Management knowledge entry to Amazon S3 from Amazon SageMaker Studio with Amazon S3 Entry Grants
Amazon SageMaker Studio offers a single web-based visible interface the place completely different personas like knowledge scientists, machine studying (ML) engineers, and builders can construct, practice, debug, deploy, and monitor their ML fashions. These personas depend on entry to knowledge in Amazon Simple Storage Service (Amazon S3) for duties akin to extracting knowledge for mannequin coaching, logging mannequin coaching metrics, and storing mannequin artifacts after coaching. For instance, knowledge scientists want entry to datasets saved in Amazon S3 for duties like knowledge exploration and mannequin coaching. ML engineers require entry to intermediate mannequin artifacts saved in Amazon S3 from previous coaching jobs.
Historically, entry to knowledge in Amazon S3 from SageMaker Studio for these personas is offered by way of roles configured in SageMaker Studio—both on the area degree or person profile degree. The SageMaker Studio area function grants permissions for the SageMaker Studio area to work together with different AWS companies, offering entry to knowledge in Amazon S3 for all customers of that area. If no particular person profile roles are created, this function will apply to all person profiles, granting uniform entry privileges throughout the area. Nonetheless, if completely different customers of the area have completely different entry restrictions, then configuring particular person person roles permits for extra granular management. These roles outline the particular actions and entry every person profile can have inside the atmosphere, offering granular permissions.
Though this strategy presents a level of flexibility, it additionally entails frequent updates to the insurance policies connected to those roles every time entry necessities change, which may add upkeep overhead. That is the place Amazon S3 Access Grants can considerably streamline the method. S3 Entry Grants allows you to handle entry to Amazon S3 knowledge extra dynamically, with out the necessity to consistently replace AWS Identity and Access Management (IAM) roles. S3 Entry Grants permits knowledge house owners or permission directors to set permissions, akin to read-only, write-only, or learn/write entry, at varied ranges of Amazon S3, akin to on the bucket, prefix, or object degree. The permissions will be granted to IAM principals or to customers and teams from their company listing by way of integration with AWS IAM Identity Center.
On this publish, we reveal the way to simplify knowledge entry to Amazon S3 from SageMaker Studio utilizing S3 Entry Grants, particularly for various person personas utilizing IAM principals.
Resolution overview
Now that we’ve mentioned the advantages of S3 Entry Grants, let’s have a look at how grants will be utilized with SageMaker Studio person roles and area roles for granular entry management.
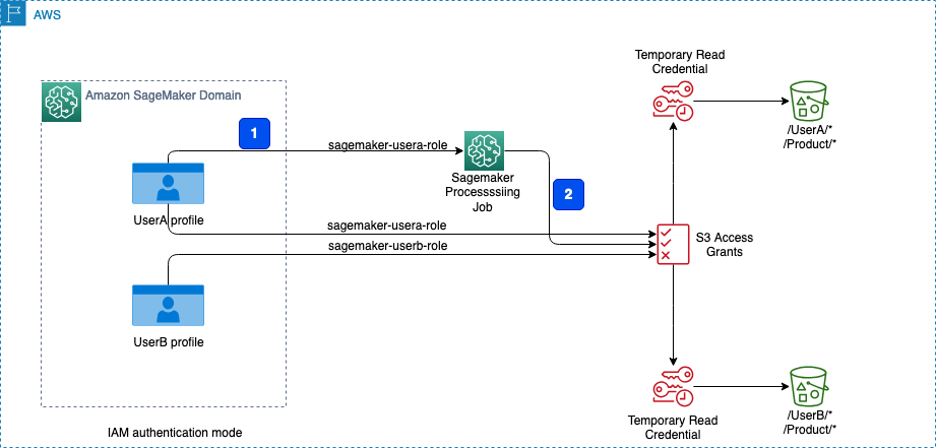
Take into account a situation involving a product group with two members: Consumer A and Consumer B. They use an S3 bucket the place the next entry necessities are carried out:
- All members of the group ought to have entry to the folder named Product inside the S3 bucket.
- The folder named
UserAmust be accessible solely by Consumer A. - The folder named
UserBmust be accessible solely by Consumer B. - Consumer A might be operating an Amazon SageMaker Processing job that makes use of S3 Entry Grants to get knowledge from the S3 bucket. The processing job will entry the required knowledge from the S3 bucket utilizing the non permanent credentials offered by the entry grants.
The next diagram illustrates the answer structure and workflow.

Let’s begin by making a SageMaker Studio atmosphere as wanted for our situation. This consists of establishing a SageMaker Studio area, organising person profiles for Consumer A and Consumer B, configuring an S3 bucket with the mandatory folders, configuring S3 Entry Grants.
Stipulations
To arrange the SageMaker Studio atmosphere and configure S3 Entry Grants as described on this publish, you want administrative privileges for the AWS account you’ll be working with. Should you don’t have administrative entry, request help from somebody who does. All through this publish, we assume that you’ve the mandatory permissions to create SageMaker Studio domains, create S3 buckets, and configure S3 Entry Grants. Should you don’t have these permissions, seek the advice of along with your AWS administrator or account proprietor for steerage.
Deploy the answer assets utilizing AWS CloudFormation
To provision the mandatory assets and streamline the deployment course of, we’ve offered an AWS CloudFormation template that automates the provisioning of required companies. Deploying the CloudFormation stack in your account incurs AWS utilization fees.
The CloudFormation stack creates the next assets:
Digital non-public cloud (VPC) with non-public subnets with related route tables, NAT gateway, web gateway, and safety teams
- IAM execution roles
- S3 Entry Grants occasion
- AWS Lambda perform to load the Abalone dataset into Amazon S3
- SageMaker area
- SageMaker Studio person profiles
Full the next steps to deploy the stack:
- Select Launch Stack to launch the CloudFormation stack.

- On the Create stack web page, depart the default choices and select Subsequent.
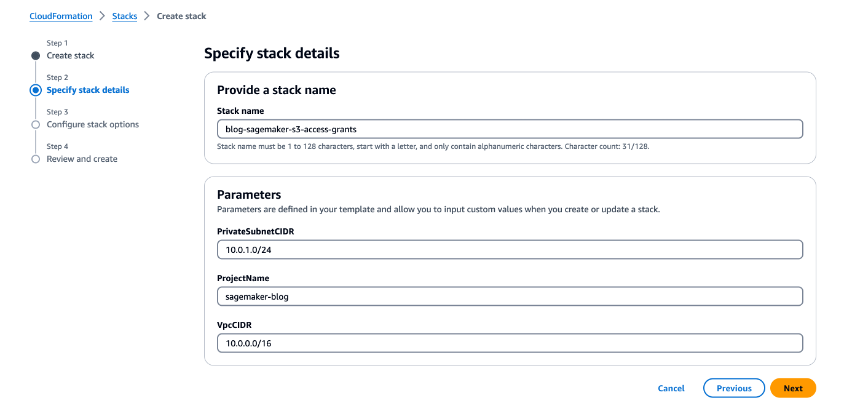
- On the Specify stack particulars web page, for Stack title, enter a reputation (for instance,
blog-sagemaker-s3-access-grants). - Beneath Parameters, present the next info:
- For PrivateSubnetCIDR, enter the IP deal with vary in CIDR notation that must be allotted for the non-public subnet.
- For ProjectName, enter
sagemaker-blog. - For VpcCIDR, enter the specified IP deal with vary in CIDR notation for the VPC being created.
- Select Subsequent.
- On the Configure stack choices web page, depart the default choices and select Subsequent.
- On the Evaluation and create web page, choose I acknowledge that AWS CloudFormation may create IAM assets with customized names.
- Evaluation the template and select Create stack.
After the profitable deployment of stack, you possibly can view the assets created on the stack’s Outputs tab on the AWS CloudFormation console.

Validate knowledge within the S3 bucket
To validate entry to the S3 bucket, we use the Abalone dataset. As a part of the CloudFormation stack deployment course of, a Lambda perform is invoked to load the info into Amazon S3. After the Lambda perform is full, you must discover the abalone.csv file in all three folders (Product, UserA, and UserB) inside the S3 bucket.

Validate the SageMaker area and related person profiles
Full the next steps to validate the SageMaker assets:
- On the SageMaker console, select Domains within the navigation pane.
- Select
Product-Areato be directed to the area particulars web page.
- Within the Consumer profiles part, confirm that the
userAanduserBprofiles are current.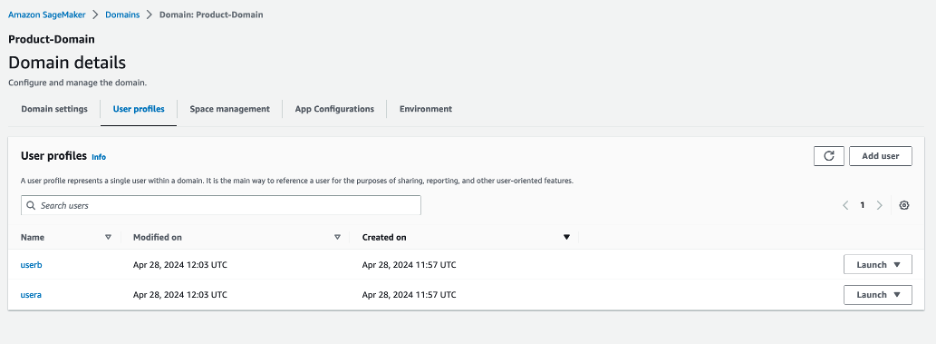
- Select a person profile title to be directed to the person profile particulars.
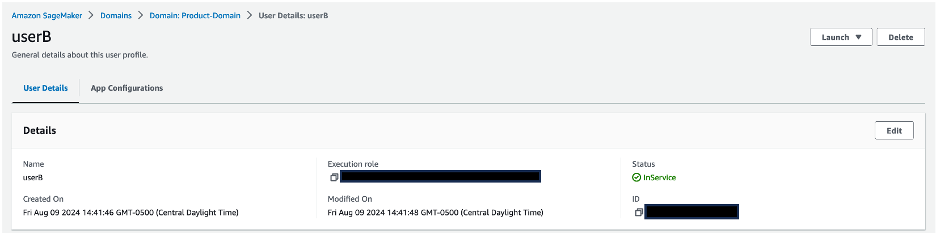
- Validate that every person profile is related to its corresponding IAM function:
userAis related tosagemaker-usera-role, anduserBis related tosagemaker-userb-role.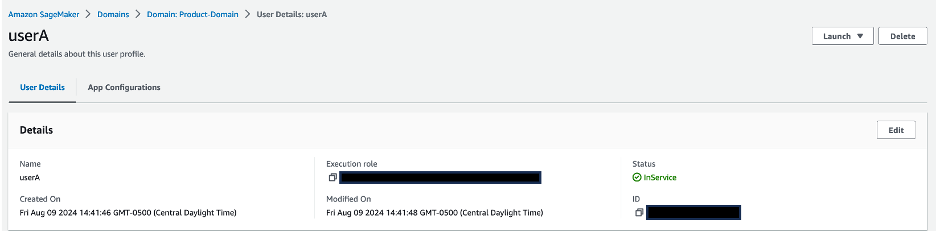
Validate S3 Entry Grants setup
Full the next steps to validate your configuration of S3 Entry Grants:
- On the Amazon S3 console, select Entry Grants within the navigation pane.
- Select View particulars to be directed to the small print web page of S3 Entry Grants.
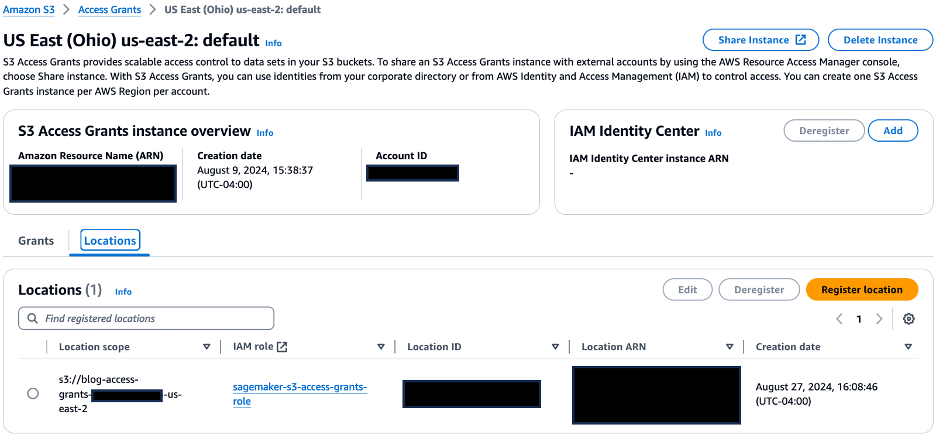
- On the Places tab, verify that the URI of S3 bucket created is registered with the S3 Entry Grants occasion for the placement scope.
- On the Grants tab, verify the next:
sagemaker-usera-rolehas been given learn/write permissions on the S3 prefixProduct/*andUserA/*sagemaker-userb-rolehas been given learn/write permissions on the S3 prefixProduct/*andUserB/*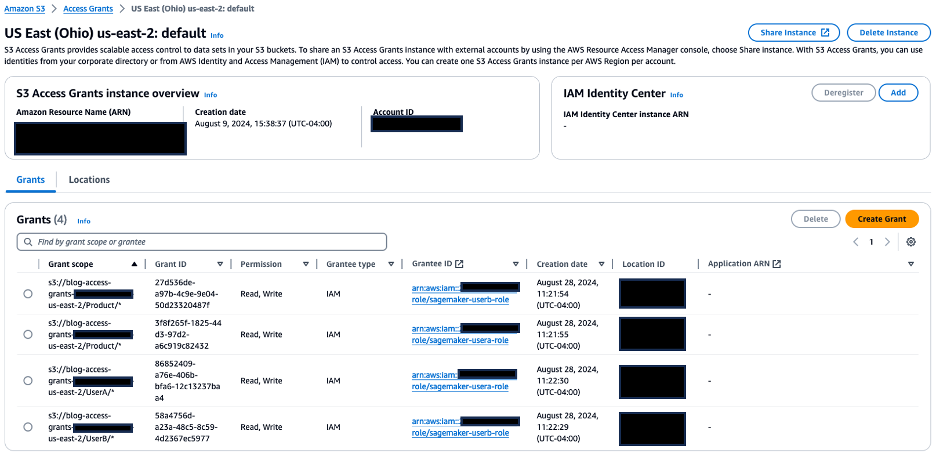
Validate entry out of your SageMaker Studio atmosphere
To validate the entry grants we arrange, we run a distributed knowledge processing job on the Abalone dataset utilizing SageMaker Processing jobs and PySpark.
To get began, full the next steps:
- On the SageMaker console, select Domains within the navigation pane.
- Select the area
Product-Areato be directed to the area particulars web page. - Select
userAbelow Consumer profiles. - On the Consumer Particulars web page, select Launch and select Studio.

- On the SageMaker Studio console, select JupyterLab within the navigation pane.
- Select Create JupyterLab area.

-
For Identify, enter usera-space.
-
For Sharing, choose Non-public.
-
Select Create area.

- After the area is created, select Run area.
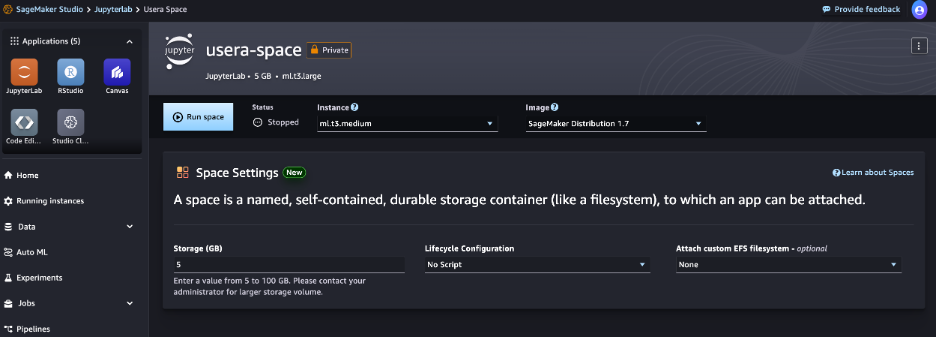
- When the standing exhibits as Operating, select Open JupyterLab, which is able to redirect you to the SageMaker JupyterLab expertise.

- On the Launcher web page, select Python 3 below Pocket book.
This may open a brand new Python pocket book, which we use to run the PySpark script.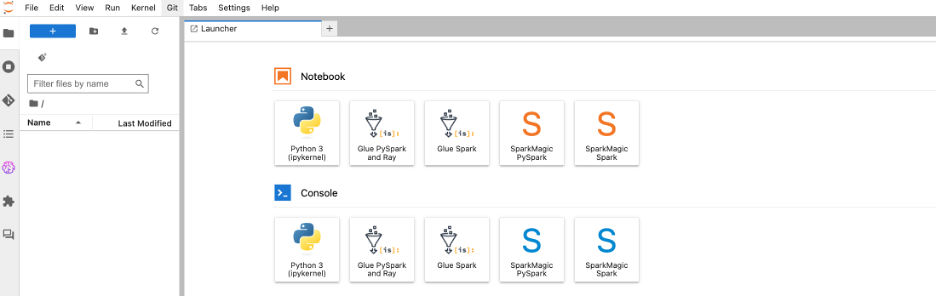
Let’s validate the entry grants by operating a distributed job utilizing SageMaker Processing jobs to course of knowledge, as a result of we frequently must course of knowledge earlier than it may be used for coaching ML fashions. SageMaker Processing jobs can help you run distributed knowledge processing workloads whereas utilizing the entry grants you arrange earlier. - Copy the next PySpark script right into a cell in your SageMaker Studio pocket book.
The%%writefiledirective is used to save lots of the script domestically. The script is used to generate non permanent credentials utilizing the entry grant and configures Spark to make use of these credentials for accessing knowledge in Amazon S3. It performs some fundamental function engineering on the Abalone dataset, together with string indexing, one-hot encoding, and vector meeting, and combines them right into a pipeline. It then does an 80/20 cut up to supply coaching and validation datasets as outputs, and saves these datasets in Amazon S3.
Ensure that to switchregion_namewith the AWS Area you’re utilizing within the script.%%writefile ./preprocess.py from pyspark.sql import SparkSession from pyspark.sql.varieties import StructType, StructField, StringType, DoubleType from pyspark.ml import Pipeline from pyspark.ml.function import StringIndexer, OneHotEncoder, VectorAssembler import argparse import subprocess import sys def install_packages(): subprocess.check_call([sys.executable, "-m", "pip", "install", "boto3==1.35.1", "botocore>=1.35.0"]) install_packages() import boto3 print(f"logs: boto3 model within the processing job: {boto3.__version__}") import botocore print(f"logs: botocore model within the processing job: {botocore.__version__}") def get_temporary_credentials(account_id, bucket_name, object_key_prefix): region_name="<area>" s3control_client = boto3.consumer('s3control', region_name=region_name) response = s3control_client.get_data_access( AccountId=account_id, Goal=f's3://{bucket_name}/{object_key_prefix}/', Permission='READWRITE' ) return response['Credentials'] def configure_spark_with_s3a(credentials): spark = SparkSession.builder .appName("PySparkApp") .config("spark.hadoop.fs.s3a.entry.key", credentials['AccessKeyId']) .config("spark.hadoop.fs.s3a.secret.key", credentials['SecretAccessKey']) .config("spark.hadoop.fs.s3a.session.token", credentials['SessionToken']) .config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") .config("spark.hadoop.fs.s3a.aws.credentials.supplier", "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider") .getOrCreate() spark.sparkContext._jsc.hadoopConfiguration().set( "mapred.output.committer.class", "org.apache.hadoop.mapred.FileOutputCommitter" ) return spark def csv_line(knowledge): r = ",".be a part of(str(d) for d in knowledge[1]) return str(knowledge[0]) + "," + r def foremost(): parser = argparse.ArgumentParser(description="app inputs and outputs") parser.add_argument("--account_id", kind=str, assist="AWS account ID") parser.add_argument("--s3_input_bucket", kind=str, assist="s3 enter bucket") parser.add_argument("--s3_input_key_prefix", kind=str, assist="s3 enter key prefix") parser.add_argument("--s3_output_bucket", kind=str, assist="s3 output bucket") parser.add_argument("--s3_output_key_prefix", kind=str, assist="s3 output key prefix") args = parser.parse_args() # Get non permanent credentials for each studying and writing credentials = get_temporary_credentials(args.account_id, args.s3_input_bucket, args.s3_input_key_prefix) spark = configure_spark_with_s3a(credentials) # Defining the schema equivalent to the enter knowledge schema = StructType([ StructField("sex", StringType(), True), StructField("length", DoubleType(), True), StructField("diameter", DoubleType(), True), StructField("height", DoubleType(), True), StructField("whole_weight", DoubleType(), True), StructField("shucked_weight", DoubleType(), True), StructField("viscera_weight", DoubleType(), True), StructField("shell_weight", DoubleType(), True), StructField("rings", DoubleType(), True), ]) # Studying knowledge straight from S3 utilizing s3a protocol total_df = spark.learn.csv( f"s3a://{args.s3_input_bucket}/{args.s3_input_key_prefix}/abalone.csv", header=False, schema=schema ) # Transformations and knowledge processing sex_indexer = StringIndexer(inputCol="intercourse", outputCol="indexed_sex") sex_encoder = OneHotEncoder(inputCol="indexed_sex", outputCol="sex_vec") assembler = VectorAssembler( inputCols=[ "sex_vec", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ], outputCol="options" ) pipeline = Pipeline(phases=[sex_indexer, sex_encoder, assembler]) mannequin = pipeline.match(total_df) transformed_total_df = mannequin.remodel(total_df) (train_df, validation_df) = transformed_total_df.randomSplit([0.8, 0.2]) # Saving remodeled datasets to S3 utilizing RDDs and s3a protocol train_rdd = train_df.rdd.map(lambda x: (x.rings, x.options)) train_lines = train_rdd.map(csv_line) train_lines.saveAsTextFile( f"s3a://{args.s3_output_bucket}/{args.s3_output_key_prefix}/practice" ) validation_rdd = validation_df.rdd.map(lambda x: (x.rings, x.options)) validation_lines = validation_rdd.map(csv_line) validation_lines.saveAsTextFile( f"s3a://{args.s3_output_bucket}/{args.s3_output_key_prefix}/validation" ) if __name__ == "__main__": foremost() - Run the cell to create the
preprocess.pyfile domestically. - Subsequent, you employ the
PySparkProcessorclass to outline a Spark job and run it utilizing SageMaker Processing. Copy the next code into a brand new cell in your SageMaker Studio pocket book, and run the cell to invoke the SageMaker Processing job:from sagemaker.spark.processing import PySparkProcessor from time import gmtime, strftime import boto3 import sagemaker import logging # Get area area = boto3.Session().region_name # Initialize Boto3 and SageMaker classes boto_session = boto3.Session(region_name=area) sagemaker_session = sagemaker.Session(boto_session=boto_session) # Get account id def get_account_id(): consumer = boto3.consumer("sts") return consumer.get_caller_identity()["Account"] account_id = get_account_id() bucket = sagemaker_session.default_bucket() function = sagemaker.get_execution_role() sagemaker_logger = logging.getLogger("sagemaker") sagemaker_logger.setLevel(logging.INFO) sagemaker_logger.addHandler(logging.StreamHandler()) # Arrange S3 bucket and paths timestamp_prefix = strftime("%Y-%m-%d-%H-%M-%S", gmtime()) prefix = "Product/sagemaker/spark-preprocess-demo/{}".format(timestamp_prefix) # Outline the account ID and S3 bucket particulars input_bucket = f'blog-access-grants-{account_id}-{area}' input_key_prefix = 'UserA' output_bucket = f'blog-access-grants-{account_id}-{area}' output_key_prefix = 'UserA/output' # Outline the Spark processor utilizing the customized Docker picture spark_processor = PySparkProcessor( framework_version="3.3", function=function, instance_count=2, instance_type="ml.m5.2xlarge", base_job_name="spark-preprocess-job", sagemaker_session=sagemaker_session ) # Run the Spark processing job spark_processor.run( submit_app="./preprocess.py", arguments=[ "--account_id", account_id, "--s3_input_bucket", input_bucket, "--s3_input_key_prefix", input_key_prefix, "--s3_output_bucket", output_bucket, "--s3_output_key_prefix", output_key_prefix, ], spark_event_logs_s3_uri=f"s3://{output_bucket}/{prefix}/spark_event_logs", logs=False )A number of issues to notice within the definition of the
PySparkProcessor:- This can be a multi-node job with two ml.m5.2xlarge cases (specified within the
instance_countandinstance_typeparameters) - The Spark framework model is about to three.3 utilizing the
framework_versionparameter - The PySpark script is handed utilizing the
submit_appparameter - Command line arguments to the PySpark script (such because the account ID, enter/output bucket names, and enter/output key prefixes) are handed by way of the
argumentsparameter - Spark occasion logs might be offloaded to the Amazon S3 location laid out in
spark_event_logs_s3_uriand can be utilized to view the Spark UI whereas the job is in progress or after it’s full.
- This can be a multi-node job with two ml.m5.2xlarge cases (specified within the
- After the job is full, validate the output of the preprocessing job by wanting on the first 5 rows of the output dataset utilizing the next validation script:
import boto3 import pandas as pd import io # Initialize S3 consumer s3 = boto3.consumer('s3') # Get area area = boto3.Session().region_name # Get account id def get_account_id(): consumer = boto3.consumer("sts") return consumer.get_caller_identity()["Account"] account_id = get_account_id()
# Change along with your bucket title and output key prefix bucket_name = f'blog-access-grants-{account_id}-{area}' output_key_prefix = 'UserA/output/practice' # Get non permanent credentials for accessing S3 knowledge utilizing person profile function s3control_client = boto3.consumer('s3control') response = s3control_client.get_data_access( AccountId=account_id, Goal=f's3://{bucket_name}/{output_key_prefix}', Permission='READ' ) credentials = response['Credentials'] # Create an S3 consumer with the non permanent credentials s3_client = boto3.consumer( 's3', aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'] ) objects = s3_client.list_objects(Bucket=bucket_name, Prefix=output_key_prefix) # Learn the primary half file right into a pandas DataFrame first_part_key = f"{output_key_prefix}/part-00000" obj = s3_client.get_object(Bucket=bucket_name, Key=first_part_key) knowledge = obj['Body'].learn().decode('utf-8') df = pd.read_csv(io.StringIO(knowledge), header=None) # Print the highest 5 rows print(f"Prime 5 rows from s3://{bucket_name}/{first_part_key}") print(df.head())This script makes use of the entry grants to acquire non permanent credentials, reads the primary half file (
part-00000) from the output location right into a pandas DataFrame, and prints the highest 5 rows of the DataFrame.
As a result of the Consumer A task has entry to theuserAfolder, the person can learn the contents of the filepart-00000, as proven within the following screenshot.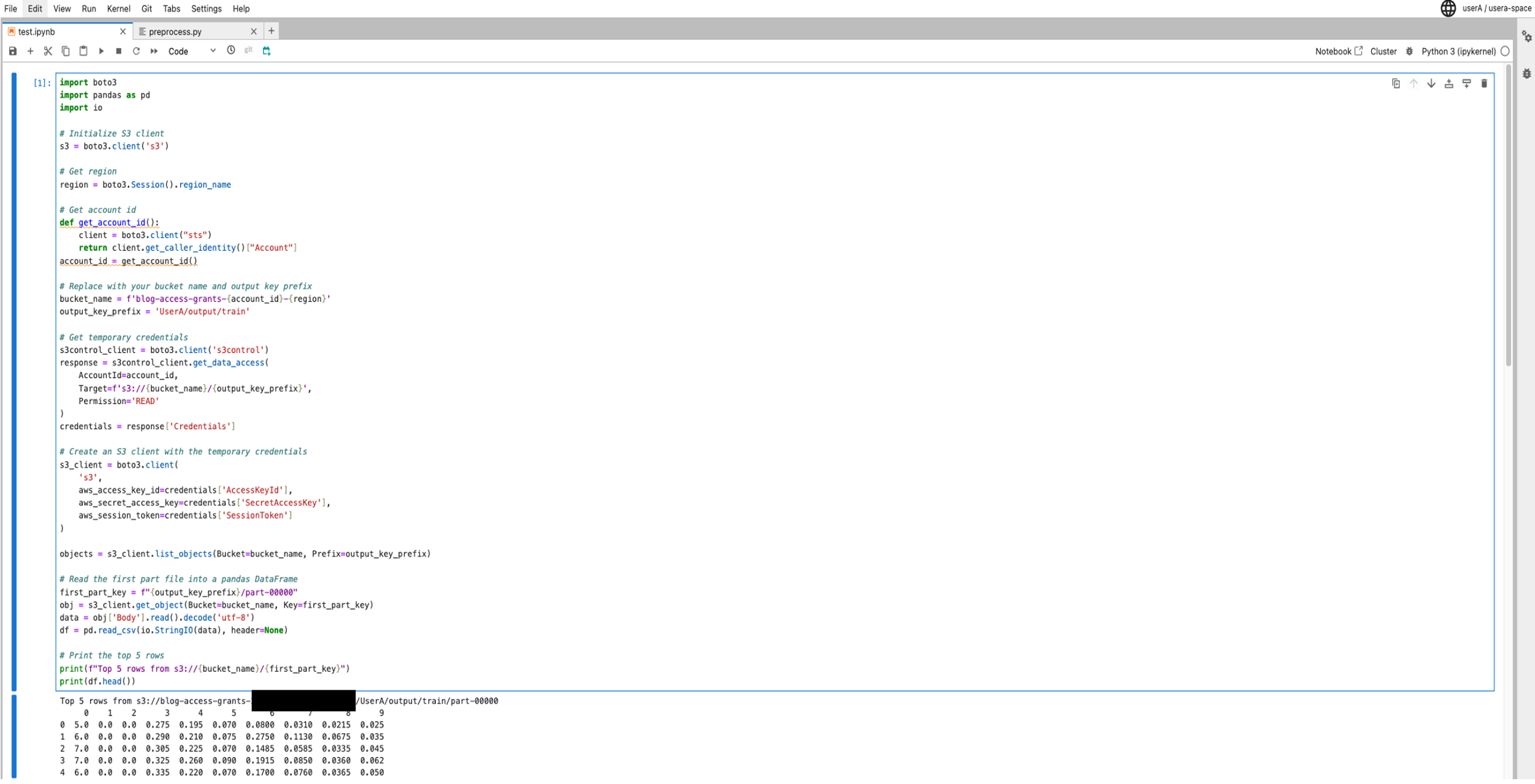
Now, let’s validate entry to the
userAfolder from the Consumer B profile. -
Repeat the sooner steps to launch a Python pocket book below the Consumer B profile.
-
Use the validation script to learn the contents of the file part-00000, which is within the
userAfolder.
If Consumer B tries to learn the contents of the file part-00000, which is within the userA folder, their entry might be denied, as proven within the following screenshot, as a result of Consumer B doesn’t have entry to the userA folder.

Clear up
To keep away from incurring future fees, delete the CloudFormation stack. This may delete assets such because the SageMaker Studio area, S3 Entry Grants occasion, and S3 bucket you created.
Conclusion
On this publish, you discovered the way to management knowledge entry to Amazon S3 from SageMaker Studio with S3 Entry Grants. S3 Entry Grants offers a extra versatile and scalable mechanism to outline entry patterns at scale than IAM based mostly strategies. These grants not solely help IAM principals but additionally enable direct granting of entry to customers and teams from a company listing that’s synchronized with IAM Identification Heart.
Take the subsequent step in optimizing your knowledge administration workflow by integrating S3 Entry Grants into your AWS atmosphere alongside SageMaker Studio, a web-based visible interface for constructing, coaching, debugging, deploying, and monitoring ML fashions. Reap the benefits of the granular entry management and scalability supplied by S3 Entry Grants to allow environment friendly collaboration, safe knowledge entry, and simplified entry administration on your group working within the SageMaker Studio atmosphere. For extra particulars, seek advice from Managing access with S3 Access Grants and Amazon SageMaker Studio.
Concerning the authors
 Koushik Konjeti is a Senior Options Architect at Amazon Internet Providers. He has a ardour for aligning architectural steerage with buyer objectives, guaranteeing options are tailor-made to their distinctive necessities. Outdoors of labor, he enjoys taking part in cricket and tennis.
Koushik Konjeti is a Senior Options Architect at Amazon Internet Providers. He has a ardour for aligning architectural steerage with buyer objectives, guaranteeing options are tailor-made to their distinctive necessities. Outdoors of labor, he enjoys taking part in cricket and tennis.
 Vijay Velpula is a Information Architect with AWS Skilled Providers. He helps prospects implement Massive Information and Analytics Options. Outdoors of labor, he enjoys spending time with household, touring, climbing and biking.
Vijay Velpula is a Information Architect with AWS Skilled Providers. He helps prospects implement Massive Information and Analytics Options. Outdoors of labor, he enjoys spending time with household, touring, climbing and biking.
 Ram Vittal is a Principal ML Options Architect at AWS. He has over 3 many years of expertise architecting and constructing distributed, hybrid, and cloud functions. He’s captivated with constructing safe, scalable, dependable AI/ML and large knowledge options to assist enterprise prospects with their cloud adoption and optimization journey. In his spare time, he rides bike and enjoys the character together with his household.
Ram Vittal is a Principal ML Options Architect at AWS. He has over 3 many years of expertise architecting and constructing distributed, hybrid, and cloud functions. He’s captivated with constructing safe, scalable, dependable AI/ML and large knowledge options to assist enterprise prospects with their cloud adoption and optimization journey. In his spare time, he rides bike and enjoys the character together with his household.





