Abstract report optimization within the Privateness Sandbox Attribution Reporting API – Google Analysis Weblog

In recent times, the Privacy Sandbox initiative was launched to discover accountable methods for advertisers to measure the effectiveness of their campaigns, by aiming to deprecate third-party cookies (topic to resolving any competition concerns with the UK’s Competition and Markets Authority). Cookies are small items of knowledge containing person preferences that web sites retailer on a person’s system; they can be utilized to supply a greater shopping expertise (e.g., permitting customers to mechanically sign up) and to serve related content material or advertisements. The Privateness Sandbox makes an attempt to handle considerations round using cookies for monitoring shopping knowledge throughout the net by offering a privacy-preserving different.
Many browsers use differential privacy (DP) to supply privacy-preserving APIs, such because the Attribution Reporting API (ARA), that don’t depend on cookies for advert conversion measurement. ARA encrypts particular person person actions and collects them in an aggregated summary report, which estimates measurement targets just like the quantity and worth of conversions (helpful actions on an internet site, reminiscent of making a purchase order or signing up for a mailing record) attributed to advert campaigns.
The duty of configuring API parameters, e.g., allocating a contribution funds throughout totally different conversions, is vital for maximizing the utility of the abstract experiences. In “Summary Report Optimization in the Privacy Sandbox Attribution Reporting API”, we introduce a proper mathematical framework for modeling abstract experiences. Then, we formulate the issue of maximizing the utility of abstract experiences as an optimization drawback to acquire the optimum ARA parameters. Lastly, we consider the tactic utilizing actual and artificial datasets, and display considerably improved utility in comparison with baseline non-optimized abstract experiences.
ARA abstract experiences
We use the next instance for instance our notation. Think about a fictional reward store known as Du & Penc that makes use of digital promoting to succeed in its prospects. The desk under captures their vacation gross sales, the place every document accommodates impression options with (i) an impression ID, (ii) the marketing campaign, and (iii) town through which the advert was proven, in addition to conversion options with (i) the variety of gadgets bought and (ii) the entire greenback worth of these gadgets.
 |
| Impression and conversion characteristic logs for Du & Penc. |
Mathematical mannequin
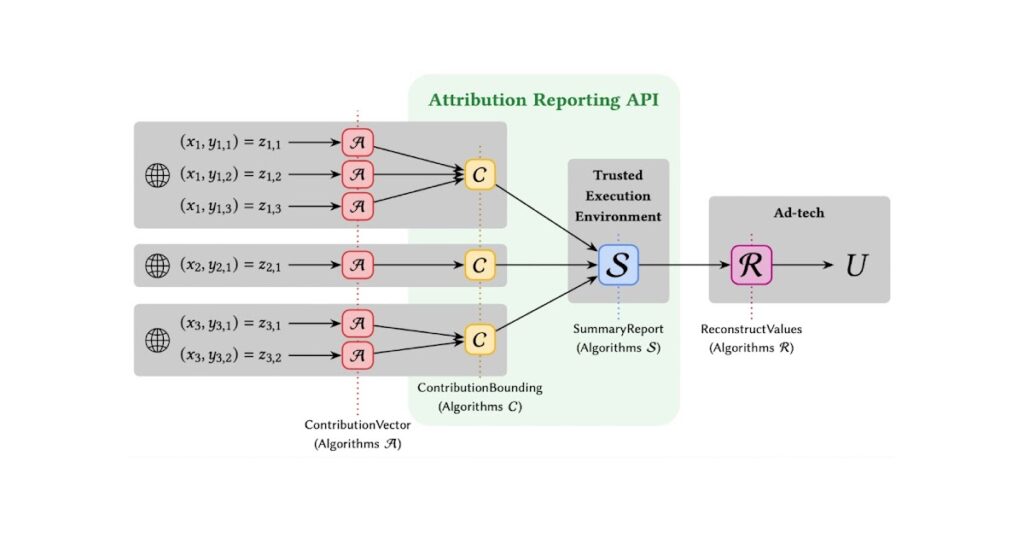
ARA abstract experiences will be modeled by 4 algorithms: (1) Contribution Vector, (2) Contribution Bounding, (3) Summary Reports, and (4) Reconstruct Values. Contribution Bounding and Abstract Experiences are carried out by the ARA, whereas Contribution Vector and Reconstruct Values are carried out by an AdTech supplier — instruments and programs that allow companies to purchase and promote digital promoting. The target of this work is to help AdTechs in optimizing abstract report algorithms.
The Contribution Vector algorithm converts measurements into an ARA format that’s discretized and scaled. Scaling must account for the general contribution restrict per impression. Right here we suggest a technique that clips and performs randomized rounding. The end result of the algorithm is a histogram of aggregatable keys and values.
Subsequent, the Contribution Bounding algorithm runs on consumer gadgets and enforces the contribution sure on attributed experiences the place any additional contributions exceeding the restrict are dropped. The output is a histogram of attributed conversions.
The Abstract Experiences algorithm runs on the server facet inside a trusted execution environment and returns noisy combination outcomes that fulfill DP. Noise is sampled from the discrete Laplace distribution, and to implement privateness budgeting, a report could also be queried solely as soon as.
Lastly, the Reconstruct Values algorithm converts measurements again to the unique scale. Reconstruct Values and Contribution Vector Algorithms are designed by the AdTech, and each influence the utility obtained from the abstract report.
 |
| Illustrative utilization of ARA abstract experiences, which embrace Contribution Vector (Algorithm A), Contribution Bounding (Algorithm C), Abstract Experiences (Algorithm S), and Reconstruct Values (Algorithm R). Algorithms C and S are mounted within the API. The AdTech designs A and R. |
Error metrics
There are a number of elements to contemplate when choosing an error metric for evaluating the standard of an approximation. To decide on a specific metric, we thought of the fascinating properties of an error metric that additional can be utilized as an goal perform. Contemplating desired properties, we now have chosen -truncated root mean square relative error (RMSRE) as our error metric for its properties. See the paper for an in depth dialogue and comparability to different attainable metrics.
Optimization
To optimize utility as measured by RMSRE, we select a capping parameter, C, and privateness funds, , for every slice. The mix of each determines how an precise measurement (reminiscent of two conversions with a complete worth of $3) is encoded on the AdTech facet after which handed to the ARA for Contribution Bounding algorithm processing. RMSRE will be computed precisely, since it may be expressed by way of the bias from clipping and the variance of the noise distribution. Following these steps we discover out that RMSRE for a set privateness funds, , or a capping parameter, C, is convex (so the error-minimizing worth for the opposite parameter will be obtained effectively), whereas for joint variables (C, ) it turns into non-convex (so we could not at all times be capable to choose the absolute best parameters). In any case, any off-the-shelf optimizer can be utilized to pick out privateness budgets and capping parameters. In our experiments, we use the SLSQP minimizer from the scipy.optimize library.
Artificial knowledge
Completely different ARA configurations will be evaluated empirically by testing them on a conversion dataset. Nevertheless, entry to such knowledge will be restricted or sluggish because of privateness considerations, or just unavailable. One solution to handle these limitations is to make use of artificial knowledge that replicates the traits of actual knowledge.
We current a technique for producing artificial knowledge responsibly by means of statistical modeling of real-world conversion datasets. We first carry out an empirical evaluation of actual conversion datasets to uncover related traits for ARA. We then design a pipeline that makes use of this distribution data to create a practical artificial dataset that may be custom-made by way of enter parameters.
The pipeline first generates impressions drawn from a power-law distribution (step 1), then for every impression it generates conversions drawn from a Poisson distribution (step 2) and at last, for every conversion, it generates conversion values drawn from a log-normal distribution (step 3). With dataset-dependent parameters, we discover that these distributions intently match ad-dataset traits. Thus, one can study parameters from historic or public datasets and generate artificial datasets for experimentation.
 |
| General dataset technology steps with options for illustration. |
Experimental analysis
We consider our algorithms on three real-world datasets (Criteo, AdTech Actual Property, and AdTech Journey) and three artificial datasets. Criteo consists of 15M clicks, Actual Property consists of 100K conversions, and Journey consists of 30K conversions. Every dataset is partitioned right into a coaching set and a check set. The coaching set is used to decide on contribution budgets, clipping threshold parameters, and the conversion rely restrict (the real-world datasets have just one conversion per click on), and the error is evaluated on the check set. Every dataset is partitioned into slices utilizing impression options. For real-world datasets, we take into account three queries for every slice; for artificial datasets, we take into account two queries for every slice.
For every question we select the RMSRE worth to be 5 instances the median worth of the question on the coaching dataset. This ensures invariance of the error metric to knowledge rescaling, and permits us to mix the errors from options of various scales by utilizing per every characteristic.
 |
| Scatter plots of real-world datasets illustrating the likelihood of observing a conversion worth. The fitted curves signify finest log-normal distribution fashions that successfully seize the underlying patterns within the knowledge. |
Outcomes
We examine our optimization-based algorithm to a easy baseline method. For every question, the baseline makes use of an equal contribution funds and a set quantile of the coaching knowledge to decide on the clipping threshold. Our algorithms produce considerably decrease error than baselines on each real-world and artificial datasets. Our optimization-based method adapts to the privateness funds and knowledge.
 |
| RMSREτ for privateness budgets {1, 2, 4, 8, 16, 32, 64} for our algorithms and baselines on three real-world and three artificial datasets. Our optimization-based method constantly achieves decrease error than baselines that use a set quantile for the clipping threshold and cut up the contribution funds equally among the many queries. |
Conclusion
We examine the optimization of abstract experiences within the ARA, which is at the moment deployed on lots of of thousands and thousands of Chrome browsers. We current a rigorous formulation of the contribution budgeting optimization drawback for ARA with the purpose of equipping researchers with a strong abstraction that facilitates sensible enhancements.
Our recipe, which leverages historic knowledge to sure and scale the contributions of future knowledge beneath differential privateness, is kind of common and relevant to settings past promoting. One method based mostly on this work is to make use of previous knowledge to study the parameters of the information distribution, after which to use artificial knowledge derived from this distribution for privateness budgeting for queries on future knowledge. Please see the paper and accompanying code for detailed algorithms and proofs.
Acknowledgements
This work was achieved in collaboration with Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, and Avinash Varadarajan. We thank Akash Nadan for his assist.





