Understanding RAG III: Fusion Retrieval and Reranking


Understanding RAG III: Fusion Retrieval and Reranking
Picture by Editor | Midjourney & Canva
Take a look at the earlier articles on this collection:
Having beforehand launched what’s RAG, why it issues within the context of Massive Language Fashions (LLMs), and what does a traditional retriever-generator system for RAG appear like, the third put up within the “Understanding RAG” collection examines an upgraded strategy to constructing RAG programs: fusion retrieval.
Earlier than deep diving, it’s price briefly revisiting the fundamental RAG scheme we explored partially II of this collection.
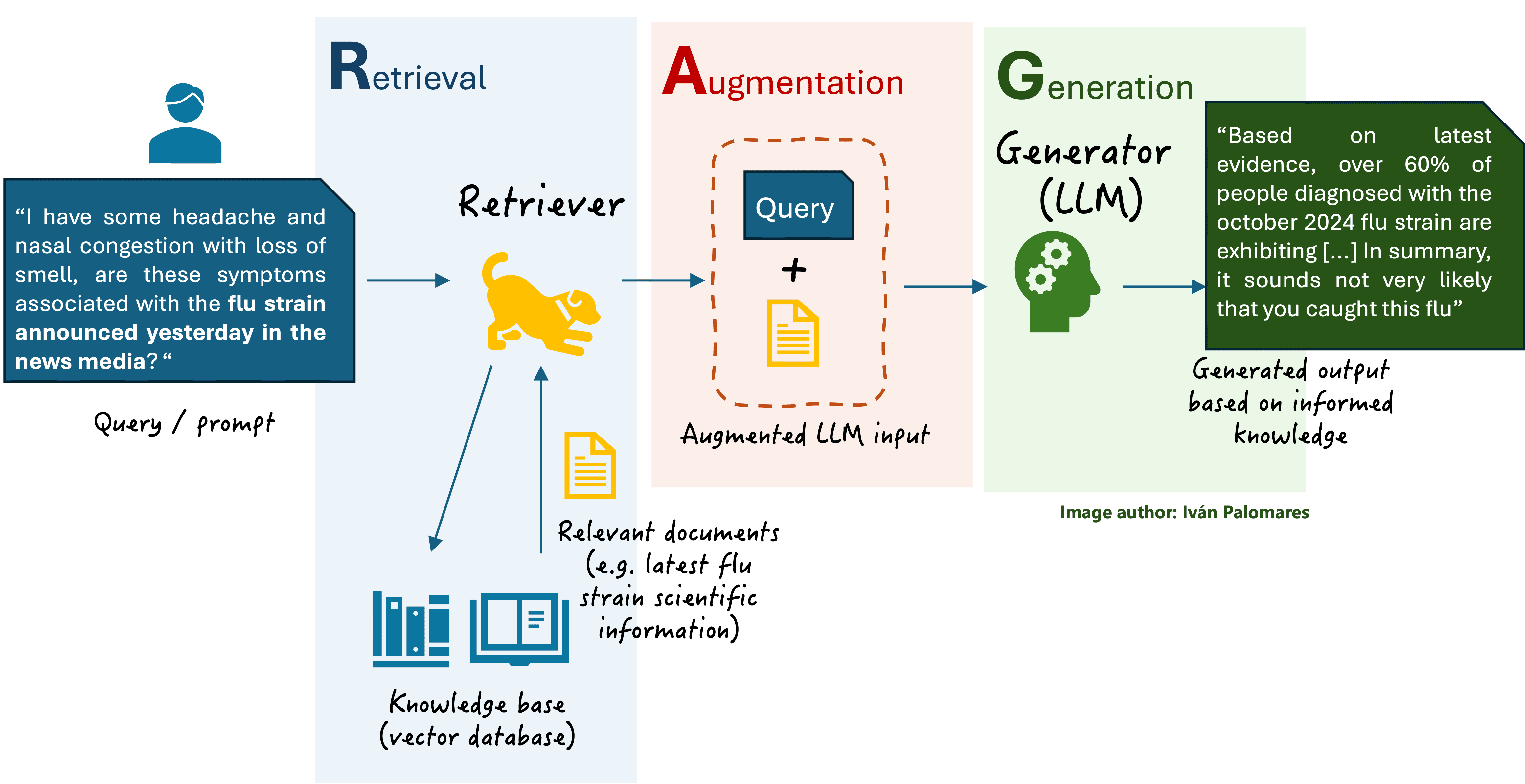
Primary RAG scheme
Fusion Retrieval Defined
Fusion retrieval approaches contain the fusion or aggregation of a number of info flows through the retrieval stage of a RAG system. Recall that through the retrieval part, the retriever -an info retrieval engine- takes the unique consumer question for the LLM, encodes it right into a vector numerical illustration, and makes use of it to go looking in an unlimited data base for paperwork that strongly match the question. After that, the unique question is augmented by including further context info ensuing from the retrieved paperwork, lastly sending the augmented enter to the LLM that generates a response.
By making use of fusion schemes within the retrieval stage, the context added on prime of the unique question can grow to be extra coherent and contextually related, additional enhancing the ultimate response generated by the LLM. Fusion retrieval leverages the data from a number of pulled paperwork (search outcomes) and combines it right into a extra significant and correct context. Nevertheless, the fundamental RAG scheme we’re already aware of also can retrieve a number of paperwork from the data base, not essentially only one. So, what’s the distinction between the 2 approaches?
The important thing distinction between traditional RAG and fusion retrieval lies in how the a number of retrieved paperwork are processed and built-in into the ultimate response. In traditional RAG, the content material within the retrieved paperwork is just concatenated or, at most, extractively summarized, after which fed as further context into the LLM to generate the response. There are not any superior fusion methods utilized. In the meantime, in fusion retrieval, extra specialised mechanisms are used to mix related info throughout a number of paperwork. This fusion course of can happen both within the augmentation stage (retrieval stage) and even within the technology stage.
- Fusion within the augmentation stage consists of making use of methods to reorder, filter, or mix a number of paperwork earlier than they’re handed to the generator. Two examples of this are reranking, the place paperwork are scored and ordered by relevance earlier than being fed into the mannequin alongside the consumer immediate, and aggregation, the place essentially the most related items of data from every doc are merged right into a single context. Aggregation is utilized by way of traditional info retrieval strategies like TF-IDF (Time period Frequency – Inverse Doc Frequency), operations on embeddings, and so on.
- Fusion within the technology stage includes the LLM (the generator) processing every retrieved doc independently -including the consumer prompt- and fusing the knowledge of a number of processing jobs through the technology of the ultimate response. Broadly talking, the augmentation stage in RAG turns into a part of the technology stage. One widespread technique on this class is Fusion-in-Decoder (FiD), which permits the LLM to course of every retrieved doc individually after which mix their insights whereas producing the ultimate response. The FiD strategy is described intimately in this paper.
Reranking is likely one of the easiest but efficient fusion approaches to meaningfully mix info from a number of retrieved sources. The subsequent part briefly explains the way it works:
How Reranking Works
In a reranking course of, the preliminary set of paperwork fetched by the retriever is reordered to enhance relevance to the consumer question, thereby higher accommodating the consumer’s wants and enhancing the general output high quality. The retriever passes the fetched paperwork to an algorithmic element referred to as a ranker, which re-evaluates the retrieved outcomes primarily based standards like realized consumer preferences, and applies a sorting of paperwork aimed toward maximizing the relevance of the outcomes offered to that exact consumer. Mechanisms like like weighted averaging or different types of scoring are used to mix and prioritize the paperwork within the highest positions of the rating, such that content material from paperwork ranked close to the highest is extra more likely to grow to be a part of the ultimate, mixed context than content material from paperwork ranked at decrease positions.
The next diagram illustrates the reranking mechanism:
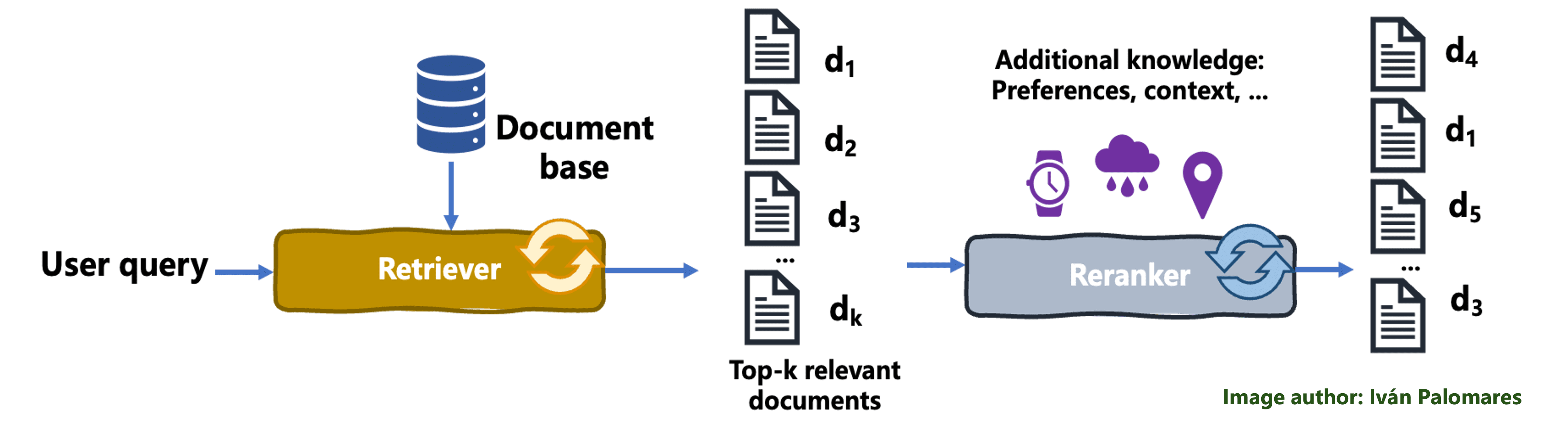
The reranking course of
Let’s describe an instance to higher perceive reranking, within the context of tourism in Jap Asia. Think about a traveler querying a RAG system for “prime locations for nature lovers in Asia.” An preliminary retrieval system may return a listing of paperwork together with normal journey guides, articles on well-liked Asian cities, and proposals for pure parks. Nevertheless, a reranking mannequin, presumably utilizing further traveler-specific preferences and contextual knowledge (like most popular actions, beforehand appreciated actions or earlier locations), can reorder these paperwork to prioritize essentially the most related content material to that consumer. It’d spotlight serene nationwide parks, lesser-known mountain climbing trails, and eco-friendly excursions which may not be on the prime of everybody’s record of options, thereby providing outcomes that go “straight to the purpose” for nature-loving vacationers like our goal consumer.
In abstract, reranking reorganizes a number of retrieved paperwork primarily based on further consumer relevance standards to focus the content material extraction course of in paperwork ranked first, thereby enhancing relevance of subsequent generated responses.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a pacesetter, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.