Constructing a Easy RAG Utility Utilizing LlamaIndex
Picture by Creator
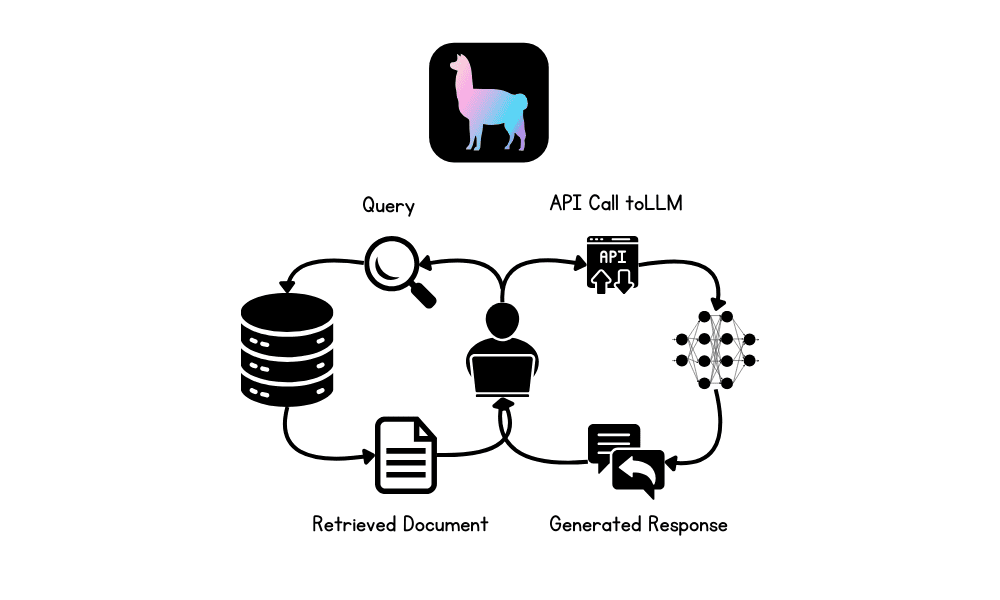
On this tutorial, we are going to discover Retrieval-Augmented Technology (RAG) and the LlamaIndex AI framework. We’ll learn to use LlamaIndex to construct a RAG-based utility for Q&A over the personal paperwork and improve the appliance by incorporating a reminiscence buffer. This can allow the LLM to generate the response utilizing the context from each the doc and former interactions.
What’s RAG in LLMs?
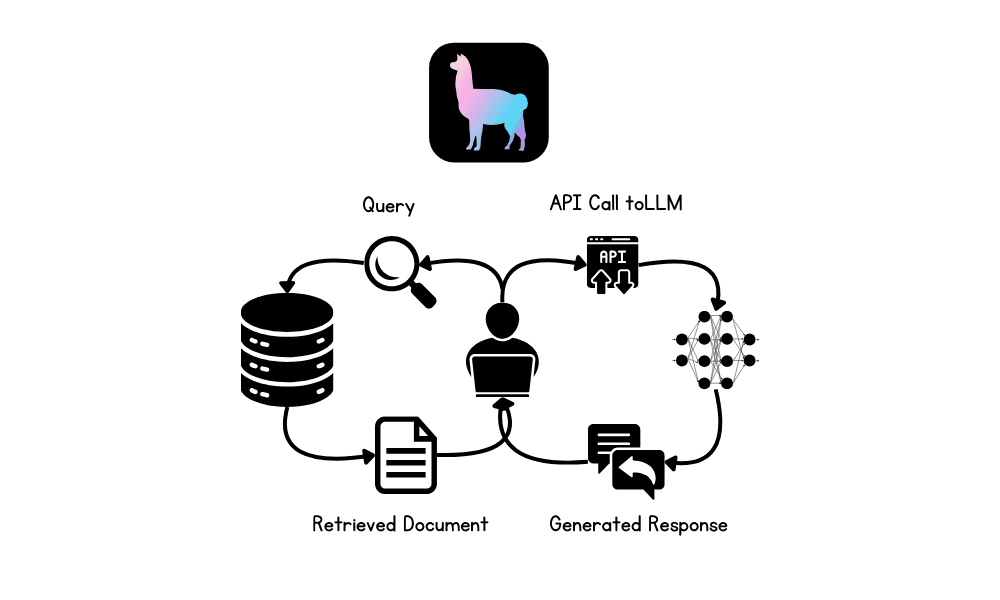
Retrieval-Augmented Technology (RAG) is a sophisticated methodology designed to boost the efficiency of huge language fashions (LLMs) by integrating exterior data sources into the technology course of.
RAG includes two principal phases: retrieval and content material technology. Initially, related paperwork or information are retrieved from exterior databases, that are then used to supply context for the LLM, making certain that responses are based mostly on essentially the most present and domain-specific data out there.
What’s LlamaIndex?
LlamaIndex is a sophisticated AI framework that’s designed to boost the capabilities of huge language fashions (LLMs) by facilitating seamless integration with numerous information sources. It helps the retrieval of knowledge from over 160 totally different codecs, together with APIs, PDFs, and SQL databases, making it extremely versatile for constructing superior AI functions.
We are able to even construct a whole multimodal and multistep AI utility after which deploy it to a server to supply extremely correct, domain-specific responses. In comparison with different frameworks like LangChain, LlamaIndex affords a less complicated resolution with built-in capabilities tailor-made for numerous varieties of LLM functions.
Constructing RAG Functions utilizing LlamaIndex
On this part, we are going to construct an AI utility that masses Microsoft Phrase information from a folder, converts them into embeddings, indexes them into the vector retailer, and builds a easy question engine. After that, we are going to construct a correct RAG chatbot with historical past utilizing vector retailer as a retriever, LLM, and the reminiscence buffer.
Organising
Set up all the mandatory Python packages to load the information and for OpenAI API.
|
!pip set up llama–index !pip set up llama–index–embeddings–openai !pip set up llama–index–llms–openai !pip set up llama–index–readers–file !pip set up docx2txt |
Provoke LLM and embedding mannequin utilizing OpenAI capabilities. We’ll use the most recent “GPT-4o” and “text-embedding-3-small” fashions.
|
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding
# initialize the LLM llm = OpenAI(mannequin=“gpt-4o”)
# initialize the embedding embed_model = OpenAIEmbedding(mannequin=“text-embedding-3-small”) |
Set each LLM and embedding mannequin to international in order that once we invoke a operate that requires LLM or embeddings, it’s going to robotically use these settings.
|
from llama_index.core import Settings
# international settings Settings.llm = llm Settings.embed_model = embed_model |
Loading and Indexing the Paperwork
Load the information from the folder, convert it into the embedding, and retailer it into the vector retailer.
|
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# load paperwork information = SimpleDirectoryReader(input_dir=“/work/information/”,required_exts=[“.docx”]).load_data()
# indexing paperwork utilizing vector retailer index = VectorStoreIndex.from_documents(information) |
Constructing Question Engine
Please convert the vector retailer to a question engine and start asking questions concerning the paperwork. The paperwork encompass the blogs revealed in June on Machine Studying Mastery by the creator Abid Ali Awan.
|
from llama_index.core <b>import</b> VectorStoreIndex
# changing vector retailer to question engine query_engine = index.as_query_engine(similarity_top_k=3)
# producing question response response = query_engine.question(“What are the widespread themes of the blogs?”) print(response) |
And the reply is correct.
The widespread themes of the blogs are centered round enhancing data and expertise in machine studying. They deal with offering sources such as free books, platforms for collaboration, and datasets to assist people deepen their understanding of machine studying algorithms, collaborate successfully on initiatives, and acquire sensible expertise by way of real-world information. These sources are geared toward each newcomers and professionals seeking to construct a robust basis and advance their careers in the sector of machine studying.
Constructing RAG Utility with Reminiscence Buffer
The earlier app was easy; let’s create a extra superior chatbot with a historical past function.
We’ll construct the chatbot utilizing a retriever, a chat reminiscence buffer, and a GPT-4o mannequin.
Afterward, we are going to check our chatbot by asking questions on one of many weblog posts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from llama_index.core.reminiscence import ChatMemoryBuffer from llama_index.core.chat_engine import CondensePlusContextChatEngine
# creating chat reminiscence buffer reminiscence = ChatMemoryBuffer.from_defaults(token_limit=4500)
# creating chat engine chat_engine = CondensePlusContextChatEngine.from_defaults( index.as_retriever(), reminiscence=reminiscence, llm=llm )
# producing chat response response = chat_engine.chat( “What’s the one greatest course for mastering Reinforcement Studying?” ) print(str(response)) |
It’s extremely correct and to the purpose.
Primarily based on the supplied paperwork, the “Deep RL Course” by Hugging Face is extremely really useful for mastering Reinforcement Studying. This course is notably appropriate for newcomers and covers each the fundamentals and superior strategies of reinforcement studying. It consists of matters such as Q-learning, deep Q-learning, coverage gradients, ML brokers, actor-critic strategies, multi-agent methods, and superior matters like RLHF (Reinforcement Studying from Human Suggestions), Choice Transformers, and MineRL. The course is designed to be accomplished inside a month and affords sensible experimentation with fashions, methods to enhance scores, and a leaderboard to trace progress.
Let’s ask follow-up questions and perceive extra concerning the course.
|
response = chat_engine.chat( “Inform me extra concerning the course” ) print(str(response)) |
In case you are having bother working the above code, please confer with the Deepnote Pocket book: Building RAG Application using LlamaIndex.
Conclusion
Constructing and deploying AI functions has been made simple by LlamaIndex. You simply have to write down a number of strains of code and that’s it.
The following step in your studying journey shall be to construct a correct Chatbot utility utilizing Gradio and deploy it on the server. To simplify your life much more, you may also try Llama Cloud.
On this tutorial, we discovered about LlamaIndex and the right way to construct an RAG utility that allows you to ask questions out of your personal documentation. Then, we constructed a correct RAG chatbot that generates responses utilizing personal paperwork and former chat interactions.
Get Began on The Newbie’s Information to Knowledge Science!

Be taught the mindset to grow to be profitable in information science initiatives
…utilizing solely minimal math and statistics, purchase your talent by way of quick examples in Python
Uncover how in my new E-book:
The Beginner’s Guide to Data Science
It gives self-study tutorials with all working code in Python to show you from a novice to an skilled. It exhibits you the right way to discover outliers, verify the normality of knowledge, discover correlated options, deal with skewness, verify hypotheses, and rather more…all to assist you in making a narrative from a dataset.