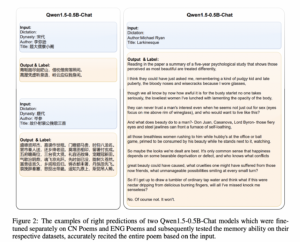
Idefics3-8B-Llama3 Launched: An Open Multimodal Mannequin that Accepts Arbitrary Sequences of Picture and Textual content Inputs and Produces Textual content Outputs
Machine studying fashions integrating textual content and pictures have change into pivotal in advancing capabilities throughout varied functions. These multimodal fashions are designed to course of and perceive mixed textual and visible knowledge, which reinforces duties reminiscent of answering questions on photographs, producing descriptions, or creating content material based mostly on a number of photographs. They’re essential for enhancing doc comprehension and visible reasoning, particularly in advanced eventualities involving numerous knowledge codecs.
The core problem in multimodal doc processing includes dealing with and integrating giant volumes of textual content and picture knowledge to ship correct and environment friendly outcomes. Conventional fashions typically need assistance with latency and accuracy when managing these advanced knowledge sorts concurrently. This may result in suboptimal efficiency in real-time functions the place fast and exact responses are important.
Present methods for processing multimodal inputs typically contain separate analyses of textual content and pictures, adopted by a fusion of the outcomes. These strategies might be resource-intensive and should solely typically yield the perfect outcomes because of the intricate nature of mixing totally different knowledge varieties. Fashions reminiscent of Apache Kafka and Apache Flink are used for managing knowledge streams, however they typically require intensive assets and may change into unwieldy for large-scale functions.
To beat these limitations, HuggingFace Researchers have developed Idefics3-8B-Llama3, a cutting-edge multimodal mannequin designed for enhanced doc query answering. This mannequin integrates the SigLip imaginative and prescient spine with the Llama 3.1 textual content spine, supporting textual content and picture inputs with as much as 10,000 context tokens. The mannequin, licensed below Apache 2.0, represents a major development over earlier variations by combining improved doc QA capabilities with a strong multimodal strategy.
Idefics3-8B-Llama3 makes use of a novel structure that successfully merges textual and visible data to generate correct textual content outputs. The mannequin’s 8.5 billion parameters allow it to deal with numerous inputs, together with advanced paperwork that function textual content and pictures. The enhancements embrace higher dealing with of visible tokens by encoding photographs into 169 visible tokens and incorporating prolonged fine-tuning datasets like Docmatix. This strategy goals to refine doc understanding and enhance total efficiency in multimodal duties.
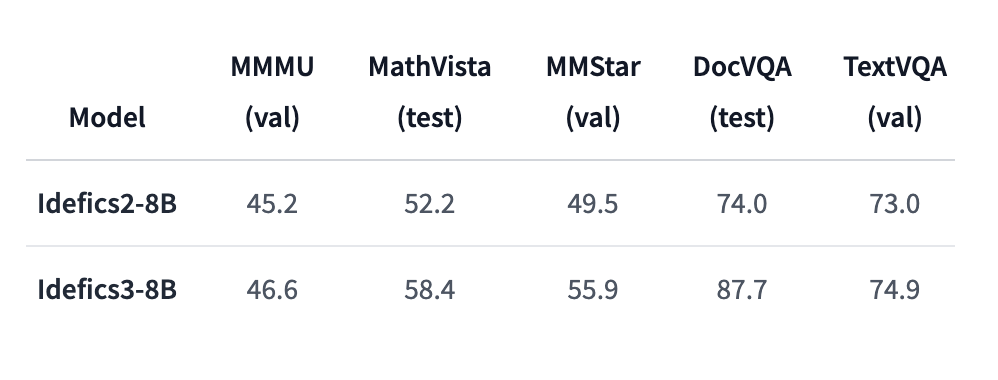
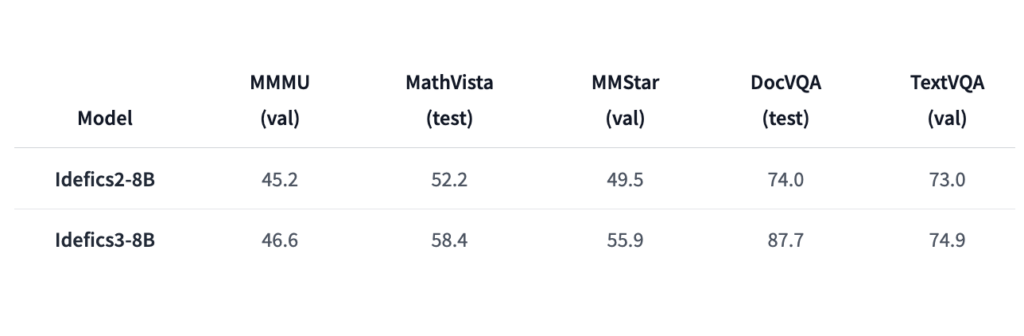
Efficiency evaluations present that Idefics3-8B-Llama3 marks a considerable enchancment over its predecessors. The mannequin achieves a exceptional 87.7% accuracy in DocVQA and a 55.9% rating in MMStar, in comparison with Idefics2’s 49.5% in DocVQA and 45.2% in MMMU. These outcomes point out important enhancements in dealing with document-based queries and visible reasoning. The brand new mannequin’s potential to handle as much as 10,000 tokens of context and its integration with superior applied sciences contribute to those efficiency features.
In conclusion, Idefics3-8B-Llama3 represents a serious development in multimodal doc processing. By addressing earlier limitations and delivering improved accuracy and effectivity, this mannequin offers a priceless instrument for functions requiring subtle textual content and picture knowledge integration. The doc QA and visible reasoning enhancements underscore its potential for a lot of use instances, making it a major step ahead within the area.
Try the Model. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars here
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.