The Historical past of Convolutional Neural Networks for Picture Classification (1989 – Immediately) | by Avishek Biswas | Jun, 2024
A visible tour of the best improvements in Deep Studying and Laptop Imaginative and prescient.
Earlier than CNNs, the usual method to practice a neural community to categorise pictures was to flatten it into an inventory of pixels and cross it by a feed-forward neural community to output the picture’s class. The issue with flattening the picture is that the important spatial data within the picture is discarded.
In 1989, Yann LeCun and workforce launched Convolutional Neural Networks — the spine of Laptop Imaginative and prescient analysis for the final 15 years! In contrast to feedforward networks, CNNs protect the 2D nature of pictures and are able to processing data spatially!
On this article, we’re going to undergo the historical past of CNNs particularly for Picture Classification duties — ranging from these early analysis years within the 90’s to the golden period of the mid-2010s when lots of the most genius Deep Studying architectures ever have been conceived, and eventually focus on the most recent tendencies in CNN analysis now as they compete with consideration and vision-transformers.
Try the YouTube video that explains all of the ideas on this article visually with animations. Until in any other case specified, all the pictures and illustrations used on this article are generated on my own throughout creating the video model.

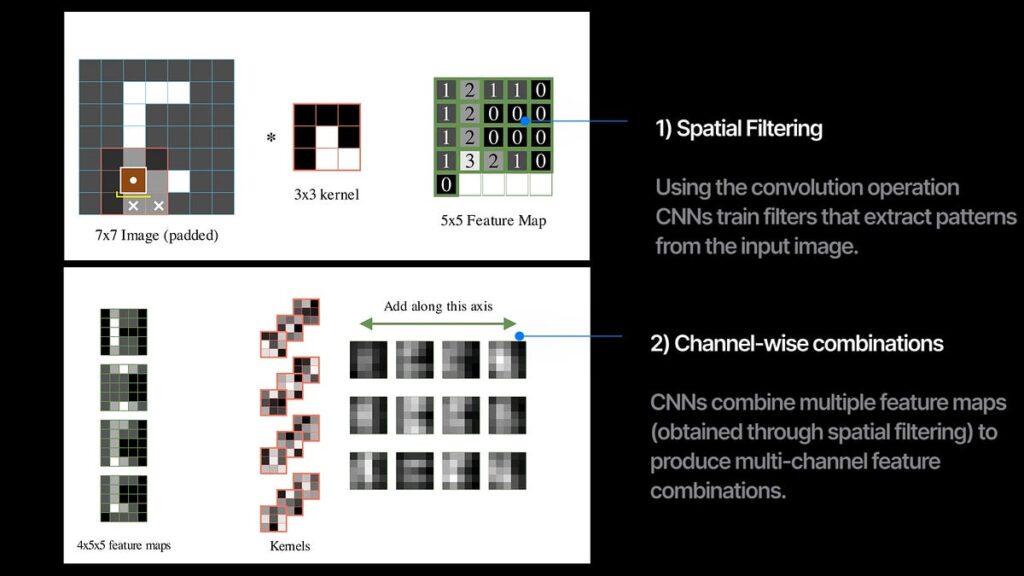
On the coronary heart of a CNN is the convolution operation. We scan the filter throughout the picture and calculate the dot product of the filter with the picture at every overlapping location. This ensuing output known as a characteristic map and it captures how a lot and the place the filter sample is current within the picture.

In a convolution layer, we practice a number of filters that extract totally different characteristic maps from the enter picture. After we stack a number of convolutional layers in sequence with some non-linearity, we get a convolutional neural community (CNN).
So every convolution layer concurrently does 2 issues —
1. spatial filtering with the convolution operation between pictures and kernels, and
2. combining the a number of enter channels and output a brand new set of channels.
90 % of the analysis in CNNs has been to change or to enhance simply these two issues.

The 1989 Paper
This 1989 paper taught us tips on how to practice non-linear CNNs from scratch utilizing backpropagation. They enter 16×16 grayscale pictures of handwritten digits, and cross by two convolutional layers with 12 filters of dimension 5×5. The filters additionally transfer with a stride of two throughout scanning. Strided-convolution is helpful for downsampling the enter picture. After the conv layers, the output maps are flattened and handed by two absolutely linked networks to output the chances for the ten digits. Utilizing the softmax cross-entropy loss, the community is optimized to foretell the proper labels for the handwritten digits. After every layer, the tanh nonlinearity can be used — permitting the discovered characteristic maps to be extra complicated and expressive. With simply 9760 parameters, this was a really small community in comparison with as we speak’s networks which comprise lots of of hundreds of thousands of parameters.

Inductive Bias
Inductive Bias is an idea in Machine Studying the place we intentionally introduce particular guidelines and limitations into the training course of to maneuver our fashions away from generalizations and steer extra towards options that comply with our human-like understanding.
When people classify pictures, we additionally do spatial filtering to search for frequent patterns to type a number of representations after which mix them collectively to type our predictions. The CNN structure is designed to copy simply that. In feedforward networks, every pixel is handled prefer it’s personal remoted characteristic as every neuron within the layers connects with all of the pixels — in CNNs there’s extra parameter-sharing as a result of the identical filter scans all the picture. Inductive biases make CNNs much less data-hungry too as a result of they get native sample recognition at no cost because of the community design however feedforward networks have to spend their coaching cycles studying about it from scratch.