OpenAI has Launched the ‘circuit-sparsity’: A Set of Open Instruments for Connecting Weight Sparse Fashions and Dense Baselines by way of Activation Bridges

OpenAI group has launched their openai/circuit-sparsity mannequin on Hugging Face and the openai/circuit_sparsity toolkit on GitHub. The discharge packages the fashions and circuits from the paper ‘Weight-sparse transformers have interpretable circuits‘.
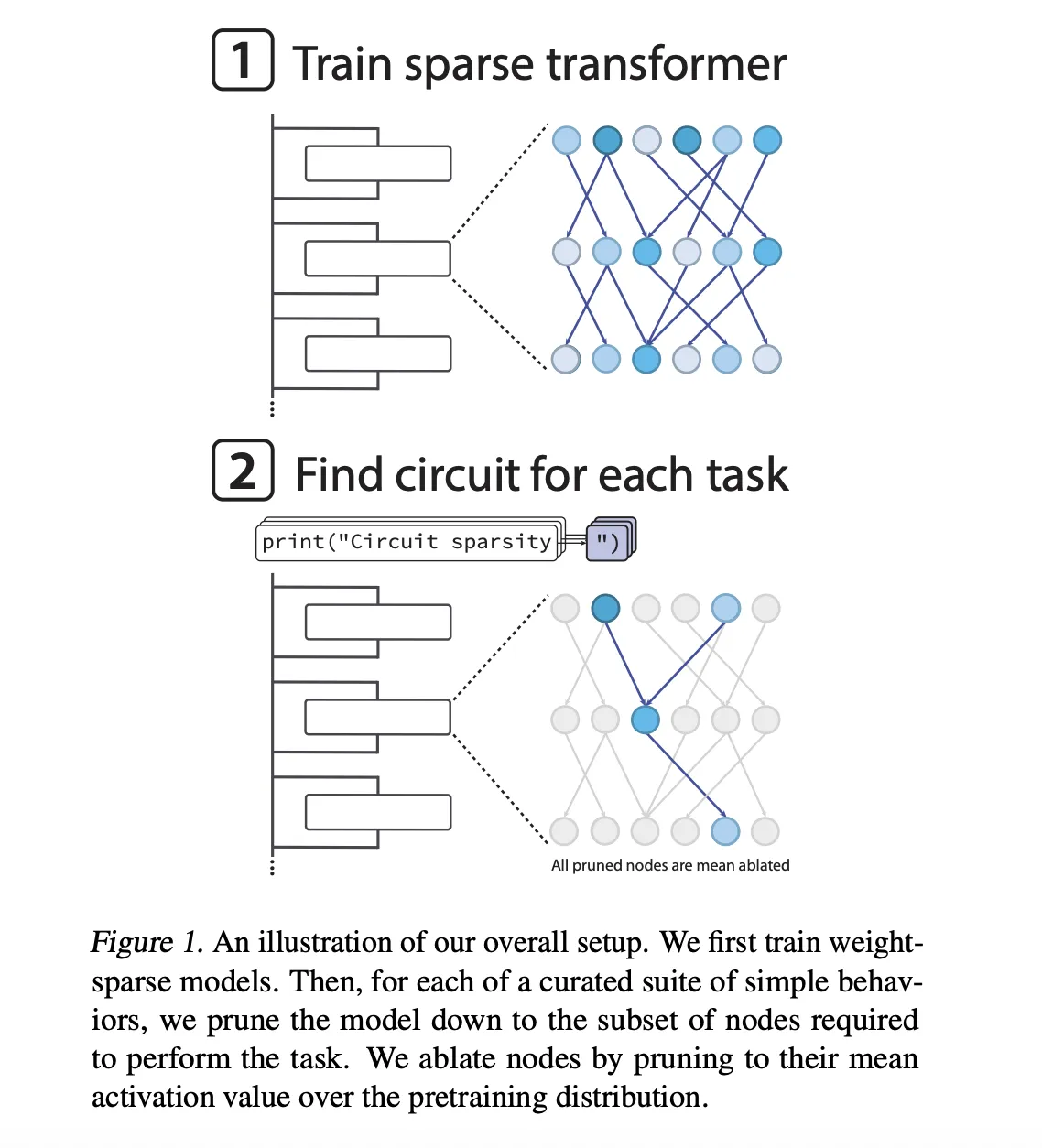
What’s a weight sparse transformer?
The fashions are GPT-2 fashion decoder solely transformers skilled on Python code. Sparsity just isn’t added after coaching, it’s enforced throughout optimization. After every AdamW step, the coaching loop retains solely the biggest magnitude entries in each weight matrix and bias, together with token embeddings, and zeros the remainder. All matrices preserve the identical fraction of nonzero parts.
The sparsest fashions have roughly 1 in 1000 nonzero weights. As well as, the OpenAI group enforced delicate activation sparsity in order that about 1 in 4 node activations are nonzero, overlaying residual reads, residual writes, consideration channels and MLP neurons.
Sparsity is annealed throughout coaching. Fashions begin dense, then the allowed nonzero finances step by step strikes towards the goal worth. This design lets the analysis group scale width whereas holding the variety of nonzero parameters mounted, after which research the potential interpretability tradeoff as they differ sparsity and mannequin measurement. The analysis group present that, for a given pretraining loss, circuits recovered from sparse fashions are roughly 16 occasions smaller than these from dense fashions.
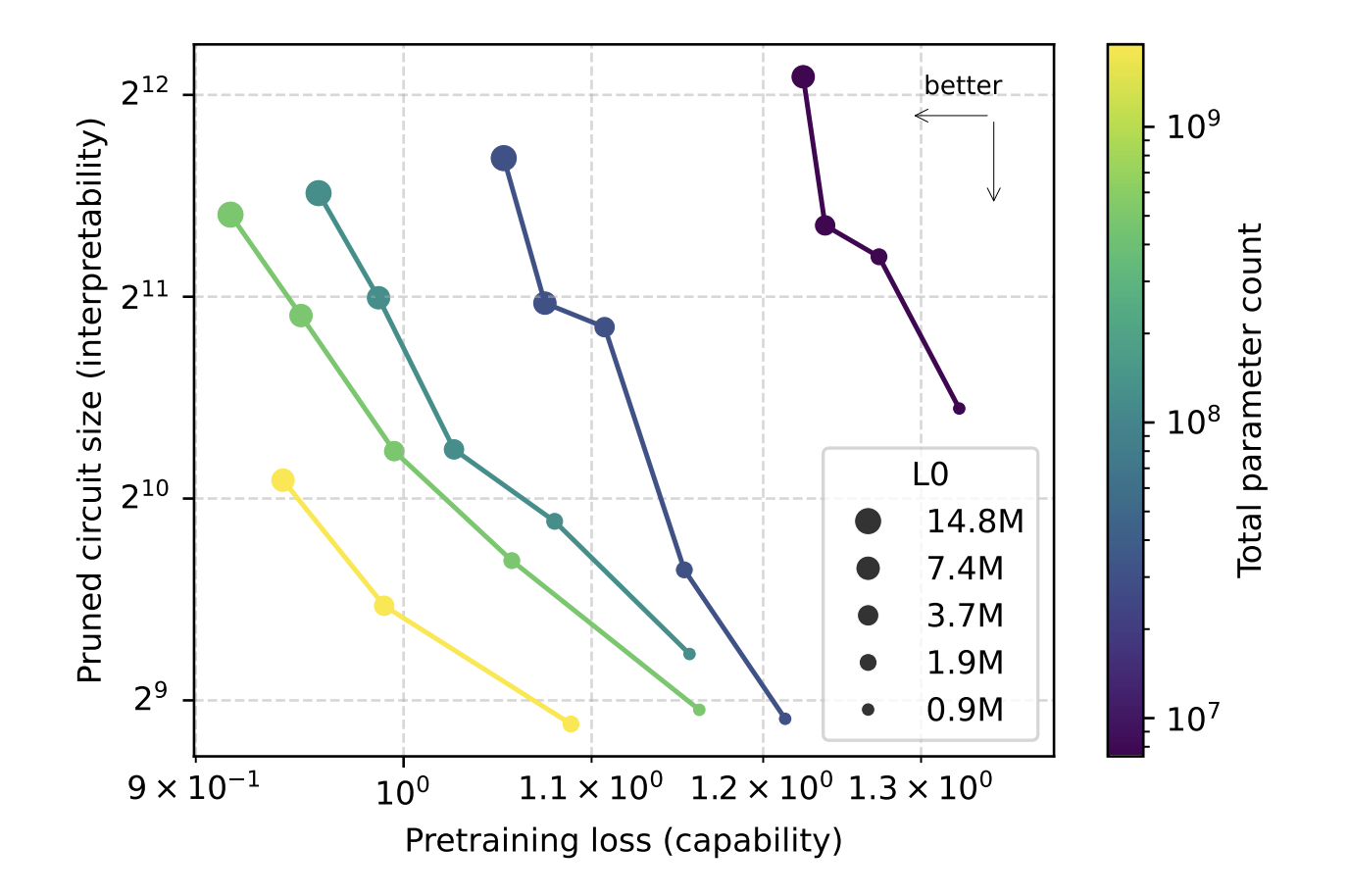
So, what’s a sparse circuit?
The central object on this analysis work is a sparse circuit. The analysis group defines nodes at a really nice granularity, every node is a single neuron, consideration channel, residual learn channel or residual write channel. An edge is a single nonzero entry in a weight matrix that connects two nodes. Circuit measurement is measured by the geometric imply variety of edges throughout duties.
To probe the fashions, the analysis group constructed 20 easy Python subsequent token binary duties. Every activity forces the mannequin to decide on between 2 completions that differ in a single token. Examples embody:
single_double_quote, predict whether or not to shut a string with a single or double quotebracket_counting, determine between]and]]based mostly on checklist nesting depthset_or_string, monitor whether or not a variable was initialized as a set or a string
For every activity, they prune the mannequin to seek out the smallest circuit that also achieves a goal lack of 0.15 on that activity distribution. Pruning operates on the node stage. Deleted nodes are imply ablated, their activations are frozen to the imply over the pretraining distribution. A realized binary masks per node is optimized with a straight by way of fashion surrogate in order that the target trades off activity loss and circuit measurement.
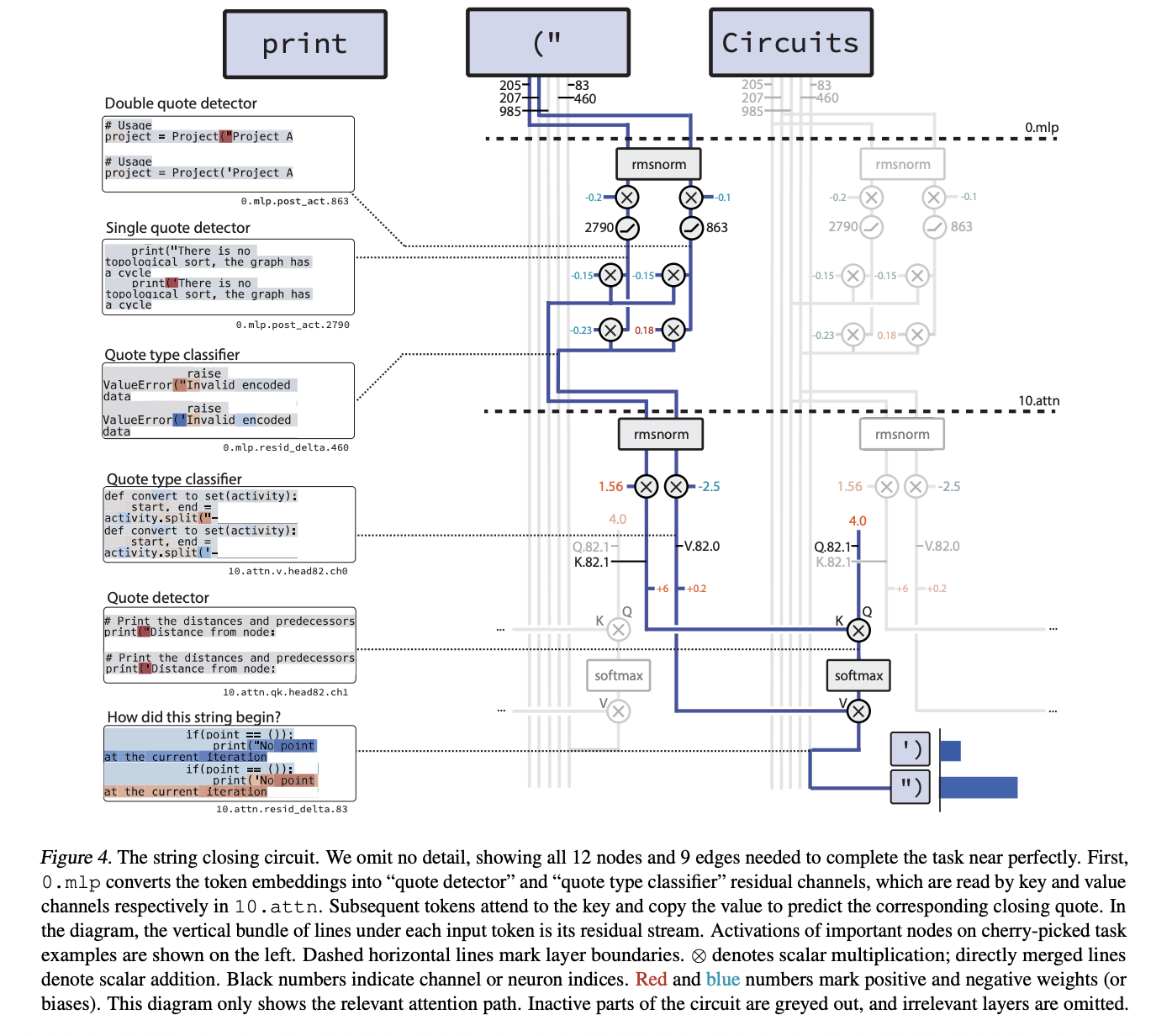
Instance circuits, quote closing and counting brackets
Probably the most compact instance is the circuit for single_double_quote. Right here the mannequin should emit the right closing quote sort given a gap quote. The pruned circuit has 12 nodes and 9 edges.
The mechanism is 2 step. In layer 0.mlp, 2 neurons specialize:
- a quote detector neuron that prompts on each
"and' - a quote sort classifier neuron that’s optimistic on
"and destructive on'
A later consideration head in layer 10.attn makes use of the quote detector channel as a key and the quote sort classifier channel as a worth. The ultimate token has a relentless optimistic question, so the eye output copies the right quote sort into the final place and the mannequin closes the string accurately.
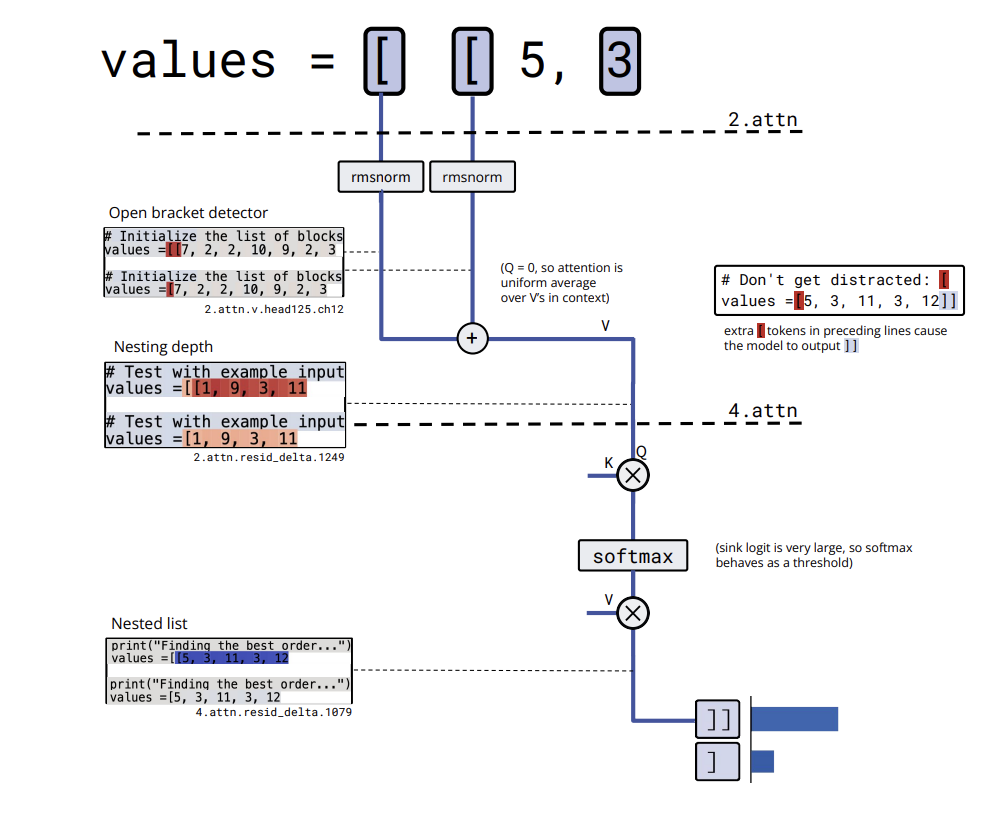
bracket_counting yields a barely bigger circuit however with a transparent algorithm. The embedding of [ writes into several residual channels that act as bracket detectors. A value channel in a layer 2 attention head averages this detector activation over the context, effectively computing nesting depth and storing it in a residual channel. A later attention head thresholds this depth and activates a nested list close channel only when the list is nested, which leads the model to output ]].
A 3rd circuit, for set_or_string_fixedvarname, exhibits how the mannequin tracks the kind of a variable known as present. One head copies the embedding of present into the set() or "" token. A later head makes use of that embedding as question and key to repeat the related data again when the mannequin should select between .add and +=.

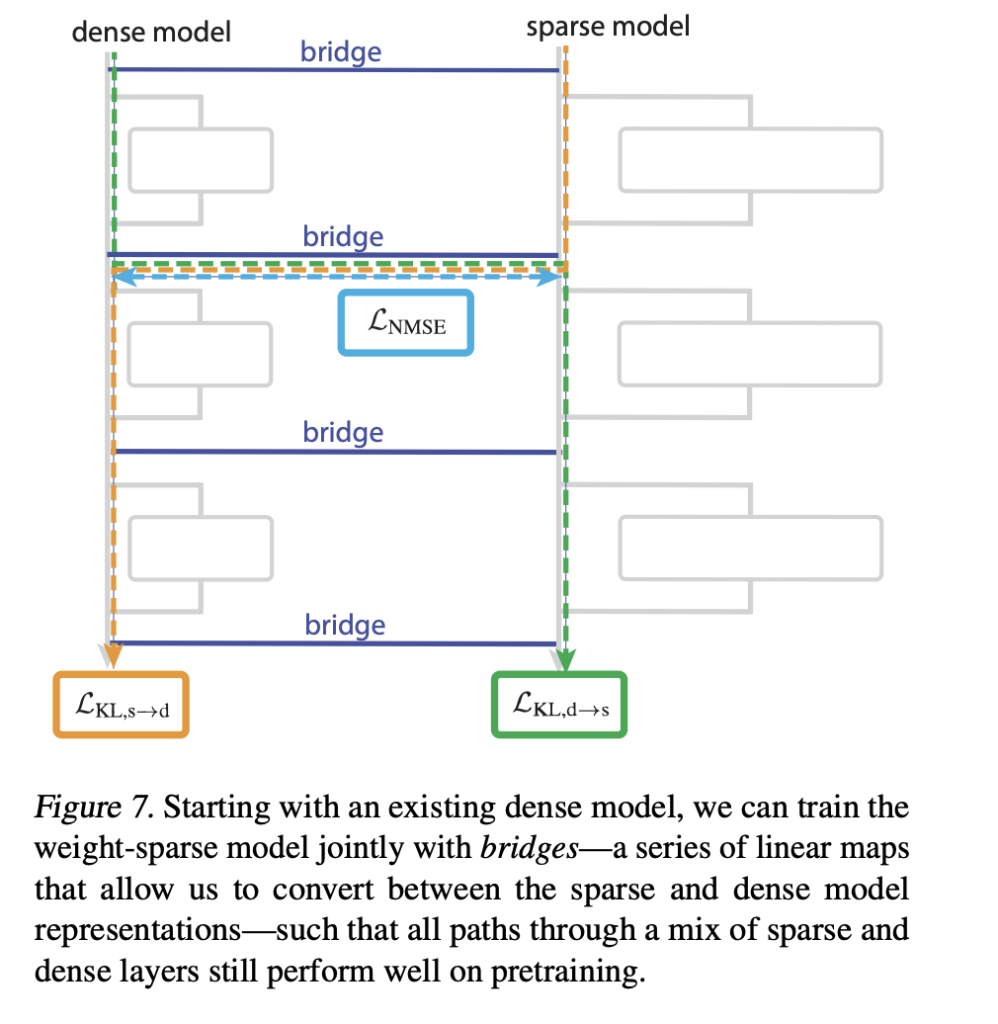
Bridges, connecting sparse fashions to dense fashions
The analysis group additionally introduces bridges that join a sparse mannequin to an already skilled dense mannequin. Every bridge is an encoder decoder pair that maps dense activations into sparse activations and again as soon as per sublayer. The encoder makes use of a linear map with an AbsTopK activation, the decoder is linear.
Coaching provides losses that encourage hybrid sparse dense ahead passes to match the unique dense mannequin. This lets the analysis group perturb interpretable sparse options such because the quote sort classifier channel after which map that perturbation into the dense mannequin, altering its habits in a managed approach.
What Precisely has OpenAI Staff launched?
The OpenAI group as launched openai/circuit-sparsity mannequin on Hugging Face. It is a 0.4B parameter mannequin tagged with custom_code, comparable to csp_yolo2 within the research paper. The mannequin is used for the qualitative outcomes on bracket counting and variable binding. It’s licensed below Apache 2.0.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
if __name__ == "__main__":
PROMPT = "def square_sum(xs):n return sum(x * x for x in xs)nnsquare_sum([1, 2, 3])n"
tok = AutoTokenizer.from_pretrained("openai/circuit-sparsity", trust_remote_code=True)
mannequin = AutoModelForCausalLM.from_pretrained(
"openai/circuit-sparsity",
trust_remote_code=True,
torch_dtype="auto",
)
mannequin.to("cuda" if torch.cuda.is_available() else "cpu")
inputs = tok(PROMPT, return_tensors="pt", add_special_tokens=False)["input_ids"].to(
mannequin.gadget
)
with torch.no_grad():
out = mannequin.generate(
inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.8,
top_p=0.95,
return_dict_in_generate=False,
)
print(tok.decode(out[0], skip_special_tokens=True))
``` :contentReference[oaicite:14]{index=14}
Key Takeaways
- Weight sparse coaching, not put up hoc pruning: Circuit sparsity trains GPT-2 fashion decoder fashions with excessive weight sparsity enforced throughout optimization, most weights are zero so every neuron has just a few connections.
- Small, activity particular circuits with express nodes and edges: The analysis group defines circuits on the stage of particular person neurons, consideration channels and residual channels, and recovers circuits that usually have tens of nodes and few edges for 20 binary Python subsequent token duties.
- Quote closing and sort monitoring are absolutely instantiated circuits: For duties like
single_double_quote,bracket_countingandset_or_string_fixedvarname, the analysis group isolate circuits that implement concrete algorithms for quote detection, bracket depth and variable sort monitoring, with the string closing circuit utilizing 12 nodes and 9 edges. - Fashions and tooling on Hugging Face and GitHub: OpenAI launched the 0.4B parameter
openai/circuit-sparsitymannequin on Hugging Face and the completeopenai/circuit_sparsitycodebase on GitHub below Apache 2.0, together with mannequin checkpoints, activity definitions and a circuit visualization UI. - Bridge mechanism to narrate sparse and dense fashions: The work introduces encoder-decoder bridges that map between sparse and dense activations, which lets researchers switch sparse characteristic interventions into normal dense transformers and research how interpretable circuits relate to actual manufacturing scale fashions.
Try the Paper and Model Weights. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.








