Construct a serverless assembly summarization backend with massive language fashions on Amazon SageMaker JumpStart

AWS delivers providers that meet clients’ synthetic intelligence (AI) and machine studying (ML) wants with providers starting from customized {hardware} like AWS Trainium and AWS Inferentia to generative AI basis fashions (FMs) on Amazon Bedrock. In February 2022, AWS and Hugging Face announced a collaboration to make generative AI more accessible and cost efficient.
Generative AI has grown at an accelerating price from the biggest pre-trained mannequin in 2019 having 330 million parameters to greater than 500 billion parameters right this moment. The efficiency and high quality of the fashions additionally improved drastically with the variety of parameters. These fashions span duties like text-to-text, text-to-image, text-to-embedding, and extra. You need to use massive language fashions (LLMs), extra particularly, for duties together with summarization, metadata extraction, and query answering.
Amazon SageMaker JumpStart is an ML hub that may helps you speed up your ML journey. With JumpStart, you’ll be able to entry pre-trained fashions and basis fashions from the Foundations Mannequin Hub to carry out duties like article summarization and picture technology. Pre-trained fashions are totally customizable on your use circumstances and will be simply deployed into manufacturing with the consumer interface or SDK. Most significantly, none of your knowledge is used to coach the underlying fashions. As a result of all knowledge is encrypted and doesn’t depart the digital non-public cloud (VPC), you’ll be able to belief that your knowledge will stay non-public and confidential.
This put up focuses on constructing a serverless assembly summarization utilizing Amazon Transcribe to transcribe assembly audio and the Flan-T5-XL mannequin from Hugging Face (out there on JumpStart) for summarization.
Answer overview
The Assembly Notes Generator Answer creates an automatic serverless pipeline utilizing AWS Lambda for transcribing and summarizing audio and video recordings of conferences. The answer will be deployed with different FMs out there on JumpStart.
The answer consists of the next elements:
- A shell script for making a customized Lambda layer
- A configurable AWS CloudFormation template for deploying the answer
- Lambda perform code for beginning Amazon Transcribe transcription jobs
- Lambda perform code for invoking a SageMaker real-time endpoint internet hosting the Flan T5 XL mannequin
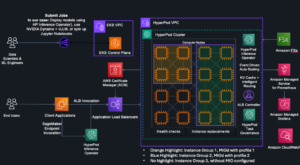
The next diagram illustrates this structure.

As proven within the structure diagram, the assembly recordings, transcripts, and notes are saved in respective Amazon Simple Storage Service (Amazon S3) buckets. The answer takes an event-driven strategy to transcribe and summarize upon S3 add occasions. The occasions set off Lambda capabilities to make API calls to Amazon Transcribe and invoke the real-time endpoint internet hosting the Flan T5 XL mannequin.
The CloudFormation template and directions for deploying the answer will be discovered within the GitHub repository.
Actual-time inference with SageMaker
Actual-time inference on SageMaker is designed for workloads with low latency necessities. SageMaker endpoints are totally managed and help a number of hosting options and auto scaling. As soon as created, the endpoint will be invoked with the InvokeEndpoint API. The offered CloudFormation template creates a real-time endpoint with the default occasion rely of 1, however it may be adjusted primarily based on anticipated load on the endpoint and because the service quota for the occasion kind permits. You possibly can request service quota will increase on the Service Quotas page of the AWS Management Console.
The next snippet of the CloudFormation template defines the SageMaker mannequin, endpoint configuration, and endpoint utilizing the ModelData and ImageURI of the Flan T5 XL from JumpStart. You possibly can discover extra FMs on Getting started with Amazon SageMaker JumpStart. To deploy the answer with a special mannequin, substitute the ModelData and ImageURI parameters within the CloudFormation template with the specified mannequin S3 artifact and container picture URI, respectively. Take a look at the sample notebook on GitHub for pattern code on methods to retrieve the newest JumpStart mannequin artifact on Amazon S3 and the corresponding public container picture offered by SageMaker.
Deploy the answer
For detailed steps on deploying the answer, comply with the Deployment with CloudFormation part of the GitHub repository.
If you wish to use a special occasion kind or extra situations for the endpoint, submit a quota improve request for the specified occasion kind on the AWS Service Quotas Dashboard.
To make use of a special FM for the endpoint, substitute the ImageURI and ModelData parameters within the CloudFormation template for the corresponding FM.
Check the answer
After you deploy the answer utilizing the Lambda layer creation script and the CloudFormation template, you’ll be able to take a look at the structure by importing an audio or video assembly recording in any of the media formats supported by Amazon Transcribe. Full the next steps:
- On the Amazon S3 console, select Buckets within the navigation pane.
- From the checklist of S3 buckets, select the S3 bucket created by the CloudFormation template named
meeting-note-generator-demo-bucket-<aws-account-id>. - Select Create folder.
- For Folder title, enter the S3 prefix specified within the
S3RecordingsPrefixparameter of the CloudFormation template (recordingsby default). - Select Create folder.

- Within the newly created folder, select Add.

- Select Add recordsdata and select the assembly recording file to add.
- Select Add.
Now we are able to examine for a profitable transcription.
- On the Amazon Transcribe console, select Transcription jobs within the navigation pane.
- Examine {that a} transcription job with a corresponding title to the uploaded assembly recording has the standing In progress or Full.

- When the standing is Full, return to the Amazon S3 console and open the demo bucket.
- Within the S3 bucket, open the
transcripts/folder. - Obtain the generated textual content file to view the transcription.
We are able to additionally examine the generated abstract.
- Within the S3 bucket, open the
notes/folder. - Obtain the generated textual content file to view the generated abstract.
Immediate engineering
Despite the fact that LLMs have improved in the previous few years, the fashions can solely soak up finite inputs; due to this fact, inserting a complete transcript of a gathering could exceed the restrict of the mannequin and trigger an error with the invocation. To design round this problem, we are able to break down the context into manageable chunks by limiting the variety of tokens in every invocation context. On this pattern answer, the transcript is damaged down into smaller chunks with a most restrict on the variety of tokens per chunk. Then every transcript chunk is summarized utilizing the Flan T5 XL mannequin. Lastly, the chunk summaries are mixed to type the context for the ultimate mixed abstract, as proven within the following diagram.

The next code from the GenerateMeetingNotes Lambda perform makes use of the Natural Language Toolkit (NLTK) library to tokenize the transcript, then it chunks the transcript into sections, every containing as much as a sure variety of tokens:
Lastly, the next code snippet combines the chunk summaries because the context to generate a last abstract:
The complete GenerateMeetingNotes Lambda perform will be discovered within the GitHub repository.
Clear up
To scrub up the answer, full the next steps:
- Delete all objects within the demo S3 bucket and the logs S3 bucket.
- Delete the CloudFormation stack.
- Delete the Lambda layer.
Conclusion
This put up demonstrated methods to use FMs on JumpStart to rapidly construct a serverless assembly notes generator structure with AWS CloudFormation. Mixed with AWS AI providers like Amazon Transcribe and serverless applied sciences like Lambda, you need to use FMs on JumpStart and Amazon Bedrock to construct purposes for numerous generative AI use circumstances.
For added posts on ML at AWS, go to the AWS ML Blog.
In regards to the writer
 Eric Kim is a Options Architect (SA) at Amazon Internet Providers. He works with sport builders and publishers to construct scalable video games and supporting providers on AWS. He primarily focuses on purposes of synthetic intelligence and machine studying.
Eric Kim is a Options Architect (SA) at Amazon Internet Providers. He works with sport builders and publishers to construct scalable video games and supporting providers on AWS. He primarily focuses on purposes of synthetic intelligence and machine studying.