to the selection of an optimum LLM at each stage, correct immediate engineering, eliminating the SQL verification step, and utilizing an environment friendly LLM for the summarization step (Titan Textual content Categorical or Claude Prompt).
It’s value noting that utilizing Amazon Bedrock as a totally managed service and the flexibility to have entry to a collection of LLMs by the identical API allowed for experimentation and seamless switching between LLMs by altering the mannequin title within the API name. With this degree of flexibility, This fall was in a position to decide on probably the most performant LLM for every LLM name based mostly on the character of the duty, be it question era, verification, or summarization.
Conclusion
There isn’t a one resolution that matches all use circumstances. In a RAG strategy, the standard of the output extremely depends upon offering the precise context. Extracting the precise context is essential, and each dataset is totally different with its distinctive traits.
On this submit, we demonstrated that for numerical and structured datasets, utilizing SQL to extract the context used for augmentation can result in extra favorable outcomes. We additionally demonstrated that frameworks like LangChain can reduce the coding effort. Moreover, we mentioned the necessity to have the ability to swap between LLMs throughout the identical use case with a purpose to obtain probably the most optimum accuracy, efficiency, and value. Lastly, we highlighted how Amazon Bedrock, being serverless and with quite a lot of LLMs beneath the hood, supplies the flexibleness wanted to construct safe, performant, and cost-optimized purposes with the least quantity of heavy lifting.
Begin your journey in the direction of constructing generative AI-enabled purposes by figuring out a use case of worth to your small business. SQL era, because the This fall staff realized, is usually a sport changer in constructing good purposes that combine along with your information shops, unlocking income potential.
Concerning the authors
 Tamer Soliman is a Senior Options Architect at AWS. He helps Unbiased Software program Vendor (ISV) prospects innovate, construct, and scale on AWS. He has over twenty years of business expertise in consulting, coaching, {and professional} providers. He’s a multi patent inventor with three granted patents and his expertise spans a number of know-how domains together with telecom, networking, utility integration, AI/ML, and cloud deployments. He focuses on AWS Networking and has a profound ardour for machine leaning, AI, and Generative AI.
Tamer Soliman is a Senior Options Architect at AWS. He helps Unbiased Software program Vendor (ISV) prospects innovate, construct, and scale on AWS. He has over twenty years of business expertise in consulting, coaching, {and professional} providers. He’s a multi patent inventor with three granted patents and his expertise spans a number of know-how domains together with telecom, networking, utility integration, AI/ML, and cloud deployments. He focuses on AWS Networking and has a profound ardour for machine leaning, AI, and Generative AI.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the ebook – Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Training Basis Board. She leads machine studying (ML) initiatives in numerous domains comparable to pc imaginative and prescient, pure language processing and generative AI. She helps prospects to construct, prepare and deploy giant machine studying fashions at scale. She speaks in inside and exterior conferences such re:Invent, Ladies in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the ebook – Utilized Machine Studying and Excessive Efficiency Computing on AWS, and a member of the Board of Administrators for Ladies in Manufacturing Training Basis Board. She leads machine studying (ML) initiatives in numerous domains comparable to pc imaginative and prescient, pure language processing and generative AI. She helps prospects to construct, prepare and deploy giant machine studying fashions at scale. She speaks in inside and exterior conferences such re:Invent, Ladies in Manufacturing West, YouTube webinars and GHC 23. In her free time, she likes to go for lengthy runs alongside the seashore.
 Stanislav Yeshchenko is a Software program Architect at This fall Inc.. He has over a decade of business expertise in software program growth and system structure. His various background spanning roles comparable to Technical Lead and Senior Full Stack Developer, powers his contributions to advancing innovation of the This fall Platform. Stanislav is devoted to driving technical innovation and shaping strategic options within the discipline.
Stanislav Yeshchenko is a Software program Architect at This fall Inc.. He has over a decade of business expertise in software program growth and system structure. His various background spanning roles comparable to Technical Lead and Senior Full Stack Developer, powers his contributions to advancing innovation of the This fall Platform. Stanislav is devoted to driving technical innovation and shaping strategic options within the discipline.