Entry management for vector shops utilizing metadata filtering with Information Bases for Amazon Bedrock
In November 2023, we announced Knowledge Bases for Amazon Bedrock as typically accessible.
Information bases permit Amazon Bedrock customers to unlock the total potential of Retrieval Augmented Era (RAG) by seamlessly integrating their firm information into the language mannequin’s era course of. This function permits organizations to harness the facility of enormous language fashions (LLMs) whereas ensuring that the generated responses are tailor-made to their particular area information, laws, and enterprise necessities. By incorporating their distinctive information sources, similar to inside documentation, product catalogs, or transcribed media, organizations can improve the relevance, accuracy, and contextual consciousness of the language mannequin’s outputs.
Information bases successfully bridge the hole between the broad information encapsulated inside basis fashions and the specialised, domain-specific info that companies possess, enabling a very custom-made and priceless generative synthetic intelligence (AI) expertise.
With metadata filtering now accessible in Information Bases for Amazon Bedrock, you’ll be able to outline and use metadata fields to filter the supply information used for retrieving related context throughout RAG. For instance, in case your information accommodates paperwork from completely different merchandise, departments, or time durations, you should utilize metadata filtering to restrict retrieval to solely essentially the most related subset of information for a given question or dialog. This helps enhance the relevance and high quality of retrieved context whereas lowering potential hallucinations or noise from irrelevant information. Metadata filtering offers you extra management over the RAG course of for higher outcomes tailor-made to your particular use case wants.
On this submit, we focus on how you can implement metadata filtering inside Information Bases for Amazon Bedrock by implementing entry management and making certain information privateness and safety in RAG functions.
Entry management with metadata filters
Metadata filtering in information bases permits entry management on your information. By defining metadata fields based mostly on attributes similar to person roles, departments, or information sensitivity ranges, you’ll be able to make sure that the retrieval solely fetches and makes use of info {that a} specific person or software is permitted to entry. This helps keep information privateness and safety, stopping delicate or restricted info from being inadvertently surfaced or utilized in generated responses. With this entry management functionality, you’ll be able to safely use retrieval throughout completely different person teams or eventualities whereas complying with firm particular information governance insurance policies and laws.
Throughout retrieval of contextually related chunks, metadata filters add a further layer of choice to these vectors which are returned to the LLM for response era. As well as, metadata filtering requires fewer computation assets, thereby bettering the general efficiency and lowering prices related to the search.
Let’s discover some sensible functions of metadata filtering in Information Bases for Amazon Bedrock. Listed below are a couple of examples and use circumstances throughout completely different domains:
- An organization makes use of a chatbot to assist HR personnel navigate worker recordsdata. There’s delicate info current within the paperwork and solely sure staff ought to be capable of have entry and converse with them. With metadata filters on entry IDs, a person can solely chat with paperwork which have metadata related to their entry ID. The entry ID related to their authentication when the chat is initiated will be handed as a filter.
- A business-to-business (B2B) platform is developed for corporations to permit their end-users to entry all their uploaded paperwork, search over them conversationally, and full varied duties utilizing these paperwork. To make sure that end-users can solely chat with their information, metadata filters on person entry tokens—similar to these obtained by way of an authentication service—can allow safe entry to their info. This gives prospects with peace of thoughts whereas sustaining compliance with varied information safety requirements.
- A piece group software has a conversational search function. Paperwork, kanbans, assembly recording transcripts, and different belongings will be searched extra intently and with extra granular management. The app makes use of a single sign-on (SSO) performance that permits them to entry company-wide assets and different companies and follows an organization’s information stage entry protocol. With metadata filters on work teams and a privilege stage (for instance Restricted, Normal, or Admin) derived from their SSO authentication, you’ll be able to implement information safety whereas personalizing the chat expertise to streamline a person’s work and collaboration with others.
Entry management with metadata filtering within the healthcare area
To reveal the access-control capabilities enabled by metadata filtering in information bases, let’s contemplate a use case the place a healthcare supplier has a information base that accommodates transcripts of conversations between docs and sufferers. On this state of affairs, it’s essential that every physician can solely entry transcripts from their very own affected person interactions throughout the search, and never have entry to transcripts from different docs’ affected person interactions.
By defining a metadata area for patient_id and associating every transcript with the corresponding affected person’s identifier, the healthcare supplier can implement entry management inside their search software. When a health care provider initiates a dialog, the information base can filter the vector retailer to retrieve context solely from transcripts the place the patient_id metadata matches both a particular affected person ID or the record of affected person IDs related to the authenticated physician. This manner, the generated responses will probably be augmented solely with info from that physician’s previous affected person interactions, sustaining affected person privateness and confidentiality.
This entry management strategy will be prolonged to different related metadata fields, similar to yr or division, additional refining the subset of information accessible to every person or software. By utilizing metadata filtering in information bases, the healthcare supplier can obtain compliance with information governance insurance policies and laws whereas enabling docs to have customized, contextually related conversations tailor-made to their particular affected person histories and desires.
Resolution overview
Let’s stroll by way of the high-level steps to implement entry management with Information Bases for Amazon Bedrock. The next GitHub repository gives a guided pocket book which you can observe to deploy this instance in your personal account.
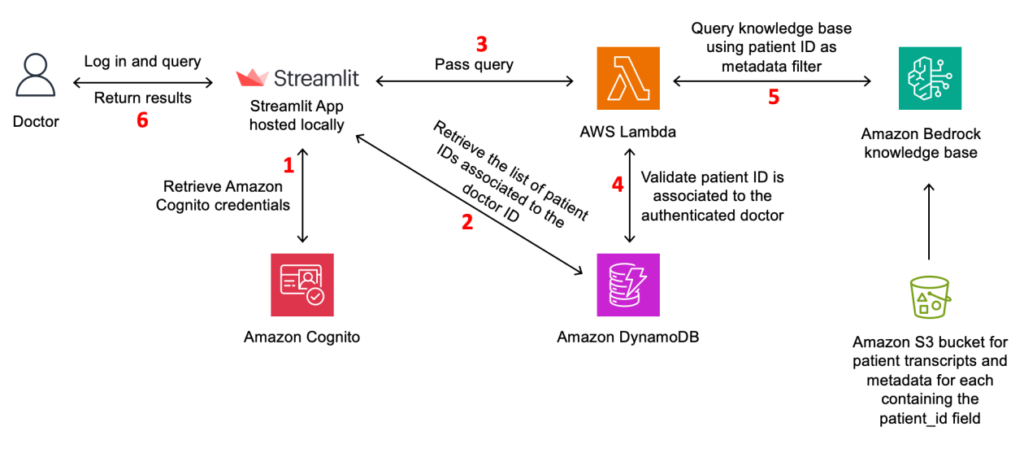
The next diagram illustrates the answer structure.

Determine 1: Resolution structure
The workflow for the answer is as follows:
- The physician interacts with the Streamlit frontend, which serves as the appliance interface. Amazon Cognito handles person authentication and entry management, making certain solely licensed docs can entry the appliance. For manufacturing use, it is suggested to make use of a extra strong frontend framework similar to AWS Amplify, which gives a complete set of instruments and companies for constructing scalable and safe internet functions.
- After the physician has efficiently signed in, the appliance retrieves the record of sufferers related to the physician’s ID from the Amazon DynamoDB database. The physician is then offered with this record of sufferers, from which they will choose a number of sufferers to filter their search.
- When the physician interacts with the Streamlit frontend, it sends a request to an AWS Lambda perform, which acts as the appliance backend. The request contains the physician’s ID, a listing of affected person IDs to filter by, and the textual content question.
- Earlier than querying the information base, the Lambda perform retrieves information from the DynamoDB database, which shops doctor-patient associations. This step validates that the physician is permitted to entry the requested affected person or record of affected person’s info.
- If the validation is profitable, the Lambda perform queries the information base utilizing the supplied affected person or record of affected person’s IDs. The information base is pre-populated with transcript and metadata recordsdata saved in Amazon Simple Storage Service (Amazon S3).
- The information base returns the related outcomes, that are then despatched again to the Streamlit software and exhibited to the physician.
Consumer authentication with Amazon Cognito
To implement the entry management answer for the healthcare supplier use case, you should utilize Amazon Cognito person swimming pools to handle the authentication and person identities of the docs.
To start out, you’ll create an Amazon Cognito person pool that can retailer the physician person accounts. In the course of the person pool setup, you outline the required attributes for every physician, together with their identify and a singular identifier (sub or customized attribute). For sufferers, their identifier will probably be used because the patient_id metadata area. This distinctive identifier will probably be related to every affected person’s account and used for metadata filtering within the information base retrieval course of.

Determine 2: Consumer info
Physician and affected person affiliation in DynamoDB
To facilitate the entry management mechanism based mostly on the doctor-patient relationship, the healthcare supplier can create a DynamoDB desk to retailer these associations. This desk will act as a centralized repository, permitting environment friendly retrieval of the affected person IDs related to every authenticated physician throughout the information base search course of. When a health care provider authenticates by way of Amazon Cognito, their distinctive identifier can be utilized to question the doctor_patient_list_associations desk and retrieve the record of patient_id values related to that physician.

Determine 3: Gadgets retrieved based mostly on the doctor_ID and affected person relationships
This strategy affords flexibility in managing doctor-patient associations. If a health care provider adjustments over time, solely the corresponding entries within the DynamoDB desk have to be up to date. This replace doesn’t require modifying the metadata recordsdata of the transcripts themselves.
Now that you’ve got your physician and sufferers arrange with their relationships outlined, let’s look at the dataset format required for efficient metadata filtering.
Dataset format
When working with Information Bases for Amazon Bedrock, the dataset format performs an important function in offering seamless integration and efficient metadata filtering. This instance makes use of a sequence of PDF recordsdata containing transcripts of doctor-patient conversations.
These recordsdata have to be uploaded to an S3 bucket for processing. To make use of metadata filtering, you should create a separate metadata JSON file for every transcript file. The metadata file ought to share the identical identify because the corresponding PDF file (together with the extension). As an illustration, if the transcript file is called transcript_001.pdf, the metadata file needs to be named transcript_001.pdf.metadata.json. This nomenclature is essential for the information base to establish the metadata for particular recordsdata throughout the ingestion course of.
The metadata JSON file will comprise key-value pairs representing the related metadata fields related to the transcript. Within the healthcare supplier use case, crucial metadata area is patient_id, which will probably be used to implement entry management. You assign every transcript to a particular affected person by together with their distinctive identifier from the Amazon Cognito person pool within the patient_id area of the metadata file, as within the following instance:
{"metadataAttributes": {"patient_id": 669}}
By structuring the dataset with transcript PDF recordsdata accompanied by their corresponding metadata JSON recordsdata, you’ll be able to successfully use the metadata filtering capabilities of Information Bases for Amazon Bedrock. This strategy lets you implement entry management, so every physician can solely retrieve and use content material from their very own affected person transcripts throughout the retrieval course of. For patrons processing hundreds of recordsdata, automating the era of the metadata recordsdata utilizing Lambda features or the same answer may very well be a extra environment friendly strategy to scale.
Information base creation
With the dataset correctly structured and arranged, now you can create the information base in Amazon Bedrock. The method is simple, due to the user-friendly interface and step-by-step steerage supplied by the AWS Management Console. See Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock for directions to create a brand new information base, add your dataset, and configure the required settings to realize optimum efficiency. Alternatively, you’ll be able to create a information base utilizing the AWS SDK, API, or AWS CloudFormation template, which gives programmatic and automatic methods to arrange and handle your information bases.

Determine 4: Utilizing the console to create a information base
After you create the information base and sync it along with your dataset, you’ll be able to instantly expertise the facility of metadata filtering.
Within the check pane, navigate to the settings part and find the filters choice. Right here, you’ll be able to outline particular filter circumstances by specifying the patient_id area together with the distinctive IDs or record of identifiers of the sufferers you want to check. By making use of this filter, the retrieval course of will fetch and incorporate solely the related context from transcripts related to the required affected person or sufferers. This filter-based retrieval strategy signifies that the generated responses are tailor-made to the physician’s particular person affected person interactions, sustaining information privateness and confidentiality.

Determine 5:Information Bases console check configuration Panel

Determine 6: Information Bases console check panel
Querying the information base programmatically
You’ve got seen how you can implement entry management with metadata filtering by way of the console, however what if you wish to combine information bases straight into your functions? AWS gives SDKs that can help you programmatically work together with Amazon Bedrock options, together with information bases.
The next code snippet demonstrates how you can name the retrieve_and_generate API utilizing the Boto3 library in Python. It contains metadata filtering capabilities inside the vectorSearchConfiguration, the place now you can add filter circumstances. For this particular use case, you first have to retrieve the record of patient_ids related to a health care provider from the DynamoDB desk. This lets you filter the search outcomes based mostly on the authenticated person’s id.
You possibly can create a Lambda perform that serves because the backend for the appliance. This Lambda perform makes use of the Boto3 library to work together with Amazon Bedrock, particularly to retrieve related info from the information base utilizing the retrieve_and_generate API.
Now that the architectural parts are in place, you’ll be able to create a visible interface to show the outcomes.
Streamlit pattern app
To showcase the interplay between docs and the information base, we developed a user-friendly internet software utilizing Streamlit, a well-liked open supply Python library for constructing interactive information apps. Streamlit gives a easy and intuitive strategy to create customized interfaces that may seamlessly combine with the varied AWS companies concerned on this answer.
The Streamlit software acts because the frontend for docs to provoke conversations and work together with the information base. It makes use of Amazon Cognito for person authentication, so solely licensed docs can entry the appliance and the corresponding affected person information. Upon profitable authentication, the appliance interacts with Lambda to deal with the RAG workflow utilizing the Amazon Cognito person ID.
Determine 7: Demo
Clear up
It’s essential to wash up and delete the assets created throughout this answer deployment to keep away from pointless prices. Within the supplied GitHub repository, you’ll discover a part on the finish of the pocket book devoted to deleting all of the assets created as a part of this answer to make sure that you don’t incur any ongoing fees for assets which are now not wanted.
Conclusion
This submit has demonstrated the highly effective capabilities of metadata filtering inside Information Bases for Amazon Bedrock by implementing entry management and making certain information privateness and safety in RAG functions. By utilizing metadata fields, organizations can exactly management the subset of information accessible to completely different customers or functions throughout the RAG course of whereas additionally bettering the relevancy and efficiency of the search.
Get began with Knowledge Bases for Amazon Bedrock, and tell us your ideas within the feedback part.
In regards to the Authors
 Dani Mitchell is an Generative AI Specialist Options Architect at Amazon Net Companies. He’s targeted on pc imaginative and prescient use circumstances and serving to prospects throughout EMEA speed up their ML journey.
Dani Mitchell is an Generative AI Specialist Options Architect at Amazon Net Companies. He’s targeted on pc imaginative and prescient use circumstances and serving to prospects throughout EMEA speed up their ML journey.
 Chris Pecora is a Generative AI Information Scientist at Amazon Net Companies. He’s obsessed with constructing modern merchandise and options whereas additionally targeted on customer-obsessed science. When not operating experiments and maintaining with the most recent developments in generative AI, he loves spending time together with his youngsters.
Chris Pecora is a Generative AI Information Scientist at Amazon Net Companies. He’s obsessed with constructing modern merchandise and options whereas additionally targeted on customer-obsessed science. When not operating experiments and maintaining with the most recent developments in generative AI, he loves spending time together with his youngsters.
 Kshitiz Agarwal is an Engineering Chief at Amazon Net Companies (AWS), the place he leads the event of Information Bases for Amazon Bedrock. With a decade of expertise at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing panorama. His ardour lies in partaking with prospects and understanding the modern methods they leverage AWS to drive their enterprise success. By means of his work, Kshitiz goals to contribute to the continual enchancment of AWS companies, enabling prospects to unlock the total potential of the cloud.
Kshitiz Agarwal is an Engineering Chief at Amazon Net Companies (AWS), the place he leads the event of Information Bases for Amazon Bedrock. With a decade of expertise at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing panorama. His ardour lies in partaking with prospects and understanding the modern methods they leverage AWS to drive their enterprise success. By means of his work, Kshitiz goals to contribute to the continual enchancment of AWS companies, enabling prospects to unlock the total potential of the cloud.