Use customized metadata created by Amazon Comprehend to intelligently course of insurance coverage claims utilizing Amazon Kendra
Structured information, outlined as information following a set sample akin to info saved in columns inside databases, and unstructured information, which lacks a particular kind or sample like textual content, photos, or social media posts, each proceed to develop as they’re produced and consumed by varied organizations. As an example, in response to Worldwide Knowledge Company (IDC), the world’s information quantity is predicted to extend tenfold by 2025, with unstructured information accounting for a good portion. Enterprises could need to add customized metadata like doc varieties (W-2 varieties or paystubs), varied entity varieties akin to names, group, and deal with, along with the usual metadata like file sort, date created, or measurement to increase the clever search whereas ingesting the paperwork. The customized metadata helps organizations and enterprises categorize info of their most well-liked method. For instance, metadata can be utilized for filtering and looking out. Clients can create the customized metadata utilizing Amazon Comprehend, a natural-language processing (NLP) service managed by AWS to extract insights concerning the content material of paperwork, and ingest it into Amazon Kendra together with their information into the index. Amazon Kendra is a extremely correct and easy-to-use enterprise search service powered by Machine Studying (AWS). The customized metadata can then be used to complement the content material for higher filtering and facet capabilities. In Amazon Kendra, aspects are scoped views of a set of search outcomes. For instance, you possibly can present search outcomes for cities the world over, the place paperwork are filtered by a particular metropolis with which they’re related. You may additionally create aspects to show outcomes by a particular creator.
Insurance coverage firms are burdened with growing numbers of claims that they need to course of. Moreover, the complexity of claims processing can also be growing as a result of various sorts of insurance coverage paperwork concerned, and customized entities in every of those paperwork. On this put up, we describe a use case for customized content material enrichment for insurance coverage suppliers. The insurance coverage supplier receives payout claims from the beneficiary’s legal professional for various insurance coverage varieties, akin to house, auto, and life insurance coverage. On this use case, the paperwork obtained by the insurance coverage supplier don’t comprise any metadata that permits looking out the content material based mostly on sure entities and courses. The insurance coverage supplier desires to filter Kendra content material based mostly on customized entities and courses particular to their enterprise area. This put up illustrates how one can automate and simplify metadata era utilizing customized fashions by Amazon Comprehend. The metadata generated may be custom-made through the ingestion course of with Amazon Kendra Custom Document Enrichment (CDE) customized logic.
Let’s take a look at a number of examples of Amazon Kendra search with or with out filtering and aspects capabilities.
Within the following screenshot, Amazon Kendra gives a search end result however there isn’t a choice to additional slender down the search outcomes by utilizing any filters.

The next screenshot reveals Amazon Kendra search outcomes may be filtered by utilizing totally different aspects like Regulation Agency, Coverage Numbers, created by customized metadata to slender down the search outcomes.

The answer mentioned on this put up can simply be utilized to different companies/use-cases as properly, akin to healthcare, manufacturing, and analysis.
Resolution overview
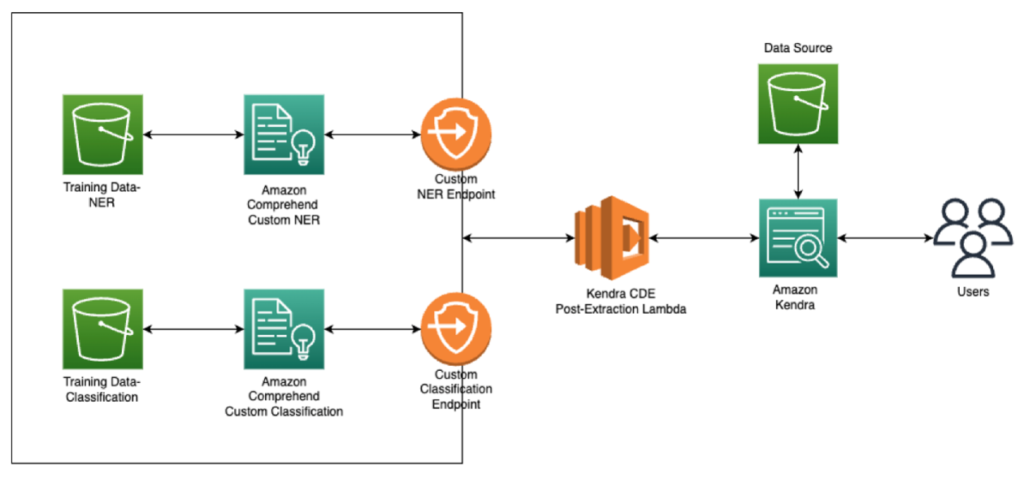
On this proposed resolution, we are going to 1) classify insurance coverage claims submissions into varied courses, and a pair of) retrieve insurance-specific entities from these paperwork. When that is full, the doc may be routed to the suitable division or downstream course of.
The next diagram outlines the proposed resolution structure.

Amazon Comprehend custom classification API is used to arrange your paperwork into classes (courses) that you simply outline. Customized classification is a two-step course of. First, you practice a customized classification mannequin (additionally referred to as a classifier) to acknowledge the courses which might be of curiosity to you. Then, you utilize your mannequin to categorise any variety of doc units.
Amazon Comprehend custom entity recognition characteristic is used to establish particular entity varieties (names of insurance coverage firm, names of the insurer, coverage quantity) past what is obtainable within the generic entity types by default. Constructing a customized entity recognition mannequin is a more practical method than utilizing string matching or common expressions to extract entities from paperwork. A customized entity recognition mannequin can study the context the place these names are more likely to seem. Moreover, string matching is not going to detect entities which have typos or observe new naming conventions, whereas that is doable utilizing a customized mannequin.
Earlier than diving deeper, let’s take a second to discover Amazon Kendra. Amazon Kendra is a extremely correct and easy-to-use enterprise search service powered by machine studying. It permits customers to search out the knowledge they want throughout the huge quantity of content material unfold throughout their group, starting from web sites and databases to intranet websites. We’ll first create an Amazon Kendra index to ingest the paperwork. Whereas ingesting the info, it’s important to think about the idea of Customized Knowledge Enrichment (CDE). CDE lets you improve the search functionality by incorporating exterior data into the search index. For extra info, seek advice from Enriching your documents during ingestion. On this put up, the CDE logic invokes the customized APIs of Amazon Comprehend to complement the paperwork with recognized courses and entities. Lastly, we use the Amazon Kendra search web page to point out how the metadata enhanced the search functionality by including faceting and filtering capabilities.
The high-level steps to implement this resolution are as follows:
- Prepare the Amazon Comprehend customized classifier utilizing coaching information
- Prepare the Amazon Comprehend customized entity recognition utilizing coaching information
- Create the Amazon Comprehend customized classifier and customized entity recognition endpoints
- Create and deploy a Lambda operate for put up extraction enrichment
- Create and populate the Amazon Kendra index
- Use the extracted entities to filter searches in Amazon Kendra
Now we have additionally supplied a pattern software within the GitHub repo for reference.
Knowledge safety and IAM concerns
With safety as the highest precedence, this resolution follows the least privilege permissions precept for the providers and options used. The IAM position utilized by Amazon Comprehend customized classification and customized entity recognition has permissions to entry the dataset from the check bucket solely. The Amazon Kendra service has entry to a particular S3 bucket and Lambda operate used to name comprehend APIs. The Lambda operate has permissions to name the Amazon Comprehend APIs solely. For extra info, evaluate part 1.2 and 1.3 within the pocket book.
We advocate you do the next in a non-production atmosphere previous to implementing the answer within the manufacturing atmosphere.
Prepare the Comprehend customized classifier utilizing coaching information
Amazon Comprehend Customized Classification helps two information format varieties for annotation information:
Since our information is already labeled and saved in CSV information, we are going to use the CSV file format for the annotation file for instance. Now we have to supply the labeled coaching information as UTF-8 encoded textual content in a CSV file. Don’t embrace a header row within the CSV file. Including a header row in your file could trigger runtime errors. An instance to the coaching information CSV file is as follows:
To organize classifier coaching information, seek advice from Preparing classifier training data. For every row within the CSV file, the primary column comprises a number of class labels. A category label may be any legitimate UTF-8 string. We advocate utilizing clear class names that don’t overlap in that means. The title can embrace white house, and may include a number of phrases linked by underscores or hyphens. Don’t depart any house characters earlier than or after the commas that separate the values in a row.
Subsequent, you’ll practice both utilizing Multi-class mode or Multi-label mode. Particularly, in multi-class mode, classification assigns one class for every doc, whereas in multi-label mode, particular person courses characterize totally different classes that aren’t mutually unique. In our case we can be utilizing the Multi-Class mode for Plain-text fashions.
You’ll be able to put together separate coaching and testing datasets for Amazon Comprehend customized classifier coaching and mannequin analysis. Or, solely present one dataset for each coaching and testing. Comprehend will routinely choose 10% of your supplied dataset to make use of as testing information. On this instance, we’re offering separate coaching and testing datasets.
The next instance reveals a CSV file containing the category names related to the assorted paperwork.

Doc format – Kind of Insurance coverage, Content material of doc 1
When the customized classification mannequin is educated, it could possibly seize totally different courses of insurance coverage on the paperwork (House, Auto, or Life insurance coverage).
Prepare the Amazon Comprehend customized entity recognizer (NER) utilizing coaching information
The coaching dataset for Amazon Comprehend Customized Entity Recognition (NER) may be ready in one among two other ways:
- Annotations – Offers an information set that comprises the annotated entities for mode coaching
- Entity lists (plain textual content solely) – Offers an inventory of entities and their label sort (akin to “Insurance coverage firm names”) and a set of unannotated paperwork containing these entities for mannequin coaching
For extra info, seek advice from Preparing entity recognizer training data.
When coaching a mannequin utilizing entity listing, we have to present two items of knowledge: an inventory of entity names with their related customized entity varieties and a set of unannotated paperwork through which the entities seem.
Automated coaching requires having two sorts of info: pattern paperwork and the entity listing or annotations. As soon as the recognizer is educated, you should use it to detect customized entities in your paperwork. You’ll be able to shortly analyze a small physique of textual content in actual time, or you possibly can analyze a big set of paperwork with an asynchronous job.
You’ll be able to put together separate coaching and testing datasets for Amazon Comprehend customized entity recognizer coaching and mannequin analysis. Or present just one dataset for each coaching and testing. Amazon Comprehend will routinely choose 10% of your supplied dataset to make use of as testing information. Within the under instance, we specified the coaching dataset as Paperwork.S3Uri below InputDataConfig.
The next instance reveals a CSV file containing the of entities:

As soon as the customized entities (NER) mannequin is educated, it will likely be in a position to extract the assorted entities like “PAYOUT“, “INSURANCE_COMPANY“, “LAW_FIRM“, “POLICY_HOLDER_NAME“, “POLICY_NUMBER“.
Create the Amazon Comprehend customized classifier and customized entities (NER) endpoints
Amazon Comprehend’s endpoints make your customized fashions obtainable for real-time classification. After you create an endpoint, you may make modifications to it as your small business wants evolve. For instance, you possibly can monitor your endpoint utilization and apply auto scaling to routinely set endpoint provisioning to suit your capability wants. You’ll be able to handle all of your endpoints from a single view, and if you now not want an endpoint, you possibly can delete it to avoid wasting prices. Amazon Comprehend assist each synchronous and asynchronous choices, if real-time classification isn’t required to your use case, you possibly can submit a batch job to Amazon Comprehend for asynchronous information classification.
For this use case, you create an endpoint to make your customized mannequin obtainable for real-time evaluation.
To fulfill your textual content processing wants, you assign inference items to the endpoint, and every unit permits a throughput of 100 characters per second. You’ll be able to then modify the throughput up or down.
Create and deploy a Lambda operate for put up extraction enrichment
The post-extraction Lambda operate lets you implement the logic to course of the textual content extracted by Amazon Kendra from the ingested doc. The post-extraction operate we configured implements the code to invoke Amazon Comprehend to detect customized entities and customized classifying the paperwork from the textual content extracted by Amazon Kendra, and makes use of them to replace the doc metadata, which is introduced as aspects in an Amazon Kendra search. The operate code is embedded within the pocket book. The PostExtractionLambda code works as follows:
- Splits the web page textual content into sections that don’t exceed the max byte size restrict of the comprehend
detect_entitiesAPI. (See Limits ).
NOTE the script makes use of a naive character size splitting algorithm for simplicity – manufacturing use instances ought to implement overlapping or sentence boundary splits, based mostly on UTF8 byte size. - For every part of the textual content, calls the comprehend real-time endpoints for customized entities and customized classifier to detect the next entity varieties: [“
PAYOUT“, “INSURANCE_COMPANY“, “LAW_FIRM“, “POLICY_HOLDER_NAME“, “POLICY_NUMBER“, “INSURANCE_TYPE“]. - Filters out detected entities which might be under the arrogance rating threshold. We’re utilizing 0.50 threshold which implies solely entities with confidence 50% and extra can be used. This may be tuned based mostly on the use case and necessities.
- Tracks the frequency rely of every entity.
- Selects solely the highest N (10) distinctive entities for every web page, based mostly on frequency of prevalence.
- For doc classification, the multi-class classifier assigns just one class for every doc. On this Lambda operate, the paperwork can be labeled as Auto Insurance coverage, House Insurance coverage, or Life Insurance coverage.
Observe that as of this writing, CDE solely helps synchronous calls or if it needs to be asynchronous, then an specific wait loop is required. For put up extraction Lambda the max execution time is 1 min. The Lambda customized logic may be modified based mostly on the necessities that suit your use case.
Create and populate the Amazon Kendra index
On this step, we are going to ingest the info to the Amazon Kendra index and make it searchable for the customers. Through the ingestion, we are going to use the Lambda operate created within the earlier step as a put up extraction step and the Lambda operate will name the customized classification and customized entity recognition (NER) endpoints to create the customized metadata fields.
The high-level steps to implement this resolution are as follows:
- Create Amazon Kendra Index.
- Create Amazon Kendra Data source – There are totally different information sources which can be utilized to ingest dataset. On this put up we’re utilizing an S3 bucket.
- Create Aspects
Law_Firm,Payout,Insurance_Company,Policy_Number,Policy_Holder_Name,Insurance_Typewith string sort as ‘STRING_LIST_VALUE’. - Create Kendra CDE and level it to the post-extraction Lambda operate beforehand created.
- Carry out the sync course of to ingest the dataset.
As soon as accomplished, you possibly can populate the index with the insurance coverage information, utilizing the Kendra CDE with put up extraction lambda, you possibly can filter searches based mostly on the customized entity varieties and customized classification as customized metadata fields.
Use the extracted entities to filter searches in Kendra
Now the index is populated and able to use. Within the Amazon Kendra console, select Search Listed Content material below Knowledge Administration and do the next.
Question the next: Checklist of insurance coverage failed as a result of late submitting?

The outcomes present a solution from the coverage sort – HOME INSURANCE and brings text_18 and text_14 as the highest outcomes.
Select “Filter search outcomes” on the left. Now you will note all of the Entity varieties and classification values extracted utilizing Comprehend, and for every entity worth and classification you will note the variety of matching paperwork.

Beneath INSURANCE_TYPE select “Auto-Insurance coverage”, after which you’re going to get a solution from text_25 file.
Observe that your outcomes could range barely from the outcomes proven within the screenshot.
Strive looking out with your individual queries, and observe how the entities and doc classification recognized by Amazon Comprehend shortly lets you:
- See how your search outcomes are distributed throughout the classes.
- Slim your search by filtering on any of the entity/classification values.
Clear up
After you may have experimented with the search and tried the pocket book supplied within the Github repository, delete the infrastructure you provisioned in your AWS account to keep away from any undesirable expenses. You’ll be able to run the cleanup cells within the pocket book. Alternatively, you possibly can delete the assets manually via the AWS console:
- Amazon Kendra Index
- Comprehend customized classifier and customized entity recognition (NER) endpoints
- Comprehend customized classifier and customized entity recognition (NER) customized fashions
- Lambda operate
- S3 bucket
- IAM roles and insurance policies
Conclusion
On this put up, we confirmed how Amazon Comprehend customized entities and customized classifier permits Amazon Kendra search powered by CDE characteristic to assist end-users carry out higher searches on the structured/unstructured information. The customized entities of Amazon Comprehend and customized classifier makes it very helpful for various use instances and varied area particular information. For extra details about methods to use Amazon Comprehend, seek advice from Amazon Comprehend developer resources and for Amazon Kendra, seek advice from Amazon Kendra developer resources.
Give this resolution a strive to your use case. We invite you to go away your suggestions within the feedback sections.
Concerning the Authors
 Amit Chaudhary is a Senior Options Architect at Amazon Internet Providers. His focus space is AI/ML, and he helps clients with generative AI, massive language fashions, and immediate engineering. Exterior of labor, Amit enjoys spending time together with his household.
Amit Chaudhary is a Senior Options Architect at Amazon Internet Providers. His focus space is AI/ML, and he helps clients with generative AI, massive language fashions, and immediate engineering. Exterior of labor, Amit enjoys spending time together with his household.
 Yanyan Zhang is a Senior Knowledge Scientist within the Vitality Supply group with AWS Skilled Providers. She is keen about serving to clients remedy actual issues with AI/ML data. Not too long ago, her focus has been on exploring the potential of Generative AI and LLM. Exterior of labor, she loves touring, understanding and exploring new issues.
Yanyan Zhang is a Senior Knowledge Scientist within the Vitality Supply group with AWS Skilled Providers. She is keen about serving to clients remedy actual issues with AI/ML data. Not too long ago, her focus has been on exploring the potential of Generative AI and LLM. Exterior of labor, she loves touring, understanding and exploring new issues.
 Nikhil Jha is a Senior Technical Account Supervisor at Amazon Internet Providers. His focus areas embrace AI/ML, and analytics. In his spare time, he enjoys enjoying badminton together with his daughter and exploring the outside.
Nikhil Jha is a Senior Technical Account Supervisor at Amazon Internet Providers. His focus areas embrace AI/ML, and analytics. In his spare time, he enjoys enjoying badminton together with his daughter and exploring the outside.





