Google AI Introduces Visually Wealthy Doc Understanding (VRDU): A Dataset for Higher Monitoring of Doc Understanding Activity Progress
Increasingly more papers are being created and saved by companies in in the present day’s digital age. Though these papers could embody helpful data, they’re typically straightforward to learn and comprehend. Invoices, types, and contracts which can be additionally visually advanced current a good larger issue. The layouts, tables, and graphics in such publications may make it difficult to parse out the helpful data.
To shut this information hole and enhance progress monitoring on doc understanding duties, Google researchers have introduced the supply of the brand new Visually Wealthy Doc Understanding (VRDU) dataset. Based mostly on the varieties of real-world paperwork usually processed by doc understanding fashions, they current 5 standards for an efficient benchmark. The paper particulars how mostly used datasets within the analysis group fall quick in a minimum of one in all these areas, whereas VRDU excels in each one. Researchers at Google are happy to share that the VRDU dataset and evaluation code at the moment are accessible to the general public beneath a Artistic Commons license.
The objective of the analysis department, Visually Wealthy Doc Understanding (VRDU), is to search out methods to know such supplies routinely. Structured data like names, addresses, dates, and sums could be extracted from paperwork utilizing VRDU fashions. Bill processing, CRM, and fraud detection are only a few examples of how companies may put this data to make use of.
VRDU faces a variety of obstacles. The wide selection of doc varieties represents one impediment. Due to their intricate patterns and preparations, visually wealthy papers current an extra issue. VRDU fashions should have the ability to take care of imperfect inputs like typos and gaps within the knowledge.
Regardless of the obstacles, VRDU is a promising and rapidly creating area. VRDU fashions can assist companies in decreasing prices and growing effectivity whereas enhancing their operations’ precision.
Over the previous few years, subtle automated methods have been developed to course of and convert sophisticated enterprise paperwork into structured objects. Handbook knowledge entry is time-consuming; a system that may routinely extract knowledge from paperwork like receipts, insurance coverage quotes, and monetary statements may dramatically enhance company effectivity by eliminating this step. Newer fashions constructed on the Transformer framework have proven vital accuracy enhancements. These enterprise processes are additionally being optimized with the assistance of bigger fashions like PaLM 2. Nonetheless, the difficulties noticed in real-world use instances usually are not mirrored within the datasets utilized in tutorial publications. Which means that whereas fashions carry out properly on tutorial standards, they underperform in additional advanced real-world contexts.
Measurement requirements
First, researchers contrasted tutorial benchmarks (e.g., FUNSD, CORD, SROIE) with state-of-the-art mannequin accuracy (e.g., with FormNet and LayoutLMv2) on real-world use instances. Researchers discovered that state-of-the-art fashions supplied considerably much less accuracy in observe than these used as tutorial benchmarks. Then, they in contrast widespread datasets with doc understanding fashions to tutorial benchmarks and developed 5 situations for a dataset to replicate the complexity of real-world functions precisely.
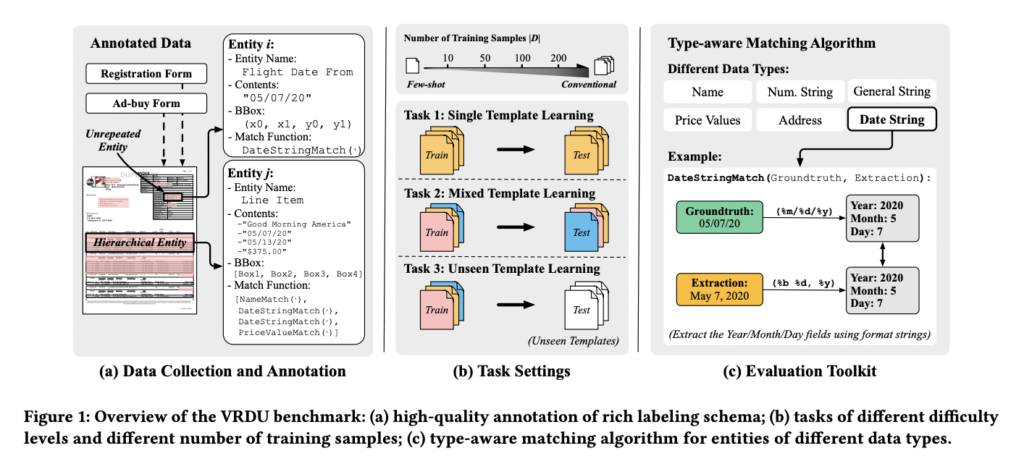
Of their analysis, scientists encounter numerous wealthy schemas used for structured extraction. Numeric, textual content, date, and time data are only a few of the various types of entities’ knowledge that is perhaps needed, optionally available, repeated, and even nested. Typical points in observe ought to be mirrored in extraction operations carried out over easy flat schemas (header, query, reply).
Complicated Format Parts The paperwork ought to have a variety of several types of format components. Issues come up when paperwork incorporate tables, key-value pairs, single-column and double-column layouts, variable font sizes for numerous sections, photos with captions, and footnotes. In distinction, the traditional pure language processing analysis on lengthy inputs typically focuses on datasets the place most papers are organized in sentences, paragraphs, and chapters with part headers.
Templates with various buildings ought to be included in any helpful benchmark. Excessive-capacity fashions can rapidly memorize the construction of a given template, making extraction from it a breeze. The train-test break up of a benchmark ought to consider this potential to generalize to new templates/layouts as a result of it’s important in observe.
Optical Character Recognition (OCR) outcomes ought to be top quality for all submitted paperwork. This benchmark goals to eradicate the results of various OCR engines on VRDU efficiency.
Annotation on the Token Stage: Paperwork ought to embody ground-truth annotations that could be mapped again to matching enter textual content, permitting particular person tokens to be annotated as a part of their respective entities. This contrasts the usual observe of passing alongside the textual content of the entity’s worth to be parsed. That is important for producing pristine coaching knowledge, free from unintentional matches to the equipped worth, so researchers can concentrate on different points of their work. If the tax quantity is zero, the ‘total-before-tax’ area on a receipt could have the identical worth because the ‘whole’ area. By annotating on the token stage, coaching knowledge could be prevented during which each occurrences of the matching worth are designated as floor reality for the ‘whole’ area, resulting in noisy examples.
Datasets and duties in VRDU
The VRDU assortment contains two separate public datasets—the Registration Varieties and Advert-Purchase Varieties datasets. These knowledge units supply cases that apply to real-world situations and meet all 5 of the benchmarks talked about above standards.
641 recordsdata within the Advert-buy Varieties assortment describe points of political commercials. A TV station and an advocacy group have every signed an bill or a receipt. Product names, air dates, whole prices, and launch occasions are just some particulars recorded within the paperwork’ tables, multi-columns, and key-value pairs.
There are 1,915 recordsdata within the Registration Varieties assortment that element the background and actions of international brokers who registered with the US authorities. Vital particulars regarding international brokers engaged in actions that have to be made public are recorded in every doc. Title of the registrant, linked company handle, actions registered for, and different data.
Current VRDU Developments
There have been many developments in VRDU in recent times. Giant-scale linguistic fashions (LLMs) are one such innovation. Giant-scale representational similarity measures (LLMs) are educated on massive datasets of textual content and code and can be utilized to symbolize the textual content and format of graphically wealthy texts.
The creation of “few-shot studying methods” is one other vital achievement. With few-shot studying approaches, VRDU fashions could rapidly be taught to extract data from novel doc varieties. That is vital because it expands the sorts of texts to which VRDU fashions could also be utilized.
Google Analysis has made the VRDU benchmark accessible to the analysis group. Invoices and types are two examples of visually wealthy paperwork included within the VRDU commonplace. There are 10,000 invoices within the invoices dataset and 10,000 types within the types dataset. The VRDU benchmark additionally encompasses a well-thought-out set of instruments for assessing efficiency.
Researchers within the area of VRDU will discover the benchmark a useful software. Researchers could now consider how properly numerous VRDU fashions carry out on the identical textual content corpus. The VRDU benchmark is helpful for extra than simply recognizing issues; it will probably additionally help in direct future research within the space.
- Structured knowledge reminiscent of could be extracted from paperwork utilizing VRDU fashions.
- Names, Addresses, Dates, Quantities, Merchandise, Providers, Situations and Necessities.
- A number of helpful enterprise procedures could be automated with using VRDU fashions, together with:
- Dealing with Invoices, Advertising to and managing present prospects, Detection of Fraud Compliance, Reporting to Authorities.
- By lowering the quantity of hand-keyed data in methods, VRDU fashions can increase the precision of firm operations.
- By automating the document-processing workflow, VRDU fashions can assist companies save money and time.
- Organizations can use VRDU fashions to spice up buyer satisfaction by expediting and perfecting their service.
The way forward for VRDU
The outlook for VRDU is optimistic. The event of LLMs and few-shot studying strategies will result in extra sturdy and versatile VRDU fashions sooner or later. Due to this, VRDU fashions can be utilized to automate extra enterprise processes and with extra varieties of paperwork.
When used to doc processing and comprehension within the company world, VRDU might have a profound impression. Digital Actuality Doc comprehension (VRDU) can save companies money and time by automating the method of doc comprehension, and it will probably additionally assist to extend the accuracy of enterprise operations.
Experiments introduced by Google researchers additional show the issue of VRDU duties and the numerous alternative for enchancment in up to date fashions in comparison with the datasets usually utilized within the literature, the place F1 scores of 0.90+ are typical. The VRDU dataset and analysis code will probably be made publicly accessible within the hopes that it’ll assist in advancing the cutting-edge of doc comprehension throughout analysis groups.
Take a look at the Paper and Google Blog. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Dhanshree Shenwai is a Laptop Science Engineer and has a superb expertise in FinTech firms protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is keen about exploring new applied sciences and developments in in the present day’s evolving world making everybody’s life straightforward.





