A Sensible Information to Selecting the Proper Algorithm for Your Drawback: From Regression to Neural Networks


A Sensible Information to Selecting the Proper Algorithm for Your Drawback: From Regression to Neural Networks
Picture by Editor | Ideogram
This text explains, by way of clear pointers, how to decide on the appropriate machine studying (ML) algorithm or mannequin for several types of real-world and enterprise issues. Understanding to determine on the appropriate ML algorithm is essential as a result of the success of any ML undertaking will depend on the correctness of this selection.
The article begins by presenting a question-based template and finalizes with a tabular set of instance use instances and justifications behind the collection of the most effective algorithm for each. Examples span from easy to extra superior issues requiring trendy AI capabilities like language fashions.
Word: For simplicity, the article will make a generalized use of the time period ML algorithm to seek advice from all types of ML algorithms, fashions, and strategies. Most ML strategies are model-based, with a mannequin used for inference constructed on account of making use of an algorithm, therefore in a extra deeply technical context, these phrases ought to be differentiated.
A Query-Primarily based Template
The next key questions are designed to information AI, ML, and information evaluation undertaking leaders to the appropriate selection of ML algorithm to make use of for addressing their particular drawback.
Key Query 1: What sort of drawback do you have to clear up?
- 1.A. Do you have to predict one thing?
- 1.B. In that case, is it a numerical worth, or classification into classes?
- 1.C. If you wish to predict a numerical worth, is it based mostly on different variables or options? Or are you predicting future values based mostly on previous historic ones?
The three questions above are associated to predictive or supervised studying approaches. Replying sure to query 1.A method you might be in search of a supervised studying algorithm as a result of you have to predict one thing unknown about your new or future information. Relying on what you wish to predict, and the way, you could be dealing with a classification, regression, or time sequence forecasting job. Which one? That’s what questions 1.B and 1.C will allow you to decide.
If you wish to predict or assign classes, you might be dealing with a classification job. If you wish to predict a numerical variable, akin to home worth, based mostly on different options like home traits, that’s a regression job. Lastly, if you wish to predict a future numerical worth based mostly on previous ones, e.g. predict a enterprise seat worth of a flight based mostly on a each day historical past of its common previous costs, then you might be in opposition to a time sequence forecasting job.
Again to 1.A, for those who replied no to this query, and as an alternative you wish to get a greater understanding of your information or uncover hidden patterns in them, likelihood is an unsupervised studying algorithm is what you might be in search of. As an example, if you wish to uncover hidden teams in your information (consider discovering segments of consumers), your goal job is clustering, and for those who want to determine irregular transactions or uncommon makes an attempt to log in to a high-security system, anomaly detection algorithms are your go-to method.
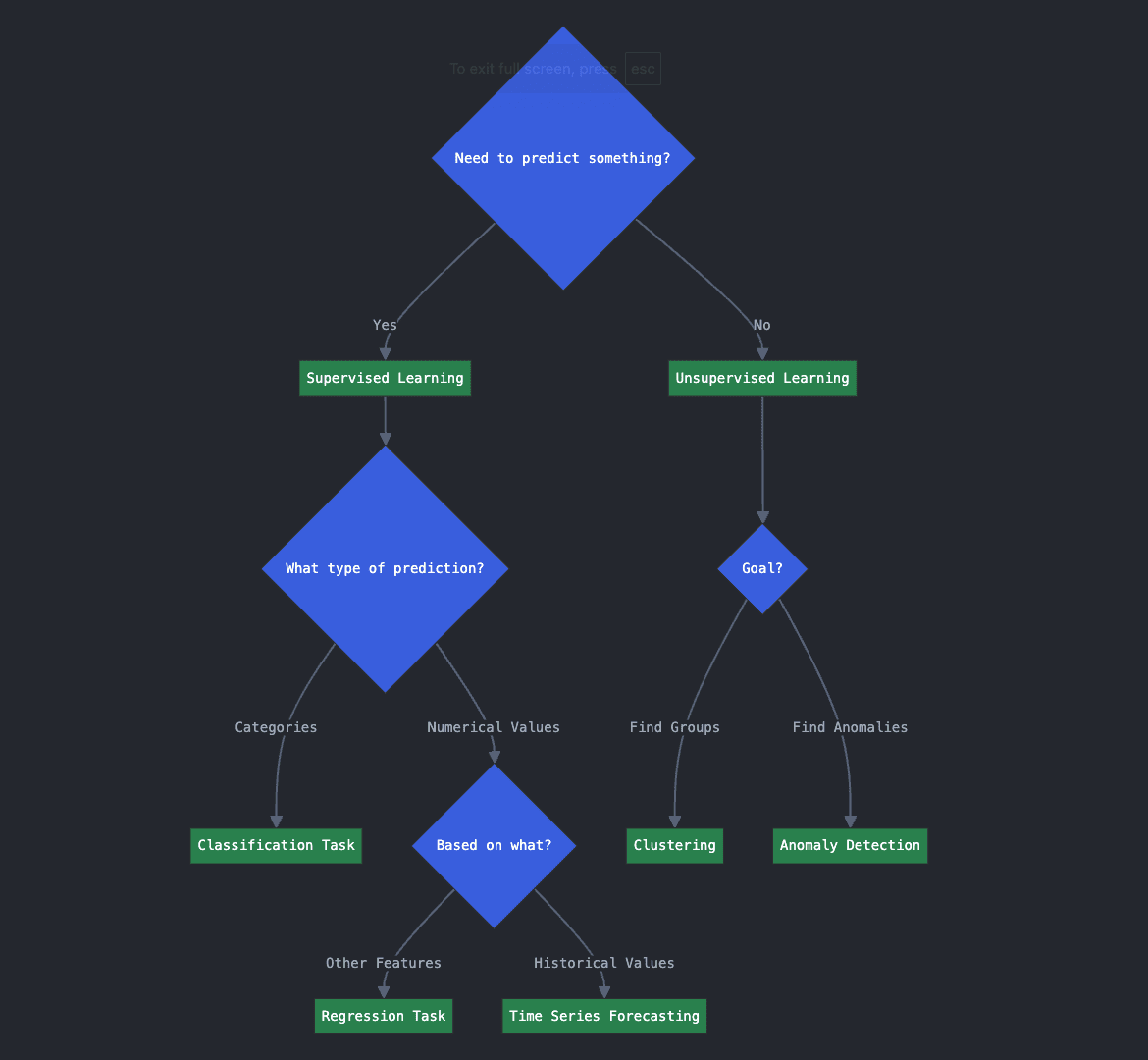
Resolution flowchart for Key Query 1 (click on to enlarge)
Picture by Editor
Key Query 2: What sort of information do you could have?
Even when your reply to the earlier query group was apparent and you’ve got a transparent goal job in thoughts, some ML duties have quite a lot of obtainable algorithms to make use of. Which one would you select? A part of that reply lies in your information, its quantity, and its complexity.
2.A. Structured and easier information organized in tables with few attributes, might be leveraged with easy ML algorithms like linear regression, choice tree classifiers, k-means clustering, and so on.
2.B. Knowledge with intermediate complexity, e.g. nonetheless structured however having dozens of attributes, or low-resolution photos, is likely to be addressed with ensemble strategies for classification and regression, which mix a number of ML mannequin situations into one to realize higher predictive outcomes. Examples of ensemble strategies are random forests, gradient boosting, and XGBoost. For different duties like clustering, attempt algorithms like DBSCAN or spectral clustering.
2.C. Final, extremely complicated information like photos, textual content, and audio often require extra superior architectures like deep neural networks: tougher to coach, however more practical in fixing difficult issues after they have been uncovered to appreciable volumes of information examples for studying. For very superior use instances like understanding and producing excessive volumes of language (textual content) information, you could even want to think about highly effective transformer-based architectures like giant language fashions (LLMs).
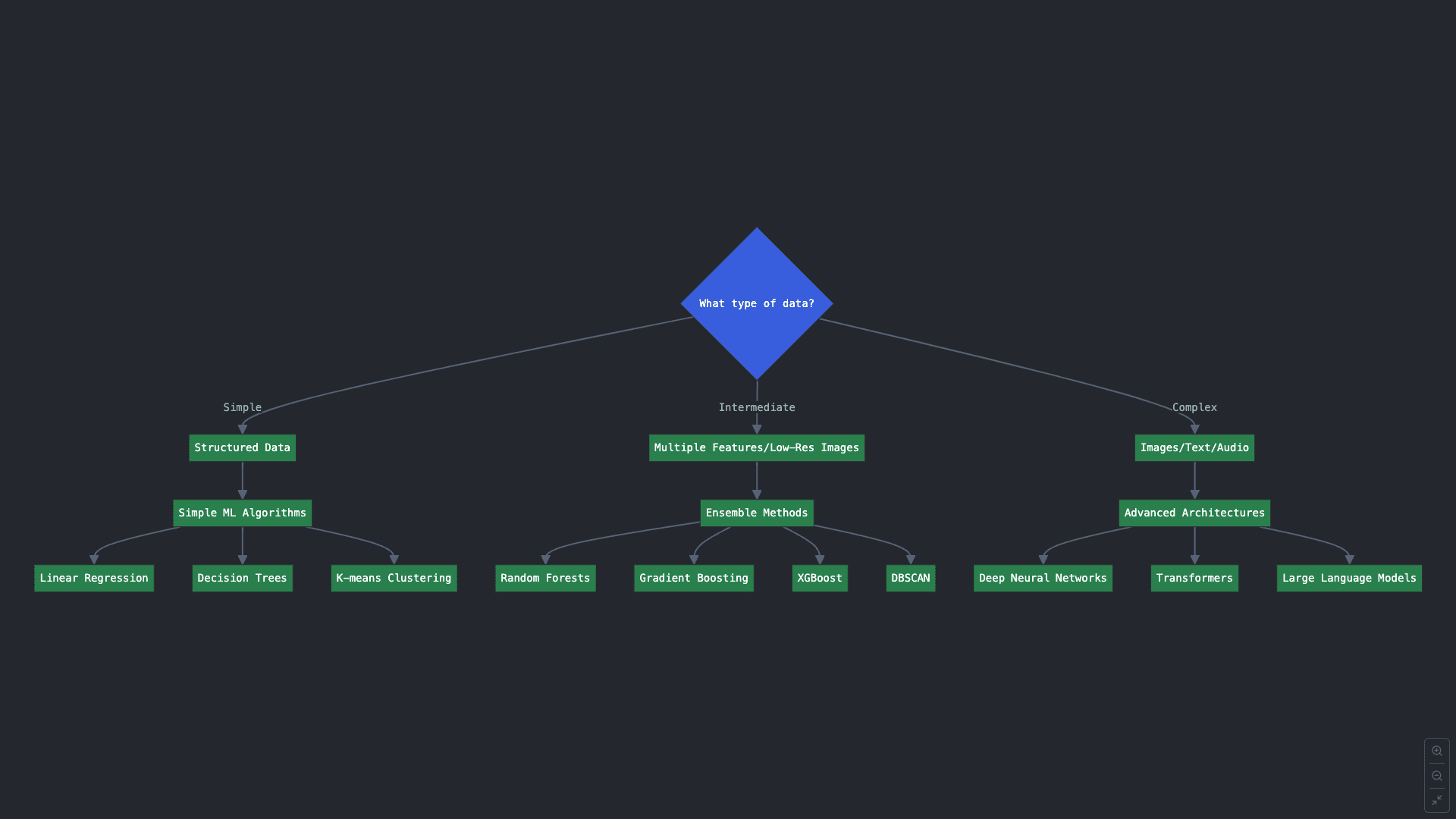
Resolution flowchart for Key Query 2 (click on to enlarge)
Picture by Editor
Key Query 3: What degree of interpretability do you want?
In sure contexts the place it is very important perceive how an ML algorithm makes choices like predictions, which enter components affect the choice, and the way, interpretability is one other vital facet that will affect your algorithm selection. As a rule of thumb, the easier the algorithm, the extra interpretable. Thus, linear regression and small choice timber are among the many most interpretable options, whereas deep neural networks with refined internal architectures are usually known as black-box fashions because of the issue of decoding choices and understanding their habits. If a stability between interpretability and excessive effectiveness in opposition to complicated information is required, choice tree-based ensemble strategies like random forests are sometimes a great trade-off answer.
Key Query 4: What quantity of information do you deal with?
This one is intently associated to key query 2. Some ML algorithms are extra environment friendly than others, relying on the quantity of information used for coaching them. Alternatively, complicated choices like neural networks usually require bigger quantities of information to be taught to carry out the duty they’re constructed for, even at the price of sacrificing environment friendly coaching. rule right here is that information quantity is normally tightly associated to information complexity in the case of selecting the best sort of algorithm.
Utility Examples
To wrap up and complement this information, here’s a desk with some real-world use instances, the place the choice components thought of on this article are outlined:
| Use Case | Drawback Sort | Beneficial Algorithm | Knowledge | Key Issues |
|---|---|---|---|---|
| Predict month-to-month gross sales | Regression | Linear Regression | Structured information | Interpretable, quick, efficient for small information |
| Fraud detection in transactions | Binary Classification | Logistic Regression, SVM | Structured information | Stability between precision and pace |
| Product classification in photos | Picture Classification | Convolutional Neural Networks (CNN) | Pictures (unstructured information) | Excessive precision, excessive computational value |
| Sentiment evaluation in product critiques | Textual content Classification (NLP) | Transformer fashions (BERT, GPT) | Textual content (unstructured information) | Requires superior assets, extremely correct |
| Churn prediction with giant datasets | Classification or Regression | Random Forest, Gradient Boosting | Structured and huge datasets | Much less interpretable, extremely efficient for Huge Knowledge |
| Automated textual content technology or answering queries | Superior NLP | Giant Language Fashions (GPT, BERT) | Giant textual content volumes | Excessive computational value, exact outcomes |
Uncover How Machine Studying Algorithms Work!

See How Algorithms Work in Minutes
…with simply arithmetic and easy examples
Uncover how in my new E book:
Master Machine Learning Algorithms
It covers explanations and examples of 10 prime algorithms, like:
Linear Regression, k-Nearest Neighbors, Assist Vector Machines and way more…
Lastly, Pull Again the Curtain on
Machine Studying Algorithms
Skip the Lecturers. Simply Outcomes.






