Utilizing reinforcement studying for dynamic planning in open-ended conversations – Google AI Weblog

As digital assistants turn out to be ubiquitous, customers more and more work together with them to study new matters or acquire suggestions and count on them to ship capabilities past slim dialogues of 1 or two turns. Dynamic planning, particularly the potential to look forward and replan primarily based on the circulate of the dialog, is a necessary ingredient for the making of participating conversations with the deeper, open-ended interactions that customers count on.
Whereas massive language fashions (LLMs) are actually beating state-of-the-art approaches in lots of pure language processing benchmarks, they’re usually educated to output the following finest response, slightly than planning forward, which is required for multi-turn interactions. Nonetheless, prior to now few years, reinforcement learning (RL) has delivered unimaginable outcomes addressing particular issues that contain dynamic planning, akin to successful video games and protein folding.
At the moment, we’re sharing our latest advances in dynamic planning for human-to-assistant conversations, during which we allow an assistant to plan a multi-turn dialog in the direction of a objective and adapt that plan in real-time by adopting an RL-based method. Right here we have a look at learn how to enhance lengthy interactions by making use of RL to compose solutions primarily based on info extracted from respected sources, slightly than counting on content material generated by a language mannequin. We count on that future variations of this work might mix LLMs and RL in multi-turn dialogues. The deployment of RL “within the wild” in a large-scale dialogue system proved a formidable problem because of the modeling complexity, tremendously massive state and motion areas, and vital subtlety in designing reward capabilities.
What’s dynamic planning?
Many sorts of conversations, from gathering info to providing suggestions, require a versatile method and the flexibility to switch the unique plan for the dialog primarily based on its circulate. This skill to shift gears in the midst of a dialog is called dynamic planning, versus static planning, which refers to a extra mounted method. Within the dialog under, for instance, the objective is to interact the person by sharing fascinating details about cool animals. To start, the assistant steers the dialog to sharks by way of a sound quiz. Given the person’s lack of curiosity in sharks, the assistant then develops an up to date plan and pivots the dialog to sea lions, lions, after which cheetahs.
 |
| The assistant dynamically modifies its unique plan to speak about sharks and shares details about different animals. |
Dynamic composition
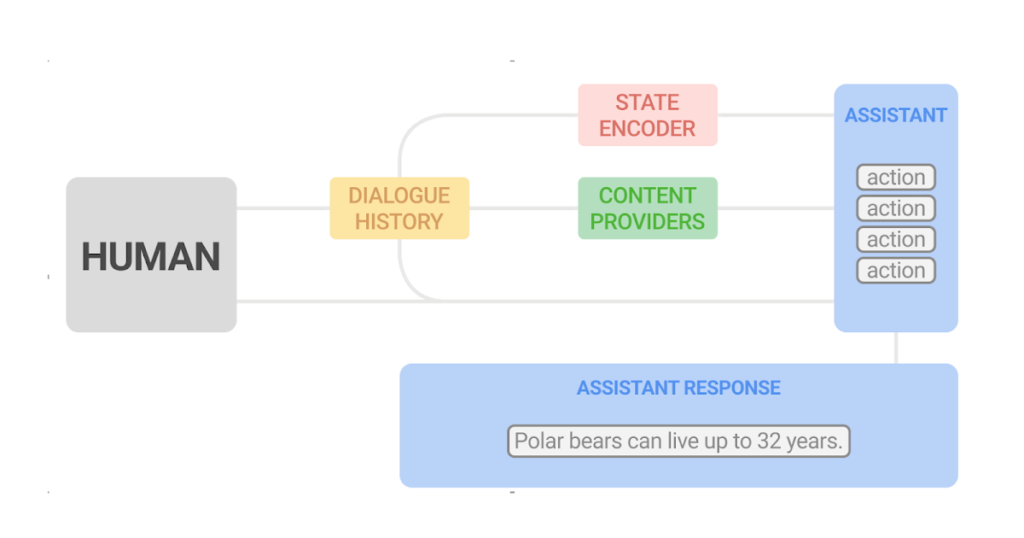
To deal with the problem of conversational exploration, we separate the technology of assistant responses into two components: 1) content material technology, which extracts related info from respected sources, and a pair of) versatile composition of such content material into assistant responses. We confer with this two-part method as dynamic composition. In contrast to LLM strategies, this method offers the assistant the flexibility to totally management the supply, correctness, and high quality of the content material that it could supply. On the identical time, it may well obtain flexibility by way of a discovered dialogue supervisor that selects and combines probably the most acceptable content material.
In an earlier paper, “Dynamic Composition for Conversational Domain Exploration”, we describe a novel method which consists of: (1) a group of content material suppliers, which provide candidates from completely different sources, akin to information snippets, knowledge graph details, and questions; (2) a dialogue supervisor; and (3) a sentence fusion module. Every assistant response is incrementally constructed by the dialogue supervisor, which selects candidates proposed by the content material suppliers. The chosen sequence of utterances is then fused right into a cohesive response.
Dynamic planning utilizing RL
On the core of the assistant response composition loop is a dialogue supervisor educated utilizing off-policy RL, particularly an algorithm that evaluates and improves a coverage that’s completely different from the coverage utilized by the agent (in our case, the latter relies on a supervised mannequin). Making use of RL to dialogue administration presents a number of challenges, together with a big state house (because the state represents the dialog state, which must account for the entire dialog historical past) and an successfully unbounded motion house (that will embrace all current phrases or sentences in pure language).
We tackle these challenges utilizing a novel RL building. First, we leverage highly effective supervised fashions — particularly, recurrent neural networks (RNNs) and transformers — to offer a succinct and efficient dialogue state illustration. These state encoders are fed with the dialogue historical past, composed of a sequence of person and assistant turns, and output a illustration of the dialogue state within the type of a latent vector.
Second, we use the truth that a comparatively small set of affordable candidate utterances or actions could be generated by content material suppliers at every dialog flip, and restrict the motion house to those. Whereas the motion house is usually mounted in RL settings, as a result of all states share the identical motion house, ours is a non-standard house during which the candidate actions could differ with every state, since content material suppliers generate completely different actions relying on the dialogue context. This places us within the realm of stochastic motion units, a framework that formalizes circumstances the place the set of actions out there in every state is ruled by an exogenous stochastic course of, which we tackle utilizing Stochastic Action Q-Learning, a variant of the Q-learning method. Q-learning is a well-liked off-policy RL algorithm, which doesn’t require a mannequin of the setting to guage and enhance the coverage. We educated our mannequin on a corpus of crowd-compute–rated conversations obtained utilizing a supervised dialogue supervisor.
 |
| Given the present dialogue historical past and a brand new person question, content material suppliers generate candidates from which the assistant selects one. This course of runs in a loop, and on the finish the chosen utterances are fused right into a cohesive response. |
Reinforcement studying mannequin analysis
We in contrast our RL dialogue supervisor with a launched supervised transformer mannequin in an experiment utilizing Google Assistant, which conversed with customers about animals. A dialog begins when a person triggers the expertise by asking an animal-related question (e.g., “How does a lion sound?”). The experiment was carried out utilizing an A/B testing protocol, during which a small proportion of Assistant customers had been randomly sampled to work together with our RL-based assistant whereas different customers interacted with the usual assistant.
We discovered that the RL dialogue supervisor conducts longer, extra participating conversations. It will increase dialog size by 30% whereas bettering person engagement metrics. We see a rise of 8% in cooperative responses to the assistant’s questions — e.g., “Inform me about lions,” in response to “Which animal do you need to hear about subsequent?” Though there’s additionally a big enhance in nominally “non-cooperative” responses (e.g., “No,” as a reply to a query proposing extra content material, akin to “Do you need to hear extra?”), that is anticipated because the RL agent takes extra dangers by asking pivoting questions. Whereas a person will not be within the conversational course proposed by the assistant (e.g., pivoting to a different animal), the person will typically proceed to interact in a dialogue about animals.
 |
| From the non-cooperative person response within the third flip (“No.”) and the question “Make a canine sound,” within the fifth flip, the assistant acknowledges that the person is usually curious about animal sounds and modifies its plan, offering sounds and sound quizzes. |
As well as, some person queries comprise specific constructive (e.g., “Thanks, Google,” or “I’m comfortable.”) or unfavorable (e.g., “Shut up,” or “Cease.”) suggestions. Whereas an order of magnitude fewer than different queries, they provide a direct measure of person (dis)satisfaction. The RL mannequin will increase specific constructive suggestions by 32% and reduces unfavorable suggestions by 18%.
Discovered dynamic planning traits and methods
We observe a number of traits of the (unseen) RL plan to enhance person engagement whereas conducting longer conversations. First, the RL-based assistant ends 20% extra turns in questions, prompting the person to decide on extra content material. It additionally higher harnesses content material variety, together with details, sounds, quizzes, sure/no questions, open questions, and so forth. On common, the RL assistant makes use of 26% extra distinct content material suppliers per dialog than the supervised mannequin.
Two noticed RL planning methods are associated to the existence of sub-dialogues with completely different traits. Sub-dialogues about animal sounds are poorer in content material and exhibit entity pivoting at each flip (i.e., after enjoying the sound of a given animal, we are able to both counsel the sound of a special animal or quiz the person about different animal sounds). In distinction, sub-dialogues involving animal details usually comprise richer content material and have better dialog depth. We observe that RL favors the richer expertise of the latter, choosing 31% extra fact-related content material. Lastly, when limiting evaluation to fact-related dialogues, the RL assistant displays 60% extra focus-pivoting turns, that’s, conversational turns that change the main focus of the dialogue.
Beneath, we present two instance conversations, one carried out by the supervised mannequin (left) and the second by the RL mannequin (proper), during which the primary three person turns are an identical. With a supervised dialogue supervisor, after the person declined to listen to about “right this moment’s animal”, the assistant pivots again to animal sounds to maximise the quick person satisfaction. Whereas the dialog carried out by the RL mannequin begins identically, it displays a special planning technique to optimize the general person engagement, introducing extra numerous content material, akin to enjoyable details.
 |
| Within the left dialog, carried out by the supervised mannequin, the assistant maximizes the quick person satisfaction. The correct dialog, carried out by the RL mannequin, reveals completely different planning methods to optimize the general person engagement. |
Future analysis and challenges
Prior to now few years, LLMs educated for language understanding and technology have demonstrated spectacular outcomes throughout a number of duties, together with dialogue. We are actually exploring using an RL framework to empower LLMs with the potential of dynamic planning in order that they will dynamically plan forward and delight customers with a extra participating expertise.
Acknowledgements
The work described is co-authored by: Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor and Gal Elidan. We want to thank: Roee Aharoni, Moran Ambar, John Anderson, Ido Cohn, Mohammad Ghavamzadeh, Lotem Golany, Ziv Hodak, Adva Levin, Fernando Pereira, Shimi Salant, Shachar Shimoni, Ronit Slyper, Ariel Stolovich, Hagai Taitelbaum, Noam Velan, Avital Zipori and the CrowdCompute staff led by Ashwin Kakarla. We thank Sophie Allweis for her suggestions on this blogpost and Tom Small for the visualization.





