Architect customized generative AI SaaS purposes on Amazon SageMaker
The AI panorama is being reshaped by the rise of generative fashions able to synthesizing high-quality knowledge, equivalent to textual content, photos, music, and movies. The course towards democratization of AI helped to additional popularize generative AI following the open-source releases for such basis mannequin households as BERT, T5, GPT, CLIP and, most just lately, Stable Diffusion. A whole bunch of software program as a service (SaaS) purposes are being developed round these pre-trained fashions, that are both straight served to end-customers, or fine-tuned first on a per-customer foundation to generate private and distinctive content material (equivalent to avatars, stylized photograph edits, online game property, domain-specific textual content, and extra). With the tempo of technological innovation and proliferation of novel use instances for generative AI, upcoming AI-native SaaS suppliers and startups within the B2C section want to organize for scale from day one, and purpose to shorten their time-to-market by lowering operational overhead as a lot as doable.
On this publish, we evaluation the technical necessities and software design concerns for fine-tuning and serving hyper-personalized AI fashions at scale on AWS. We suggest an structure based mostly on the totally managed Amazon SageMaker coaching and serving options that allows SaaS suppliers to develop their purposes quicker, present high quality of service, and enhance cost-effectiveness.
Resolution scope and necessities
Let’s first outline the scope for customized generative AI SaaS purposes:
Subsequent, let’s evaluation the technical necessities and workflow for an software that helps fine-tuning and serving of probably hundreds of customized fashions. The workflow typically consists of two components:
- Generate a personalised mannequin through light-weight fine-tuning of the bottom pre-trained mannequin
- Host the customized mannequin for on-demand inference requests when the consumer returns
One of many concerns for the primary a part of the workflow is that we ought to be ready for unpredictable and spiky consumer visitors. The peaks in utilization might come up, for instance, as a consequence of new basis mannequin releases or contemporary SaaS characteristic rollouts. This may impose giant intermittent GPU capability wants, in addition to a necessity for asynchronous fine-tuning job launches to soak up the visitors spike.
With respect to mannequin internet hosting, because the market floods with AI-based SaaS purposes, velocity of service turns into a distinguishing issue. A quick, easy consumer expertise might be impaired by infrastructure chilly begins or excessive inference latency. Though inference latency necessities will depend upon the use case and consumer expectations, typically this consideration results in a choice for real-time mannequin internet hosting on GPUs (versus slower CPU-only internet hosting choices). Nonetheless, real-time GPU mannequin internet hosting can shortly result in excessive operational prices. Subsequently, it’s very important for us to outline a internet hosting technique that can forestall prices from rising linearly with the variety of deployed fashions (lively customers).
Resolution structure
Earlier than we describe the proposed structure, let’s talk about why SageMaker is a good match for our software necessities by a few of its options.
First, SageMaker Training and Hosting APIs present the productiveness advantage of totally managed coaching jobs and mannequin deployments, in order that fast-moving groups can focus extra time on product options and differentiation. Furthermore, the launch-and-forget paradigm of SageMaker Coaching jobs completely fits the transient nature of the concurrent mannequin fine-tuning jobs within the consumer onboarding part. We talk about extra concerns on concurrency within the subsequent part.
Second, SageMaker helps distinctive GPU-enabled internet hosting choices for deploying deep studying fashions at scale. For instance, NVIDIA Triton Inference Server, a high-performance open-source inference software program, was natively built-in into the SageMaker ecosystem in 2022. This was adopted by the launch of GPU help for SageMaker multi-model endpoints, which gives a scalable, low-latency, and cost-effective solution to deploy hundreds of deep studying fashions behind a single endpoint.
Lastly, after we get all the way down to the infrastructure degree, these options are backed by best-in-class compute choices. For instance, the G5 occasion sort, which is supplied with NVIDIA A10g GPUs (distinctive to AWS), affords a powerful price-performance ratio, each for mannequin coaching and internet hosting. It yields a lowest price per FP32 FLOP (an necessary measure of how a lot compute energy you get per greenback) throughout the GPU-instance palette on AWS, and tremendously improves on the earlier lowest price GPU occasion sort (G4dn). For extra data, discuss with Achieve four times higher ML inference throughput at three times lower cost per inference with Amazon EC2 G5 instances for NLP and CV PyTorch models.
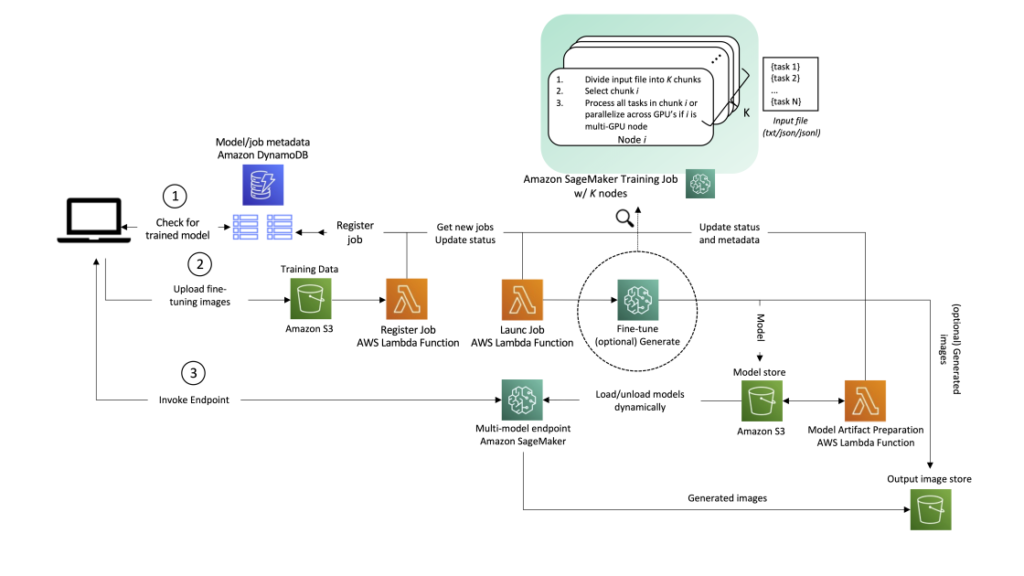
Though the next structure typically applies to numerous generative AI use instances, let’s use text-to-image technology for instance. On this situation, a picture technology app will create one or a number of customized, fine-tuned fashions for every of its customers, and people fashions might be out there for real-time picture technology on demand by the end-user. The answer workflow can then be divided into two main phases, as is clear from the structure. The primary part (A) corresponds to the consumer onboarding course of—that is when a mannequin is fine-tuned for the brand new consumer. Within the second part (B), the fine-tuned mannequin is used for on-demand inference.

Let’s undergo the steps within the structure in additional element, as numbered within the diagram.
1. Mannequin standing test
When a consumer interacts with the service, we first test if it’s a returning consumer that has already been onboarded to the service and has customized fashions prepared for serving. A single consumer may need a couple of customized mannequin. The mapping between consumer and corresponding fashions is saved in Amazon DynamoDB, which serves as a totally managed, serverless, non-relational metadata retailer, which is simple to question, cheap, and scalable. At a minimal, we advocate having two tables:
- One to retailer the mapping between customers and fashions. This contains the consumer ID and mannequin artifact Amazon Simple Storage Service (Amazon S3) URI.
- One other to function a queue, storing the mannequin creation requests and their completion standing. This contains the consumer ID, mannequin coaching job ID, and standing, together with hyperparameters and metadata related to coaching.
2. Consumer onboarding and mannequin fine-tuning.
If no mannequin has been fine-tuned for the consumer earlier than, the applying uploads fine-tuning photos to Amazon S3, triggering an AWS Lambda perform to register a brand new job to a DynamoDB desk.
One other Lambda perform queries the desk for a brand new job and launches it with SageMaker Coaching. It may be triggered for every document utilizing Amazon DynamoDB Streams, or on a schedule utilizing Amazon EventBridge (a sample that’s tried and examined by AWS clients, including internally at Amazon). Optionally, photos or prompts could be handed for inference, and processed straight within the SageMaker Coaching job proper after the mannequin is skilled. This may also help shorten the time to ship the primary photos again to the applying. As photos are generated, you possibly can exploit the checkpoint sync mechanism in SageMaker to add intermediate outcomes to Amazon S3. Relating to job launch concurrency, the SageMaker CreateTrainingJob API helps a request charge of 1 per second, with bigger burst charges out there throughout excessive visitors intervals. When you sustainably must launch a couple of fine-tuning process per second (TPS), you could have the next controls and choices:
- Use SageMaker Managed Warm Pools, which allow you to retain and reuse provisioned infrastructure after the completion of a coaching job to cut back chilly begin latency for repetitive workloads.
- Implement retries in your launch job Lambda perform (proven within the structure diagram).
- Finally, if the fine-tuning request charge will persistently be above 1 TPS, you possibly can launch N fine-tunings in parallel with a single SageMaker Coaching job by requesting a job with
num_instances=Ok, and spreading the work over the completely different situations. An instance of how one can obtain that is to go a listing of duties to be run as an enter file to the coaching job, and every occasion processes a unique process or chunk of this file, differentiated by the occasion’s numerical identifier (present in resourceconfig.json). Take into accout particular person duties shouldn’t differ tremendously in coaching period, in order to keep away from the scenario the place a single process retains the entire cluster up and working for longer than wanted.
Lastly, the fine-tuned mannequin is saved, triggering a Lambda perform that prepares the artifact for serving on a SageMaker multi-model endpoint. At this level, the consumer might be notified that coaching is full and the mannequin is prepared to be used. Consult with Managing backend requests and frontend notifications in serverless web apps for greatest practices on this.
3. On-demand serving of consumer requests
If a mannequin has been beforehand fine-tuned for the consumer, the trail is far less complicated. The appliance invokes the multi-model endpoint, passing the payload and the consumer’s mannequin ID. The chosen mannequin is dynamically loaded from Amazon S3 onto the endpoint occasion’s disk and GPU reminiscence (if it has not been just lately used; for extra data, discuss with How multi-model endpoints work), and used for inference. The mannequin output (customized content material) is lastly returned to the applying.
The request enter and output ought to be saved to S3 for the consumer’s future reference. To keep away from impacting request latency (the time measured from the second a consumer makes a request till a response is returned), you are able to do this add straight from the shopper software, or alternatively inside your endpoint’s inference code.
This structure gives the asynchrony and concurrency that have been a part of the answer necessities.
Conclusion
On this publish, we walked by means of concerns to fine-tune and serve hyper-personalized AI fashions at scale, and proposed a versatile, cost-efficient answer on AWS utilizing SageMaker.
We didn’t cowl the use case of huge mannequin pre-training. For extra data, discuss with Distributed Training in Amazon SageMaker and Sharded Data Parallelism, in addition to tales on how AWS clients have skilled huge fashions on SageMaker, equivalent to AI21 and Stability AI.
Concerning the Authors
 João Moura is an AI/ML Specialist Options Architect at AWS, based mostly in Spain. He helps clients with deep studying mannequin coaching and inference optimization, and extra broadly constructing large-scale ML platforms on AWS. He’s additionally an lively proponent of ML-specialized {hardware} and low-code ML options.
João Moura is an AI/ML Specialist Options Architect at AWS, based mostly in Spain. He helps clients with deep studying mannequin coaching and inference optimization, and extra broadly constructing large-scale ML platforms on AWS. He’s additionally an lively proponent of ML-specialized {hardware} and low-code ML options.
 Dr. Alexander Arzhanov is an AI/ML Specialist Options Architect based mostly in Frankfurt, Germany. He helps AWS clients to design and deploy their ML options throughout EMEA area. Previous to becoming a member of AWS, Alexander was researching origins of heavy components in our universe and grew obsessed with ML after utilizing it in his large-scale scientific calculations.
Dr. Alexander Arzhanov is an AI/ML Specialist Options Architect based mostly in Frankfurt, Germany. He helps AWS clients to design and deploy their ML options throughout EMEA area. Previous to becoming a member of AWS, Alexander was researching origins of heavy components in our universe and grew obsessed with ML after utilizing it in his large-scale scientific calculations.
 Olivier Cruchant is a Machine Studying Specialist Options Architect at AWS, based mostly in France. Olivier helps AWS clients – from small startups to giant enterprises – develop and deploy production-grade machine studying purposes. In his spare time, he enjoys studying analysis papers and exploring the wilderness with family and friends.
Olivier Cruchant is a Machine Studying Specialist Options Architect at AWS, based mostly in France. Olivier helps AWS clients – from small startups to giant enterprises – develop and deploy production-grade machine studying purposes. In his spare time, he enjoys studying analysis papers and exploring the wilderness with family and friends.
 Heiko Hotz is a Senior Options Architect for AI & Machine Studying with a particular deal with pure language processing (NLP), giant language fashions (LLMs), and generative AI. Previous to this function, he was the Head of Information Science for Amazon’s EU Buyer Service. Heiko helps our clients achieve success of their AI/ML journey on AWS and has labored with organizations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as a lot as doable.
Heiko Hotz is a Senior Options Architect for AI & Machine Studying with a particular deal with pure language processing (NLP), giant language fashions (LLMs), and generative AI. Previous to this function, he was the Head of Information Science for Amazon’s EU Buyer Service. Heiko helps our clients achieve success of their AI/ML journey on AWS and has labored with organizations in lots of industries, together with insurance coverage, monetary companies, media and leisure, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as a lot as doable.






