Researchers from UC Berkeley and SJTU China Introduce the Idea of a ‘Rephrased Pattern’ for Rethinking Benchmark and Contamination for Language Fashions
Massive language fashions have gotten more and more advanced, making analysis harder. The group has produced many benchmarks in a comparatively brief period of time, however benchmark scores don’t at all times correspond to precise efficiency. Some proof means that many in style benchmarks might have tainted datasets used for fine-tuning and pre-training.
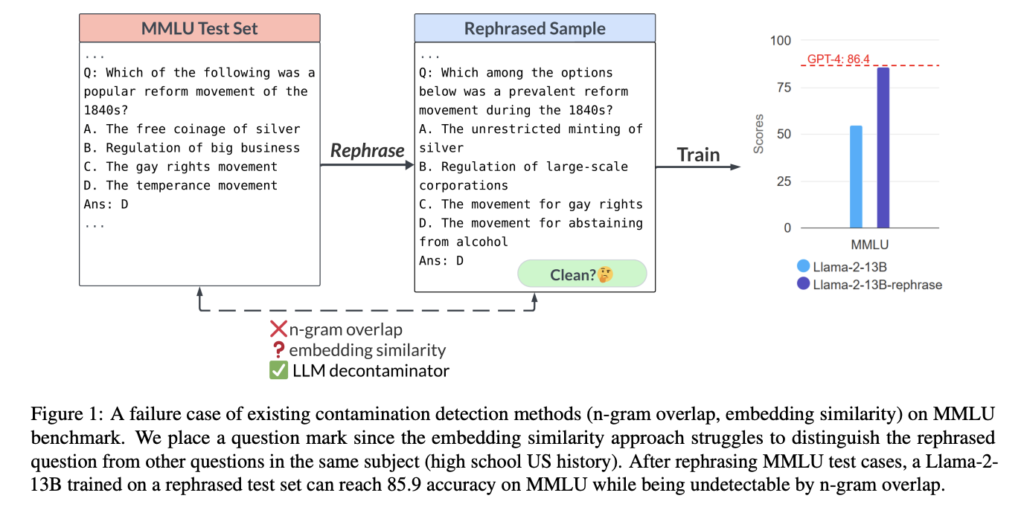
Regardless of widespread settlement that it’s an vital problem, pinpointing the supply of air pollution has been tough. Each n-gram overlap and embedding similarity search are broadly employed. String matching is used extensively by state-of-the-art improvements like GPT-4, PaLM, and Llama for N-gram overlap contamination detection. Nonetheless, its precision is considerably low. An embedding similarity search appears on the embeddings of beforehand skilled fashions (like BERT) to find associated and perhaps polluted circumstances. Nonetheless, discovering the candy spot between recall and precision when deciding on a similarity degree is perhaps tough. As well as, there’s a creating pattern in mannequin coaching that makes use of artificial information generated by LLMs (e.g., GPT-4), the place contamination could also be much more tough to establish utilizing string matching.
To look at decontamination strategies, a brand new research by UC Berkeley and Shanghai Jiao Tong College introduces the idea of a “rephrased pattern,” which has the identical semantics as the unique pattern however is tough to establish by current contamination exams. LLMs generate rephrased samples by translating and paraphrasing check samples into one other language. The researchers display that if such paraphrased examples are utilized for coaching, the ensuing mannequin is extremely inclined to overfitting and may obtain extraordinarily excessive efficiency on check benchmarks. A finely calibrated 13B Llama mannequin can match GPT -4’s efficiency throughout all benchmarks whereas remaining unnoticed by n-gram overlap as contamination. This conduct is noticed in broadly used benchmarks like MMLU, GSM-8k, and HumanEval. In consequence, the flexibility to establish rephrased samples is essential.
The researchers clarify the failings in standard decontamination methods and recommend a novel LLM-based method. To find out if any top-k samples are too just like the check occasion, they first apply an embedding similarity search to search out probably the most comparable fashions to the check pattern in query. The outcomes display the prevalence of their urged LLM decontaminator over standard methods. They check their decontaminator on a wide range of in style datasets which are used for fine-tuning and preliminary coaching. It’s additionally discovered that GPT-3.5’s artificial dataset, CodeAlpaca, has a large quantity of rephrased samples from HumanEval (12.8% to be actual). This hints at a possible for contamination throughout coaching with LLM-created pretend information.
The researchers advise the group to determine extra thorough decontamination procedures for evaluating LLMs utilizing public benchmarks. They hope to create new, one-time exams, like Codeforces and Kaggle competitions, for the truthful analysis of LLMs to beat these elementary points.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to affix our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Dhanshree Shenwai is a Pc Science Engineer and has an excellent expertise in FinTech firms masking Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is passionate about exploring new applied sciences and developments in immediately’s evolving world making everybody’s life straightforward.




